Digital Strategy Review | 2026
I Honestly Advise You Not to Touch Unofficial APIs—Not Because I Haven’t Used Them, But Because I Used to Sell Them
By Uncle Guo · Reading Time / 8 Min

01
Why I Still Wanted to Write This
Publishing this article will inevitably step on some toes. There are plenty of people out there making a living off “mirror sites,” “shared account pools,” “low-cost tokens,” and “unofficial APIs,” and they will likely continue to exist for the foreseeable future. As long as the official barriers regarding network access, payment, account restrictions, and regional blocks remain, this business won’t just vanish. In fact, many will continue to find it quite appealing.
However, I want to be perfectly clear about this.
I sincerely advise you not to treat unofficial APIs as genuine production tools. If you’re just playing around, testing new models, or satisfying your curiosity, the risks might be manageable. But once you start connecting them to your code repositories, workflows, terminals, databases, or client data—or even granting them access to your server permissions—this is no longer just about “finding a cheap alternative.” Many people focus on the unit price of the API, thinking they are just saving a bit on call costs, but once you integrate it into your actual work, you are effectively putting much more valuable assets at risk.
And I’m not just someone shouting slogans from the sidelines.
I haven’t just seen this entire chain of operations; I actually participated in it myself back in the day. So, this isn’t a security manual or a moral lecture; it’s more of a cautionary tale from someone who has been there. You don’t have to agree, but I owe it to you to clearly explain the pitfalls.
02
Why This Business Always Has a Market
To be fair, I completely understand why domestic users buy these services. Often, people are driven to this by the official path itself. If you are behind the Great Firewall and want to use the latest models, even if you are eager to pay, they might not make it easy for you. Network blocks, payment blocks, account risk controls—there are many hidden hurdles between subscriptions and APIs. Sometimes it’s not that you think it’s too expensive; you just want to purchase the service normally, but the entire process is incredibly convoluted.
This was especially apparent when “Vibe Coding” first became popular. Many people realized that tools like Claude, Cursor, and Claude Code were no longer just toys for “chatting,” but tools that could actually handle work, save time, and boost development efficiency. Yet, just when you wanted to use them most, you’d find that the real barriers weren’t about prompts or coding skills, but about payments, networks, regions, and account systems. After being blocked, many naturally sought alternatives.
I went through the same thing. At one point, my payment channels were cut off, and I only managed to get it working by having family in the US help me get a secondary card. So, why would an average user be tempted by unofficial APIs? It’s perfectly normal. A market with genuine demand but poor official supply will inevitably sprout a gray-market layer. It looks like it’s solving your problem—and often it does, temporarily—but it usually brings along a much bigger problem in the process.
03
Why I’m Advising You Against It
Frankly, I jumped into this track myself back in the day.
When Claude Code first went viral, the barrier for domestic users was absurdly high, and demand was booming. At that time, things like “mirror sites,” “account pools,” and “unlimited refills” were very popular, and there was indeed a brief window for arbitrage. A high-priced subscription could be sliced up for many people; a service originally intended for a few could be packaged as a “low-cost alternative for everyone.” The demand was real, and the money was definitely there—at least on the surface.
But once these businesses started running, the nature of the game quickly changed. Whenever platform rules shifted, quotas were tightened, or ban waves hit, the entire chain began to warp. To keep the project running, some started building account pools, others created more complex intermediate routers, some mixed in other models, and some implemented various scheduling tricks hidden from the user. What you bought as “official source” might actually be a hodgepodge of temporary, cobbled-together products running in the background.
After doing this for a while, I quickly realized something was wrong. It still worked, but it became increasingly “dirty” and uncontrollable. Customer service costs, after-sales support, the cost of failures, and the cost of account bans all started to climb. In the end, it wasn’t about product capability anymore; it was about who could withstand the most risk, who could best cover up the problems, and who could keep the user in the dark after everything started to fall apart. Once it reached that point, I realized that even if this path could make money in the short term, it was hardly a sustainable business.
So, when I advise you not to use it today, it’s not because I haven’t touched it. It’s precisely because I have, and I know exactly where the dirtiest parts are hidden.

What you are actually outsourcing isn’t just model calls; it’s billing, data, security, and the boundaries of responsibility.
04
Cheapness Is Just the Poster at the Door
For many, the first thing they see with unofficial APIs is the price. The official price is too high, and the third-party price is absurdly low—so low it feels like charity. The ads claim “official source,” “stable and available,” and “buy with your eyes closed,” paired with an unreasonably high quota. It feels like finding money on the ground; it’s easy to be tempted.
If you look at those ads long enough, you should start to feel suspicious.
When I was selling these, even though I was relatively honest, I at least wrote down the actual token counts, admitted when caching wasn’t supported, and didn’t brag about things I couldn’t track. Even then, users were suspicious because once there is an intermediary, the user naturally cannot see the real costs or what is happening in the background. Not to mention that some sellers never intended for you to understand in the first place.
This is where the real trouble lies. Whether the model is the original, whether it secretly switches to another model during peak hours, whether the quota shown to you matches the real cost, how caching is calculated, and what rules are used for input/output deductions—the average user has no way to verify any of this. Some will mix models directly, some will play games with billing rules, and some will give you a nice-looking “dollar quota” while quietly cutting corners on the price per million input/output tokens. You might not be paying less; you just didn’t see how the bill was calculated when you bought it.
If you’re just playing around occasionally, you might be able to tolerate it. But once you connect your work to it, this lack of transparency is no longer a “small loss”—it means you no longer have any idea what you are actually using.
05
The Real Trouble Is What You’ve Handed Over
The above is just the surface. What makes me increasingly repulsed by these services is a more fatal issue. As long as there is an opaque proxy in the middle, theoretically, much of what you send is no longer a secret to the other party. Your prompts, your product documentation, your customer data, your server IP, your API Key, the code repositories you let the model review, the scripts and commands you let it generate—once these pass through an intermediary you don’t understand, it’s hard to pretend they still belong only to you.
Many people’s understanding of APIs is still stuck at “I send a request, the model returns a result.” But today, we aren’t using models just for idle chat. We are using them to write code, modify code, run agents, connect to terminals, read repositories, handle automation, process customer requirements, assist in operations, and even touch core business chains. At this stage, you aren’t just connecting to a chat interface; you are connecting to an entire execution chain. Who is the extra person in that chain? Are they reliable? Do they look at your data? Do they store it? Do they sell it? Will they just disappear one day? These are the truly terrifying questions.
I didn’t imagine this; I’ve fallen into these pits myself. When your server gets hacked for crypto-mining, you gain a concrete understanding of why “security is paramount.” You might think it’s just corporate jargon, but once you see your resources maxed out, services behaving abnormally, bills skyrocketing, and after hours of investigation, you realize the entry point was likely that “harmless” intermediary—you’ll understand that many “small savings” end up costing a fortune.
I increasingly believe that in the AI era, the most underestimated cost is never the call fee; it’s the accident fee.
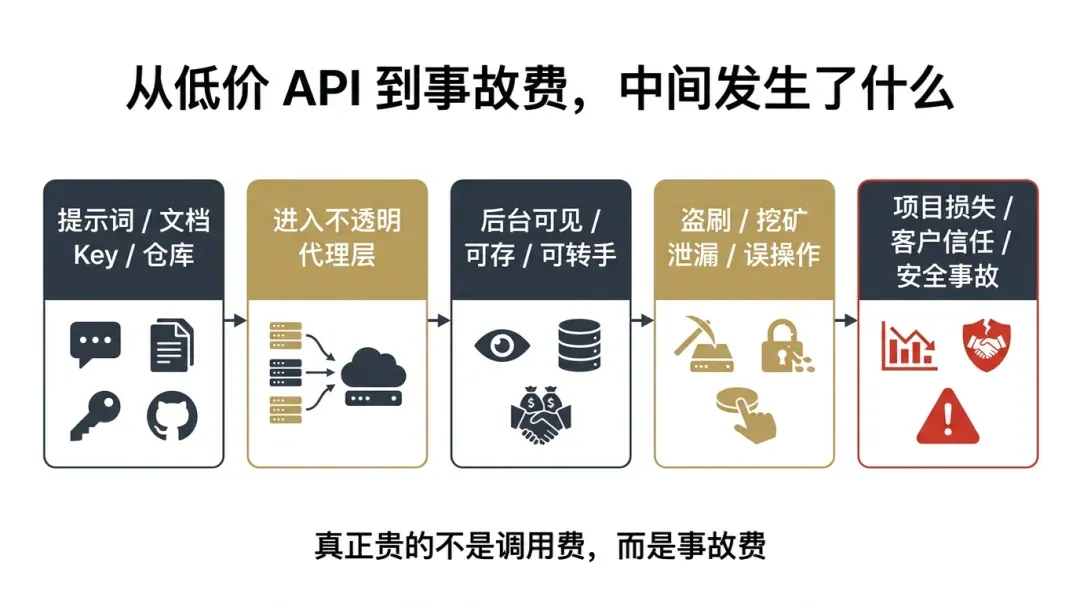
Once a model starts connecting to terminals, repositories, and workflows, the risk is no longer just “a slightly worse answer.”
06
Who Should Be Most Vigilant?
I’m not saying that if you connect to a proxy today, you will definitely be hacked, have your database deleted, or face a catastrophe tomorrow. The world isn’t that linear; many people use them for a long time without incident, and many sellers don’t necessarily start with malicious intent. But the structure of this setup makes it unworthy of risking anything truly important. It might be fine 99 times, but the 100th time it fails, the loss won’t be calculated by the API unit price; it will be calculated in terms of projects, clients, data, and trust.
Independent developers are the most vulnerable. You look like you’re traveling light, but in reality, you have no buffer—no dedicated security team, no legal safety net, and no complex disaster recovery mechanism. A single accident can be devastating. Small teams handling outsourcing and client projects are in the same boat; you aren’t just losing your own data, but the trust your clients placed in you. As for those who have deeply integrated Claude Code, Cursor, and Agent workflows into their production environments, I would offer a more cautious warning: the biggest fear in these scenarios is never the model being occasionally stupid; it’s your efficiency tool suddenly becoming an accident amplifier.
I also want to address a specific group: those who hold server permissions, database access, payment information, or other high-value resources, but always think, “Nobody would care about my little stuff.” This thought is very common and very dangerous. Often, people aren’t looking at how big your plate is; they are looking for holes, permissions, or anything they can easily walk away with.
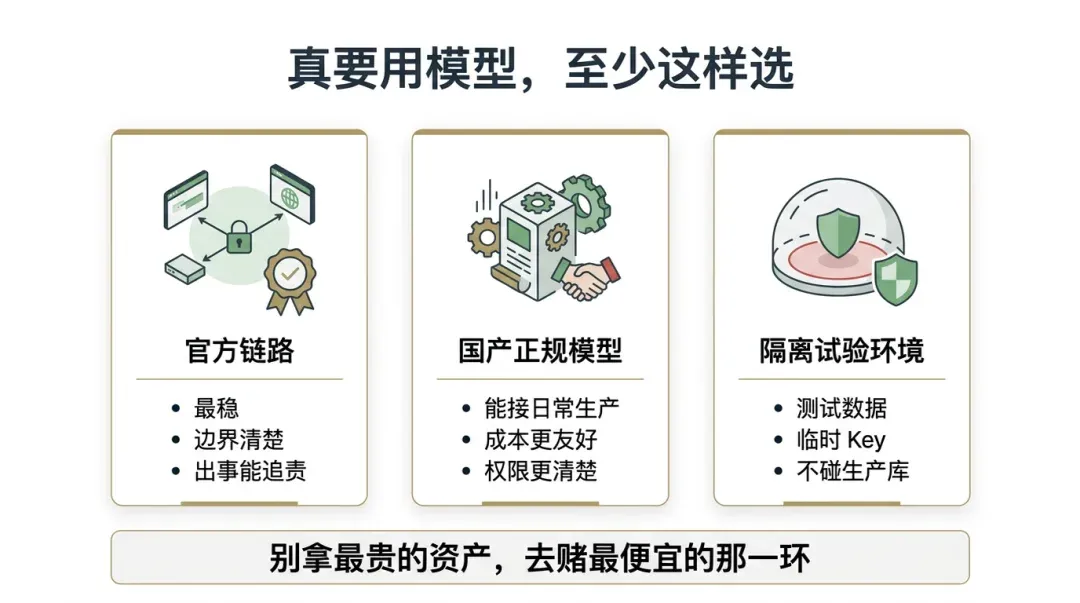
If you can use the official path, use it. If not, use legitimate domestic channels. At the very least, test in an isolated environment.
07
If You Really Need to Use Models, There Is More Than One Way
At this point, many will ask: does everyone have to use the official path and buy the most expensive plans? Not necessarily. I’m not advising you to spend the most money; I’m advising you not to gamble your most valuable assets on the cheapest link.
If you have the means to solve the network, payment, and account issues, try to stick to the official path. It might be more expensive, more troublesome, and occasionally frustrating, but at least the boundaries are clear. You know who owns the model, who provides the service, who is billing you, and where to go to complain or seek help if something goes wrong. That clarity alone is worth a lot.
If you can’t access the official path for now, don’t rush to throw yourself into the gray-market pools. Many domestic models can now handle a significant amount of real work. Models like GLM or MiniMax might not be the strongest in every high-intensity scenario, but for writing, basic development, running routine automation, and daily production, they are often sufficient. More importantly, they are legitimate, accountable, and have relatively clear boundaries. You don’t necessarily need the top-tier setup right away, but at least don’t throw yourself into an intermediary layer where no one can be held accountable.
If you really want to experience some new models, it’s not impossible. You can place them in an isolated environment, use test data, use temporary keys, and avoid connecting them to production databases, client privacy, or core repositories. Treat them as toys or test fields first; see if they are stable and worth it before deciding whether to proceed. Often, it’s not that you can’t try, but don’t try recklessly; it’s not that you can’t save money, but don’t save it in the places where you shouldn’t.
08
Final Thoughts
I know that people will continue to sell these services, and people will continue to buy them. Where there is demand, there will always be supply, especially when the official experience isn’t user-friendly enough. These gray-market alternatives won’t just disappear. I’m not pretending to be a moral saint—after all, I was in the thick of it myself, and many people who enter this space are indeed forced by reality.
Understanding is one thing; advising against it is another.
My judgment is clear. Unofficial APIs can be used as toys to test the waters, but don’t easily use them as production tools. The more you use models for things that are truly valuable, the more you should be rigorous about your chains, permissions, data, and boundaries of responsibility. Because often, what you think is a bargain is just a bill you’ve deferred. And that later bill is usually much more expensive.
If you are currently using these services, I’m not asking you to panic immediately. I’m just suggesting that you take some time tonight to carefully look at what you’ve connected, which keys are running, which projects are going through proxies, and which data shouldn’t be passing through someone else’s backend. Don’t wait until something goes wrong to learn this lesson.
The tuition for that lesson is usually not cheap.
