Digital Strategy Review | 2026
AI Under Security Review: Can AI Accidentally Harm People? | Uncle Fruit’s AI Daily
By Uncle Fruit · Reading Time / 8 Min

Foreword
For the past two years, our discussions on AI safety have primarily focused on “future existential risks” and “model alignment.” However, a more pressing issue has emerged this week: if AI is already integrated into high-stakes decision-making chains in the real world, then harm is not a future possibility—it is a present reality.
The flashpoint is a tragedy reported by multiple sources: an attack on an elementary school in Minab, southern Iran, resulted in the deaths of many schoolgirls. Subsequently, Gary Marcus cited a tweet by Tyler Austin Harper in an article, posing a sharp question: Could such misfires be related to AI-assisted targeting/decision-making systems?
I will state my conclusion upfront: the event itself is real and grave, and there is currently no public evidence that AI was involved. Yet, this news deserves front-page attention because it pushes the AI safety discussion toward a more “engineering-oriented” direction: when a system has the potential to cause irreversible harm, do you have the capability to trace, explain, hold accountable, and even gatekeep risks before an accident occurs?
01
Today’s Front-Page Highlights
Quick Summary
01 AI Under Security Review: Can AI Accidentally Harm People? (Emerging) A recent attack on an elementary school in Iran that killed many schoolgirls has triggered public questioning about whether AI is already involved in lethal decision-making in high-risk scenarios. Gary Marcus believes the link between the two remains unproven, but the question itself signifies that AI safety discussions are entering the realm of “real-world harm and accountability”: if AI is truly in the loop, can you prove what it did, who pressed “confirm,” and which mechanisms should have stopped it?
The Factual Layer: What We Can Confirm
Currently, only two points can be cross-verified from public information:
• The tragedy did occur: UNESCO and multiple media outlets reported that a girls’ elementary school in Minab, southern Iran, was bombed, resulting in at least 152 deaths. Credible sources (cross-verified): UNESCO statement, international media reports.
• The context of the incident is still unfolding: Key details such as attribution of responsibility, the strike chain, intelligence sources, and operational procedures have not been fully disclosed.
The Controversial Layer: Why We Must Be Cautious About AI Involvement
The core of Gary Marcus’s argument is not “I confirm AI caused the casualties,” but rather “we should start taking this possibility seriously and demand an auditable chain of evidence.” He cites Tyler Austin Harper’s tweet to pose a question to the public: if a misfire originates from an AI-assisted targeting system, do we have the capability to investigate it?
The impact of this statement lies in shifting the focus of the debate from “Can AI do it?” to “Does society have the capability to hold it accountable?” In many high-risk systems, the true black box is not the model parameters, but the organizational structure and recording mechanisms of the entire chain.
Why It Deserves Today’s Front Page
Because this is a “gear-shift indicator” for safety issues:
• Previously, we treated AI safety as a model problem (hallucinations, jailbreaks, alignment).
• Now, it is becoming a system problem (what data is collected, who approves, how thresholds are set, whether logs exist, whether post-incident reviews are possible, and how legal accountability works).
When the discussion reaches this level, AI safety is no longer a philosophical debate for researchers, but an engineering responsibility that anyone building high-risk automated systems cannot avoid.
02
Front-Page Interpretation: Why This Matters More
If we treat “AI potentially involved in a misfire” as a hypothesis, what we really need to study is not “whether the model has morals,” but “whether the system has brakes.”
I have broken this down into three layers so you can better understand the temporal value of this news.
1) Technical Layer: What Role Does AI Actually Play in the Chain?
When many people hear “AI involved in military decision-making,” they immediately jump to “fully autonomous killer robots.” In reality, “auxiliary systems” are more common:
• Target identification and classification (target suggestions based on image/radar/multi-source fusion)
• Risk assessment and prioritization (providing confidence levels, threat levels, recommended actions)
• Decision interfaces and prompts (compressing complex information into a single sentence, nudging humans to make a choice)
The problem with such systems is that even if a human clicks “confirm” at the end, AI can still influence human judgment under time pressure. This is not science fiction; it is an old problem in human-computer interaction: when a system appears “professional,” humans are more likely to outsource responsibility to it.
2) Organizational Layer: “Human-in-the-Loop” Is Often Just a Disclaimer
Many policy documents emphasize “retaining human judgment.” But in real-world decision-making scenarios, a different logic often prevails:
• Time windows are extremely short, and operators lack the conditions for a second, independent verification.
• Performance and incentives are biased toward “speed,” “accuracy,” and “fewer errors” rather than “slowing down.”
• The chain is broken down into multiple roles, and responsibility is diluted to the point of being untraceable.
Therefore, “human-in-the-loop” is not a toggle switch, but a comprehensive engineering design problem: how much time, information, and veto power do you give a human, and how does the system automatically decelerate when the AI is uncertain?
3) Accountability Layer: Systems Without Logs Are Inherently Ungovernable
The truly unsettling point of this news is: if AI was indeed in the chain, can we find out?
To find out, you need an “auditable chain of decision evidence,” which must include at least:
• Data side: What was the input at the time (sensors, intelligence, labeling sources, confidence intervals)
• Model side: Which model version was used, what were the thresholds, and were anomaly strategies triggered
• Human-machine side: What prompts were given to the operator via the interface, and what clicks/edits/confirmations did the operator perform
• System side: Who authorized, who approved, who held the final fire authority, and was the approval chain bypassed
There is a realistic reference here: the U.S. Department of Defense, in DoD Directive 3000.09 (Autonomy in Weapon Systems), emphasizes “maintaining appropriate levels of human judgment over the use of force” and includes “minimizing the probability and consequences of failures leading to unintended engagements” as a policy goal. You will find that the document discusses almost entirely “systems engineering” and “chains of responsibility,” not model parameters. This is the gear shift I mentioned: AI safety is being forced into an engineering paradigm that is auditable, accountable, and reviewable.
The same direction is appearing in international humanitarian and arms control discussions. The ICRC has long advocated for establishing rules and restrictions for autonomous weapon systems, and the core is simple: the more a system is capable of causing irreversible harm, the more it requires clear human control and accountability mechanisms.
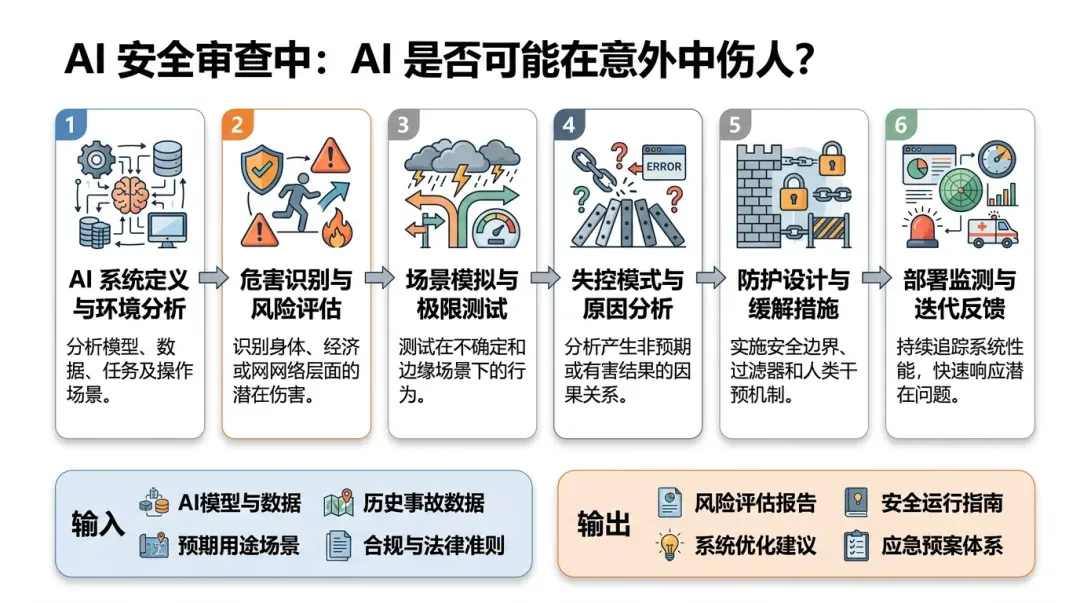
Flowchart used to explain the methodology execution path.
03
Uncle Fruit’s Perspective
I am less concerned with “whether this specific incident was caused by AI” and more concerned with whether we have the capability to clearly explain the problem the next time a similar event occurs.
If you are building any high-risk automated system—whether in defense, healthcare, finance, or industrial control—I suggest you do three things immediately. They may seem “slow,” but they are essentially installing brakes on your system.
1) Treat “Accident Investigability” as a Top-Tier Requirement
Many teams’ logging systems are designed for troubleshooting bugs and optimizing performance. But logs for high-risk systems must satisfy another goal: allowing external audits to reconstruct the facts after an accident.
At a minimum, you must achieve:
• Traceability of key inputs (source, time, integrity verification)
• Traceability of model versions and parameters (training data version, thresholds, strategies)
• Traceability of human-machine interaction (prompts, operations, confirmation, cancellation)
Without these, don’t talk about “responsible AI,” because you cannot even locate where the responsibility lies.
2) Design Clear Deceleration Mechanisms for “Uncertainty”
The biggest risk of AI is not that “it is always wrong,” but that “it is occasionally so right that people get used to trusting it.”
A more effective engineering approach is to force deceleration and escalation when the system is uncertain:
• When confidence is low or evidence conflicts, secondary confirmation must be triggered (dual approval, dual-source verification).
• When an anomaly is triggered, the system should default to a more conservative strategy rather than continuing to push forward.
• Give operators real veto power: opposition is recorded and accountable, and so is support.
3) Write “Human-in-the-Loop” into Executable Policy, Not Just a Slogan
A truly executable “human-in-the-loop” must answer at least four questions:
• Who is the ultimate person responsible (not just a job title, but specific duties)?
• At what point does the human intervene (the later the intervention, the more it becomes a mere formality)?
• How much power does the human have to veto (can they truly stop the system from advancing)?
• How is the post-incident review and accountability handled (is the process independent and transparent)?
If your system cannot answer these four questions, its “safety commitment” is likely just PR copy.
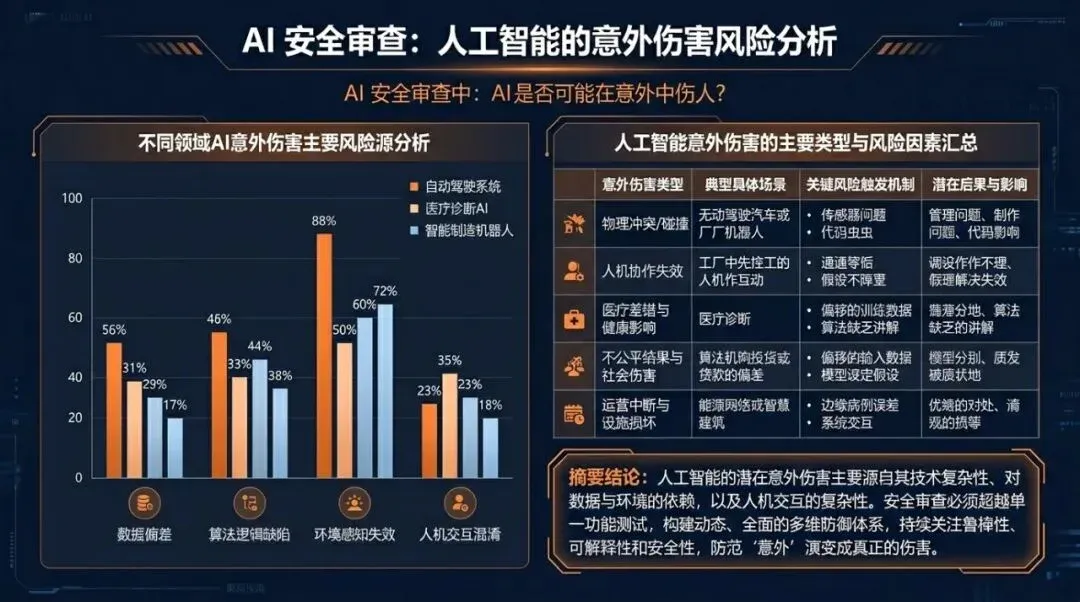
Data chart used to explain key comparisons and conclusions.
04
Other Key News Highlights
1) “Expert Beginners” and “Lone Wolves” Will Be More Common in the Early LLM Era
Jeff Geerling offers a realistic observation: LLMs allow more people to “get things done,” but they also amplify inexperienced decision-making, especially in personal projects and small teams lacking review mechanisms. Key takeaway: AI tools will expand technical governance from “code quality” to “decision quality,” and organizations will need new review processes and defensive designs.
Source: https://www.jeffgeerling.com/blog/2026/expert-beginners-and-lone-wolves-dominate-llm-era/
2) Claude Provides “Import Memory” Capability; AI Memory Becomes Portable
Simon Willison documents claude.com/import-memory: users can export “memories/context” stored by the system from past conversations and migrate them to other services. Key takeaway: This turns “memory” from a black-box capability into a product feature, leading to new competition in format standards, privacy compliance, and cross-platform migration.
Source: https://simonwillison.net/2026/Mar/1/claude-import-memory/
3) Antirez Releases Redis Documentation for LLMs/Agents
Redis creator Antirez has launched documentation specifically for LLMs and coding agents, emphasizing production-environment patterns and reusable implementations. Key takeaway: “Memory/session/caching” for AI applications will increasingly become an infrastructure problem, and mature components like Redis may become the default foundation.
Source: http://antirez.com/news/161
4) DHS Data Breach Sparks Renewed Discussion on Sensitive Data Protection
Micah Lee’s article explores the attack motives and system exposure surrounding the DHS-related intrusion. Key takeaway: As AI products integrate large amounts of enterprise data, security boundaries will be redefined by prompts, plugins, and automated workflows; traditional security systems need to patch the governance of “AI entry points.”
Source: https://micahflee.com/why-hack-the-dhs-i-can-think-of-a-couple-pretti-good-reasons/
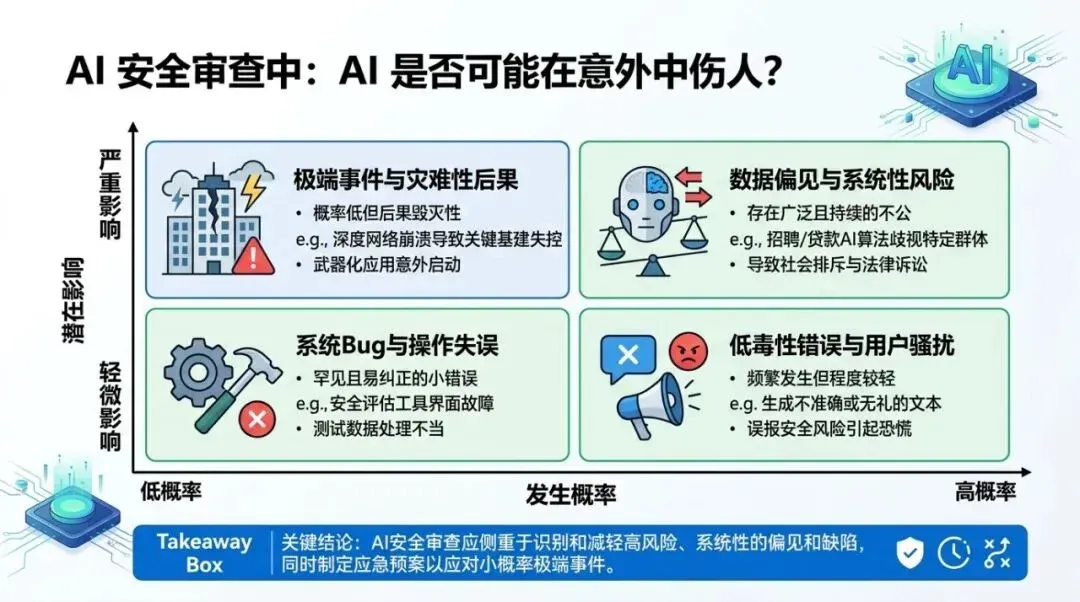
Matrix chart used to illustrate applicability boundaries and strategy selection.
05
Trends and Opportunities
1) AI Safety Will Shift from “Model Alignment” to “System Auditability”
For the foreseeable future, the most valuable safety capability may not be stronger refusal mechanisms, but a stronger chain of evidence: inputs, outputs, thresholds, versions, and responsible parties—everything must be reviewable. Systems that cannot achieve this will struggle to gain long-term trust in high-risk scenarios.
2) “AI Incident Response” Will Become a New Engineering Role and Product Category
Just as cloud-native computing gave rise to SRE, the large-scale integration of AI into business operations will give rise to AI Incident Response: monitoring prompt risks, identifying anomalous outputs, tracking data lineage, and reviewing decision chains. The corresponding toolchain will be a new market.
3) Rules Will Be Implemented Faster Than Technology; Those Who Prepare Early Will Avoid Pitfalls
When public opinion begins to ask “Has AI already caused real-world harm?”, regulatory and industry rules will accelerate. Teams that have already solidified their logging, auditing, review, and authorization chains will face much lower barriers to compliance and cooperation in the future.

