Word count: ~3000 words
Estimated reading time: ~11 minutes
Last updated: September 7, 2025
Core Structure
- Three Curses: Revealing the mathematical, economic, and engineering principles limiting current AI Agents.
- Practical Pitfalls: Sharing real “big pits” I’ve stepped into while developing Agents.
- Correct Form: Defining AI Agents that can actually ship and profit in 2025 — “Super Tools.”
- Three-Layer Evaluation Model: Providing a professional framework directly usable by entrepreneurs and developers.
Introduction: Throwing Cold “Rational” Water on AI Agent Fever
Hey, I’m Mr. Guo. If you’ve been following tech circles lately, you’ve definitely been surrounded by AI Agent hype. Influencers shout that the “JARVIS era” is coming, startups are sprouting like mushrooms, everyone’s talking about how “general autonomous agents” will disrupt the world.
But as a deep AI practitioner and product consultant, I must throw some cold rational water on this fever: This path toward “all-purpose butler” is destined to hit a wall in 2025. This isn’t about technology strength but is determined by several unavoidable first principles — mathematical, economic, and engineering. This article’s purpose isn’t to be negative about AI. Quite the opposite — I hope to reveal the truth to help those of us truly wanting to build businesses with AI find the path that actually works and profits.
Chapter 1: The Mathematical Curse — “Error Compounding Effect” and the Illusion of Autonomy
Agent companies love showcasing simple 5-step tasks and cool results in product demos, but they’ll never tell you a devil in the details — the “error compounding effect.”
This is a simple but cruel math problem: Assume an Agent’s single-step accuracy is an impressive 95% (already quite optimistic for current large models). When it continuously executes a real workflow containing 20 steps, what’s the probability of successfully completing the entire task?
Answer: 0.95 to the 20th power ≈ 36%

This means you have nearly two-thirds probability of getting a failed result. No prompt engineering can violate basic mathematical laws. Now I ask you: Would you hire an employee with 64% probability of botching critical business? The answer is obvious.
I’ve personally stepped into this pit. I developed an “automated social media content distribution Agent” that worked perfectly during 5-step short-flow demos (topic selection -> copy generation -> image generation -> publish -> notify). But in actual 20-step long workflows (adding trend monitoring, multi-platform adaptation, comment sentiment analysis, auto-reply, etc.), failure rates were shockingly high. It ultimately became a “half-finished product” requiring constant babysitting — far worse than splitting it into several independent, reliable tools.
Strategic Conclusion: Abandon the obsession with “end-to-end full automation.” Reliable Agents must be designed with 3-5 independently verifiable short steps, with human checkpoints and confirmation mechanisms at critical junctures.
Chapter 2: The Economic Black Hole — “Quadratic Cost Curse” and Business Model Collapse
If mathematical problems determine Agent reliability, economic problems directly determine life or death. All Agents touting “long multi-turn conversations” hide a terrifying economic model — the “quadratic cost curse.”
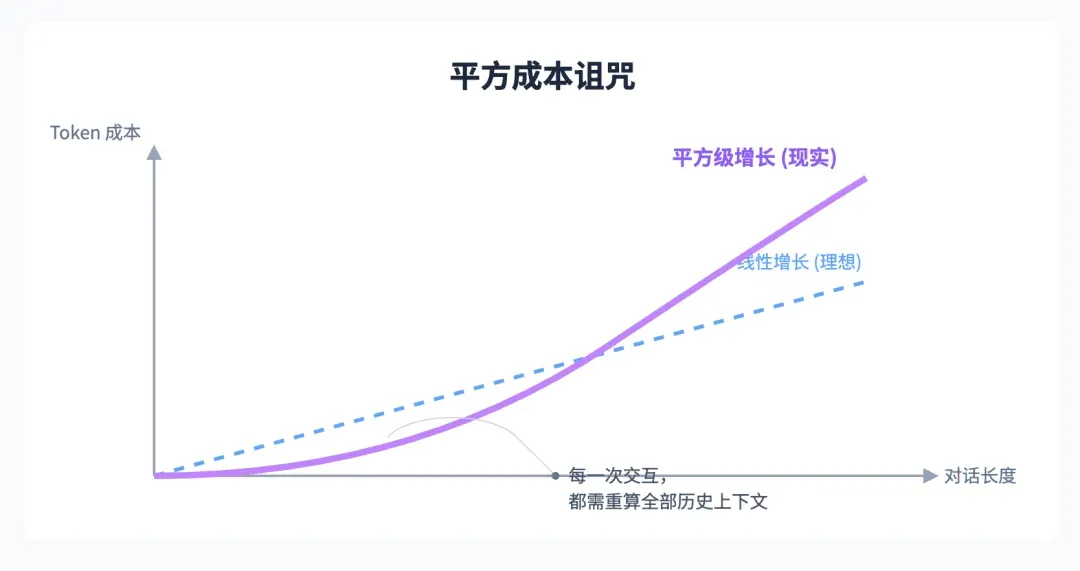
Think of it like boarding an astronomically expensive taxi: Every new stretch it drives, the meter not only calculates that new stretch’s fare but recalculates all historical routes’ fares again. Because to understand context, every Agent interaction must reprocess the entire conversation history.
So the longer the conversation, token costs don’t increase linearly but snowball in quadratic explosive growth. A seemingly ordinary 100-turn conversation could easily cost tens or even hundreds of dollars in API calls alone. This is why the most powerful AI coding tool Cursor has had to keep raising prices, and Claude Code recently started strictly limiting usage.
I was forced to abandon an early attempt at a “conversational BI data analysis Agent” due to cost issues. And recently using coding agents like Claude Code, the feeling is even more direct: For a very simple frontend project, one hour easily burns 10M+ tokens (including context cache). That’s just for a single Agent. If you use Sub Agents running parallel tasks for efficiency, token consumption instantly transforms from “water pipe” to “waterfall.” My $200 subscription, under this intensity, runs out in days. This business simply doesn’t work.
Strategic Conclusion: Prioritize designing “stateless” Agents. Let them be focused tool-people — one call, one high-quality output, then immediately “clock out.” No continuous context stacking means no business model collapse.
Chapter 3: The Engineering Truth — “Tools Are King” and AI’s 30% Value
Here’s an even more paradigm-shifting truth: In a successful Agent system, that brilliant AI brain might only complete 30% of the work.

What’s the other 70%? Those unglamorous, hard, tedious engineering tasks: designing tools AI can understand, building clear feedback mechanisms, handling failure rollback plans, managing context… This “tool system” is the real moat.
From a product consultant’s perspective, let’s deconstruct why Claude Code is so powerful. You can try this: even swapping its underlying model for another excellent open-source model, it still vastly outperforms competitors. Because its real barrier is that extremely complete tool system and engineering architecture custom-built for coding tasks. It knows how to decompose tasks, how to call file systems, how to execute tests, and has clear feedback loops designed at every step.
If you hear a company saying “our Agent can automatically connect APIs to handle everything,” they’re either bluffing or haven’t actually built it themselves.
Strategic Conclusion: Invest most of your energy in designing hard, tedious tools for AI. Think: On success, how do you give feedback with minimal tokens? On failure, how do you tell AI precisely where it went wrong? This is the core barrier to building usable Agents.
Chapter 4: Clearing the Fog — Three-Layer Evaluation Model for Building “Super Tools”
Based on constraints from these three principles, we can clearly define AI Agents’ only truly shippable form in 2025 — not “all-purpose butler,” but a series of “super assistant tools.” To build a successful “super tool,” we need a systematic evaluation framework. This framework originates from engineering philosophy my technical co-founder Tam summarized during top AI company interviews, which I’ve distilled into three core layers:
Layer 1: Resource Efficiency & Computational Economics
This is Agent’s survival foundation. An Agent exceeding computational budget or responding too slowly has zero production value. We must quantify: • Inference cost: Precisely calculate single-task token consumption; goal is minimizing cost while ensuring effectiveness. • Response latency: Focus on TTFT (time to first token) and end-to-end total time, ensuring smooth user experience. • Execution overhead: Analyze tool calling costs and efficiency. This directly corresponds to our previously mentioned “controllable cost” principle.
Layer 2: Task Effectiveness & Determinism
Having passed economic assessment, we can focus on core value: task completion quality. We must establish: • Task success rate: Quantify Agent reliability based on a “golden benchmark test set.” • Result quality: Automatically calculate hallucination rate and instruction-following precision, ensuring output usability. This corresponds to “clear boundaries” and “reliability > autonomy” principles. A tool with clear boundaries and predictable results far outweighs an occasionally dazzling but frequently out-of-control autonomous system.
Layer 3: System Robustness & Observability
An Agent that only runs under ideal conditions is fragile. As a production-grade system, it must have: • System robustness: Test whether it gracefully degrades rather than crashes outright when injected with abnormal inputs. • Observability: When behavior is abnormal, can we quickly locate the root cause through logs and traces? This layer directly relates to the “fault-tolerant design” principle, ensuring our Agent isn’t an unmaintainable “black box.” And the “hybrid architecture” concept runs throughout: use AI to handle ambiguity, use traditional code’s determinism to ensure system robustness and observability.
Conclusion: Forget JARVIS, Embrace Smarter “Hammers”
So, are AI Agents useless? No, quite the opposite. Their revolution will definitely come, but its form is definitely not the mythology from sci-fi movies.
You can forget that Agent that writes an entire book for you from start to finish — it’s unreliable. But a “writing assistant” that checks grammar, optimizes style, and provides citation suggestions can genuinely boost your efficiency 10x.
You can also forget that Agent that fully-automatically trades crypto for you — it might bankrupt you. But an “investment research assistant” that monitors markets 24/7, analyzes news sentiment, and alerts you the moment your preset conditions trigger could be priceless.
What we should build are those “super assistant tools” with strict boundaries, focused tasks, controllable costs, and humans retaining ultimate control. Let AI handle complexity; let humans maintain control. This is the form AI Agents can actually ship and help us make money in 2025 and the foreseeable short-term future.
If this splash of “cold water” gave you clearer perspective on AI Agents, drop a 👍 and share with more fellow explorers still in the gold rush.
🌌 The future doesn’t belong to AI believers, but to AI tamers.
