Digital Strategy Review | 2026
Claude Code Top 10 Highlights 08 | Three-Tier Agent Memory Scope: Simple, Yet Highly Practical
By Uncle Fruit · Reading Time / 8 Min
Foreword
When discussing “memory,” many systems quickly pivot toward grand narratives. Claude Code’s approach is far more grounded: it clearly defines the scope of memory first, then addresses how it can truly serve specific roles and tasks.
01
Three-Tier Agent Memory Scope: Simple, Yet Highly Practical
When AI systems discuss “memory,” they often lean toward grandiose concepts:
• Long-term memory • Semantic retrieval • Vector databases • Personalized user profiles
In terms of Agent memory, Claude Code has adopted a highly engineering-focused, pragmatic path: it starts by getting the scope right.
The core implementation can be found in:
• src/tools/AgentTool/agentMemory.ts
02
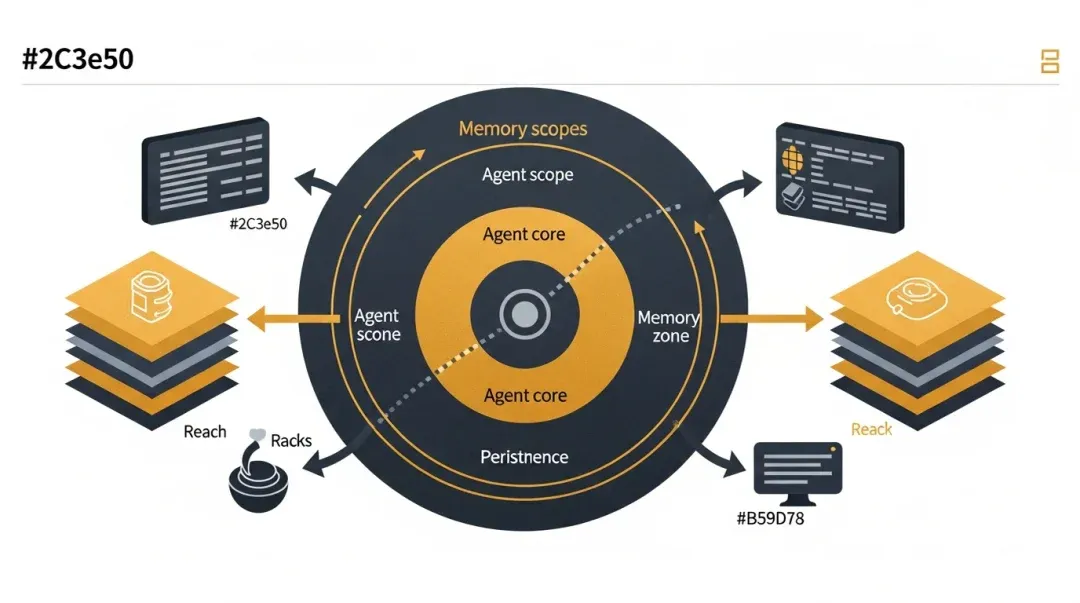
I. What Three Scopes Does It Support?
Claude Code’s Agent memory operates across three distinct scopes:
• user
• project
• local
A glance at this design reveals that the author has real-world experience with memory issues in professional development environments.
The biggest pitfall in memory systems isn’t “how to store it,” but “where to store it.”
Once the scopes are clearly defined, memory stops being a source of context pollution and starts acting as a tool for collaboration.
03
II. Why Scope Is More Important Than “Existence”
If a system provides only a single memory pool, it immediately encounters these issues:
• Cross-project contamination • Confusion between team-shared knowledge and personal preferences • Local machine-specific information mistaken for global knowledge • Difficulty managing differences between remote and local environments
Claude Code’s three-tier design effectively decouples these problems.
user
Suitable for cross-project personal experience, such as preferences, conventions, and long-term habits.
project
Suitable for project-level knowledge, which can be linked to team collaboration.
local
Suitable for content that is only meaningful on the current machine or within the current working copy.
This classification is both restrained and highly effective.
04
III. Why This Is Crucial for Coding Agents
The primary difference between coding scenarios and general chat memory lies in:
• Highly localized project context • Strong team constraints • The critical importance of personal preferences
Without scope partitioning, the user experience suffers significantly:
• Temporary build experiences from one project contaminate another. • A team convention is mistakenly treated as a global user preference. • Local toolchain states are incorrectly carried over to other environments.
Claude Code didn’t start by building a complex memory system; instead, it used scopes to cleanly define knowledge boundaries. This is a sign of mature engineering judgment.
05
IV. The Value Goes Beyond Storage Location
Many might think this is just “organizing folders.” However, the true value lies in systemic semantic separation.
Different scopes correspond to different knowledge meanings:
• user: Stable, cross-project, personal-oriented.
• project: Shared, project-specific.
• local: Temporary, machine-dependent.
Once the system acknowledges these differences, subsequent behaviors become much more rational:
• Tone adjustments for prompt injection. • Suitability for team sharing. • Persistence requirements.
This isn’t just about storage details; it’s a strategy for knowledge classification.
06
V. Why Claude Code’s Approach Is More Stable Than “Automatic Full Memory”
Many systems prefer to record everything by default and figure out how to recall it later. While convenient in the short term, this approach easily spirals out of control:
• Noise accumulates. • Contamination worsens. • Users struggle to understand why a specific memory appeared in their current context.
Claude Code’s three-tier scope design acts as a form of proactive governance:
Decide which category the knowledge belongs to before deciding how to use it.
This makes the system more explainable and better suited for long-term use.
07
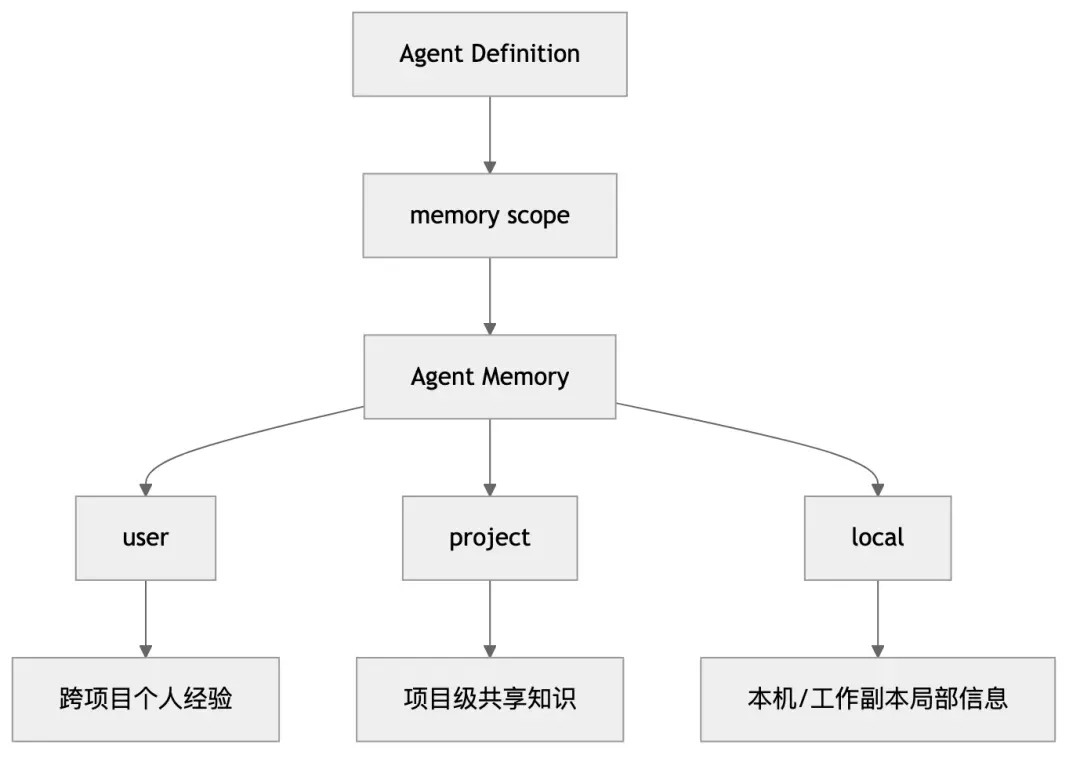
VI. Integration with Agent Definition
As mentioned in the previous article, the Agent definition itself can declare memory. This means memory is not a global switch, but a role-based runtime configuration.
Consequently, the system supports:
• Agents without memory.
• Agents using user memory.
• Agents using project memory.
• Agents using local memory.
This allows the memory mechanism to be naturally embedded into the Agent runtime rather than being an external add-on.
08
VII. Why This Reflects Claude Code’s Pragmatic Style
This design isn’t about showing off technical prowess. It doesn’t attempt to solve everything with a massive, intelligent, “all-knowing” long-term memory system.
Instead, it solves the most realistic engineering problems first:
• Don’t mix knowledge at different levels. • Don’t misuse memory across different roles. • Ensure memory is governable before pursuing advanced capabilities.
In engineering, this kind of restraint is often rarer and more valuable than “building the smartest system from day one.”
09
VIII. Understanding the Highlight in One Diagram
10
IX. Conclusion
The reason Claude Code’s Agent memory design is worth highlighting isn’t because it’s the most complex, but because it is rare in how clearly it defines knowledge boundaries.
It teaches us a simple but vital lesson:
The first thing a memory system must solve is not “how much to remember,” but “which pieces of knowledge belong to the same world.”
For coding agents, this judgment is particularly important, as development work is inherently a hybrid environment spanning individuals, projects, and machines.
