If You Have AI Tokens to Burn, How Should You Squander Them? (Part 1) — How to Consume 5–10x More Tokens While Writing an Article! (Codex Optimization - Keeping the Original Flavor)
Digital Strategy Review | 2026
By Mr. Guo · Reading Time / 8 Min
Foreword
Foreword: If you are like me—subscribed to a pile of AI tools like Claude Max and GPT Pro, firmly believing they bring massive value, yet limited by time and energy, and always feeling like you’re losing money if you don’t use them up—then this post is for you. I’m going to share how I usually “squander” my tokens.
I’ve made a video for this article, so if you don’t feel like reading, feel free to watch the video instead.

01
First, My AI Subscription Setup: The Trifecta of Claude Max + Gemini + GPT
Currently, I subscribe to: Claude Max ($200/mo) + Gemini ($20/mo) + GPT ($20/mo). Here is why I buy them this way:
-
01
Claude Code (CC) is currently on par with Codex for programming, but Codex doesn’t speak “human.” As someone without a professional IT background, the emotional value provided by CC is very important, so I use CC extensively for development.
-
02
I subscribe to GPT for two reasons. First, the ChatGPT app + Atlas browser is, in my opinion, the best AI assistant experience available today—bar none. The speed, quality, and search accuracy are all top-tier (I’ve compared it to Perplexity and others), and the hallucination rate is low. Second, there is Codex. Its greatest advantage is its extremely low hallucination rate and superior instruction-following capability. While it lacks “emotional value,” it is accurate, works strictly according to outlines and requirements, and doesn’t overstep or cut corners.
-
03
The core of Gemini 3.0 is its multimodal capability and aesthetic sense in frontend design. Currently, Gemini is T0 in multimodality; the ability to directly analyze video content is crucial for my operations work. Additionally, Nanobanana Pro’s image generation is T0-level, capable of producing presentation-ready visuals directly. In fact, I often use Vertex to call Nanobanana for higher efficiency. One more thing: Gemini is also very strong at human-like writing. Personally, I feel it sometimes rivals Claude, though it does have more hallucinations and requires human intervention.
In reality, even if I worked 20 hours a day, it would be difficult to burn through all the tokens or quotas of these accounts.
02
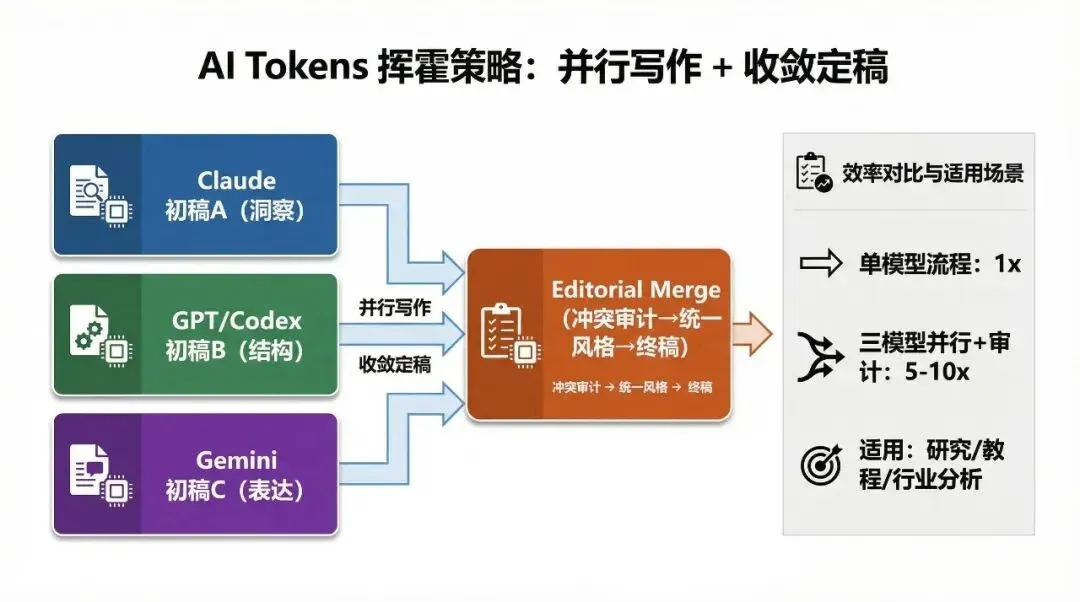
The First Way to Burn Tokens: Have Three Models Do the Same Task, Then Converge for Quality
I know what you might ask: Isn’t this similar to Claude Code’s “Swarm” mode?
Actually, yes and no.
Swarm mode involves one large model leading a bunch of small models, and the results are often hyper-divergent. If you ask it to perform convergence tasks, the result can be disastrous. Claude itself is a model with high divergence, and adding small models into the mix only increases that level.
However, if you have three powerful models do the same thing, and the final deliverable is a single entity, it becomes a process of “diverge first, converge later.” Therefore, for my specific task, I explicitly reject CC’s Swarm mode.
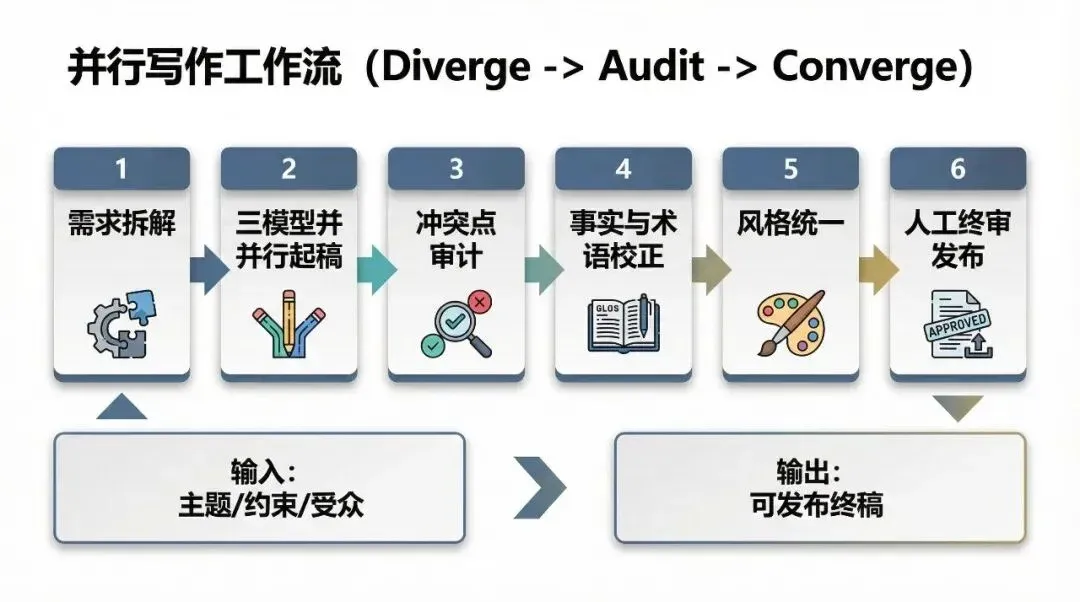
Parallel drafting is just the starting point; the core lies in conflict auditing and convergence finalization.
03
Practical Case: I Let Codex Act as the “Referee + Editor-in-Chief”
I recently had a massive batch of copywriting tasks, so I had three models write articles in parallel under the same directory framework.
The problem followed: If every piece had to be manually reviewed, refined, and optimized, the workload would be terrifying.
So, I decided to let the “most rational, obedient, and strict” model of the three—Codex—act as the referee.
I created a “Skill” designed to make Codex simulate the workflow and thinking process of a professional human editor handling multi-draft consolidation, and then had Codex replicate it.
My Skills.md is as follows. If you find it useful, feel free to copy it directly: (I pasted this directly into the AI; it’s not meant for human reading, so don’t mind the formatting.)
[Frontmatter] name: editorial-merge description: Professional multi-draft book editing workflow to evaluate three drafts, build a master outline, assemble one unified manuscript, enforce a style guide, and produce change logs plus verification TODOs. Includes mandatory contradiction detection, evidence-based conflict resolution, and explicit conflict reporting. [/Frontmatter] # Editorial Merge You are a senior publishing editor (developmental + line editor). Merge multiple manuscript drafts into one coherent master manuscript. ## Inputs You May Receive - `DRAFT_A`: Version A manuscript (may be partial chapters) - `DRAFT_B`: Version B manuscript - `DRAFT_C`: Version C manuscript - `EDITOR_BRIEF` (optional): 1-page editorial brief with target reader, promise, tone, scope, constraints - `SCOPE` (optional JSON): { "book_title": "", "audience": "", "tone": "", "must_keep": [], "must_remove": [], "chapter_range": "all | 1-3 | 5 | ...", "language": "zh | en | ...", "output_format": "markdown" } If `EDITOR_BRIEF` is missing, infer it from drafts and state assumptions in a short Assumptions section. ## Non-Negotiable Principles 1. Structure before prose: do not polish sentences until a master outline is agreed. 2. Evidence and accuracy: flag claims that need verification; never fabricate sources. 3. No silent rewrites: record every major change in the change log. 4. Preserve best blocks: keep strongest blocks across drafts; remove redundancy. 5. Unify voice: enforce one tone, terminology set, and formatting style guide. 6. Conflict-first editing: detect cross-draft contradictions early; do not merge conflicting claims without explicit resolution or TODO. ## Workflow (Do In Order, Do Not Skip) ### Step 1 - Normalize and Segment - Split each draft into `chapters -> sections -> blocks`. - Use block tags when possible: `Hook / Definition / Framework / Steps / Examples / Pitfalls / Summary / Exercises`. - Build a Chapter Map aligning comparable sections across drafts. ### Step 2 - Chapter Evaluation Matrix For each chapter (or requested range), score each draft (1-5): - Clarity of structure - Information density and pacing - Accuracy and rigor - Actionability - Readability - Tone consistency Output a compact table per chapter and name the `Best Skeleton Draft` (structure winner). ### Step 3 - Conflict Detection and Resolution Plan (Mandatory) Build a chapter-level `CONFLICT_REPORT` before drafting merged prose: - Detect contradiction types: - Command/API mismatches - Version/platform mismatches - Numeric/time/date inconsistencies - Scope mismatches against outline/brief - Terminology collisions (same term, different meaning) - For each conflict, record: - `conflict_id` - location(s) in A/B/C - competing claims - risk level (`high|medium|low`) - verification source (`code|official docs|none`) - resolution action (`keep A|keep B|keep C|rewrite|mark TODO`) - If evidence is insufficient, mark `TODO` instead of guessing. ### Step 4 - Master Outline and Assembly Blueprint Produce: - `MASTER_OUTLINE`: chapter list + each chapter goal + required sections - `ASSEMBLY_BLUEPRINT`: for each section/block specify: - source: `A / B / C / rewrite` - rationale (one line) - missing gaps (examples, transitions, definitions, visuals) - conflict linkage: include `conflict_id` when the block resolves a known conflict ### Step 5 - Assemble Unified Manuscript V1 - Assemble one manuscript using `MASTER_OUTLINE` + `ASSEMBLY_BLUEPRINT` + resolved conflicts. - Keep prose clean but not over-polished. - Keep chapter template consistent when suitable: - goal - body - summary - actionable checklist ### Step 6 - Style Guide and Terminology Unification Generate `STYLE_GUIDE` with: - Voice and tone rules (`do / don't`) - Terminology table (`preferred term / aliases to avoid / definition`) - Formatting rules (headings, lists, code blocks, callouts) Then revise V1 to V1.1 with style guide applied consistently. ### Step 7 - Fact-Check and Consistency TODOs Output: - `FACT_CHECK_TODO`: bullets with location pointers (`chapter/section`) and what to verify - `CONSISTENCY_TODO`: terminology drift, duplicated concepts, missing prerequisites ### Step 8 - Change Log Output `CHANGE_LOG` including: - Major structural changes (move/merge/delete) - Major content swaps (`A -> B` etc.) - New content added - Conflict resolutions applied (reference `conflict_id`) - Known open questions ## Output Format (Strict Order) 1. Assumptions (if any) 2. Chapter Map (high-level) 3. Evaluation Matrix (chapter-wise) 4. CONFLICT_REPORT 5. MASTER_OUTLINE 6. ASSEMBLY_BLUEPRINT 7. STYLE_GUIDE 8. Unified Manuscript (V1.1) in Markdown 9. FACT_CHECK_TODO 10. CONSISTENCY_TODO 11. CHANGE_LOG ## Guardrails - If drafts are huge, process chapter by chapter and still keep the same output structure. - Never lose user-specific terms or product names; normalize them in `STYLE_GUIDE`. - When uncertain, mark TODO instead of guessing. - Never claim a conflict is resolved unless the resolution is reflected in the merged manuscript. ## Trigger Examples - Merge these three book drafts into one master manuscript using editorial-merge. - Evaluate and merge Chapter 1-3 across three drafts; output outline, conflict report, blueprint, and unified V1.1. - Create a style guide, resolve contradictory statements across versions, and rewrite the merged manuscript accordingly.04
What Does This Skill Actually Solve?
Essentially, this skill solves the “convergence problem” when merging multiple pieces of content:
-
•
Resolves content conflicts, making them traceable and verifiable.
-
•
Controls content from spreading beyond the boundaries of the outline.
-
•
Unifies the expression style across multiple drafts.
-
•
Integrates the best parts from multiple drafts.
Furthermore, you get a traceable and analyzable record document, clearly showing where conflicts existed and what changes were made, making it easy for humans to perform the final review.
The increase in consumption comes from multiple rounds of parallel processing, review, and convergence, not from a single generation.
05
Why Does It Burn So Many Tokens?
The most important reason, of course, is that playing with this skill really burns a lot of tokens.
Having three models work on one piece of content means triple the input tokens + context occupancy, plus the merging, conflict auditing, resolution, and final output of the integrated manuscript. It is not an exaggeration for the consumption of a standard writing task to increase by 5–10 times.
Of course, these tokens aren’t burned for nothing; what you get is high-quality content that condenses the “collective wisdom” of three powerful models.
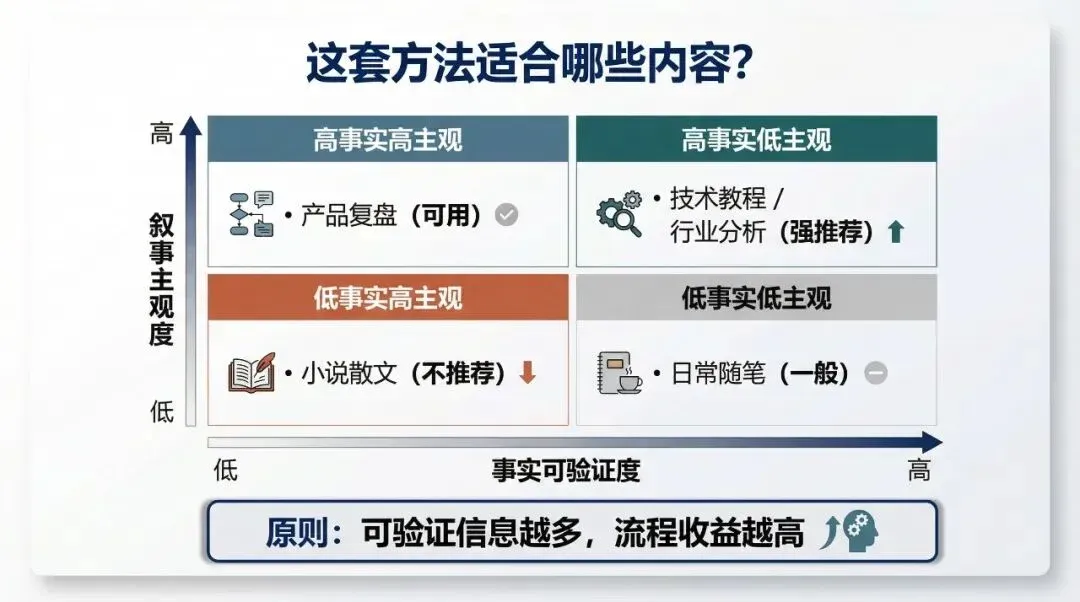
The higher the density of verifiable information, the more valuable this parallel convergence process becomes.
06
This Workflow Isn’t for Every Type of Copywriting
Currently, I still believe that this workflow and skill set are not suitable for all types of copywriting.
It is especially unsuitable for content where storytelling and human-like expression are dominant. It is better suited for objective content that is fact-heavy, technical, and professional.
07
Next Episode Preview
My second method for burning tokens is: I’ll tell you next time~ Haha.
That is the content for our next post.
That’s it for this issue. It’s been a while since I wrote this kind of purely execution-level content. Finally, let me briefly summarize the core philosophy of this method:
-
01
AI can also have collective wisdom, but it needs a reliable, obedient leader to coordinate.
-
02
For high-quality work, AI cannot completely replace humans, but it can significantly reduce the workload. The key is how you use it.
