Digital Strategy Review | 2026
Claude Code Top 10 Highlights 03 | Fork Subagent and Prompt Cache: A Rare “Cost-Level Innovation”
By Uncle Fruit · Reading Time / 8 Min
Foreword
Many multi-agent designs focus solely on whether the functionality works, rarely asking: if we fork at a high frequency, will the costs eventually collapse the system? In this article, I want to clarify how Claude Code turns delegation into an engineering path that can be sustained in the long term.
01
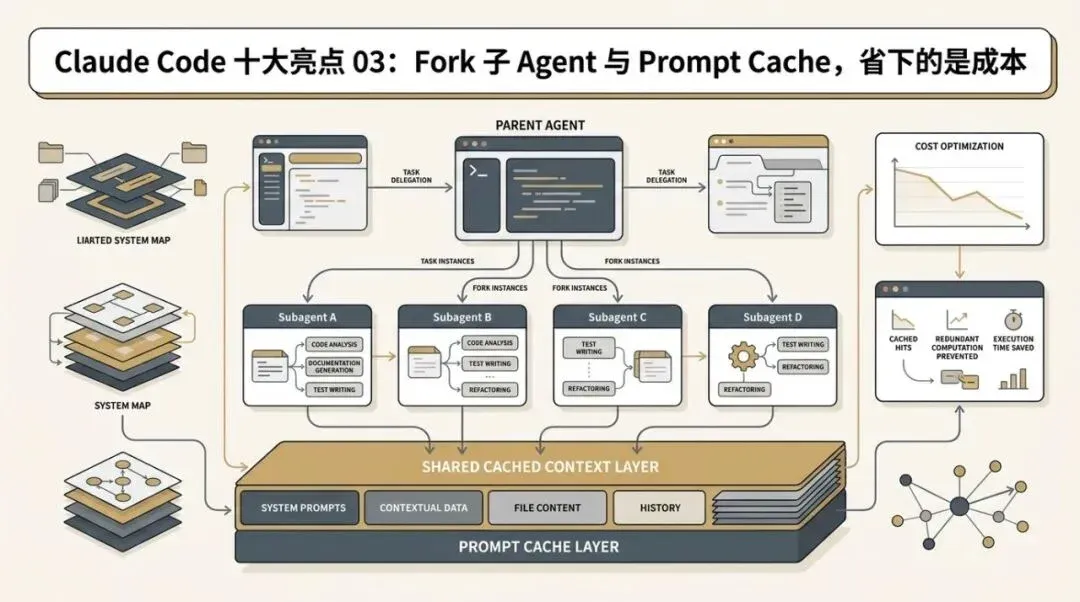
Fork Subagent and Prompt Cache: A Rare “Cost-Level Innovation”
When many teams build multi-agent systems, their focus often stops at:
• Can it fork? • Can it inherit context? • Can it run in the background?
Claude Code goes much further. It doesn’t just consider whether a forked sub-agent can work; it carefully considers whether the token costs after forking will explode.
This is the most brilliant part of src/tools/AgentTool/forkSubagent.ts.
02
I. Why Ordinary Forking Approaches Fall Short
The most naive implementation of a fork usually involves:
01 Copying the parent context 02 Adding a task description for the sub-agent 03 Sending a new model request
While this works functionally, it faces a very real problem:
Every forked child carries a large block of nearly identical prompt prefixes, burning tokens repeatedly.
If the system forks frequently, costs will skyrocket when multiple sub-agents run concurrently.
These issues are not obvious during the demo phase, but once they enter high-frequency, real-world usage, they quickly become a platform-level burden.
Claude Code clearly noticed this.
What makes Claude Code truly powerful is that it designed delegation as a cache-friendly input construction.
03
II. Claude Code’s Goal Isn’t Just “Can Fork,” But “Fork with High Reuse”
The most critical design goal in forkSubagent.ts can be summarized in one sentence:
Make the request prefixes of forked children byte-level consistent to maximize prompt cache hits.
This is a highly advanced goal. It shows that the author is not just looking at forking from a product feature perspective, but from the perspective of inference infrastructure costs.
04
III. How It Is Done
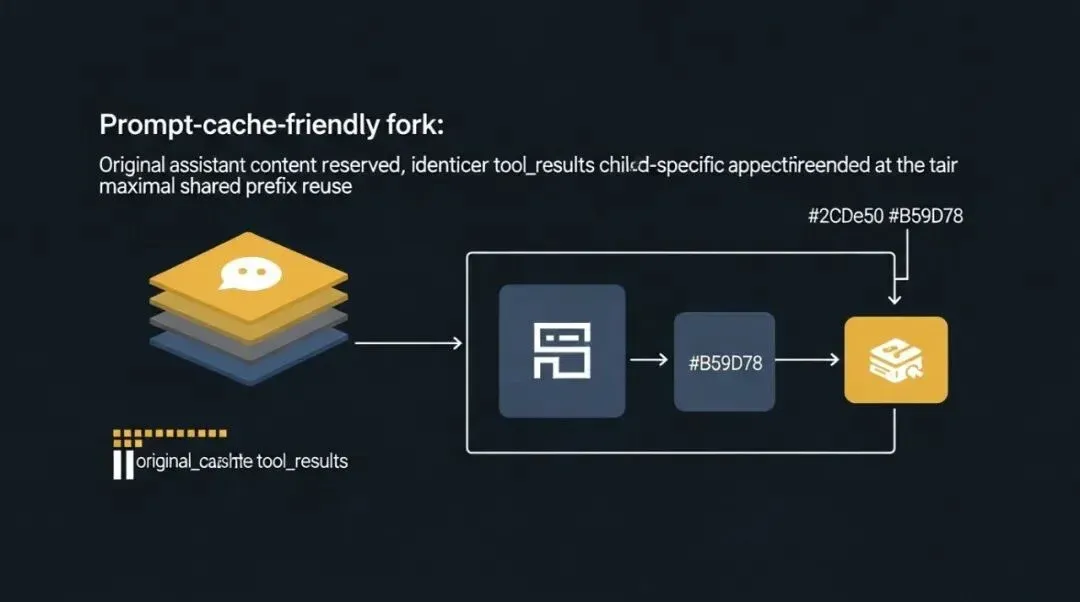
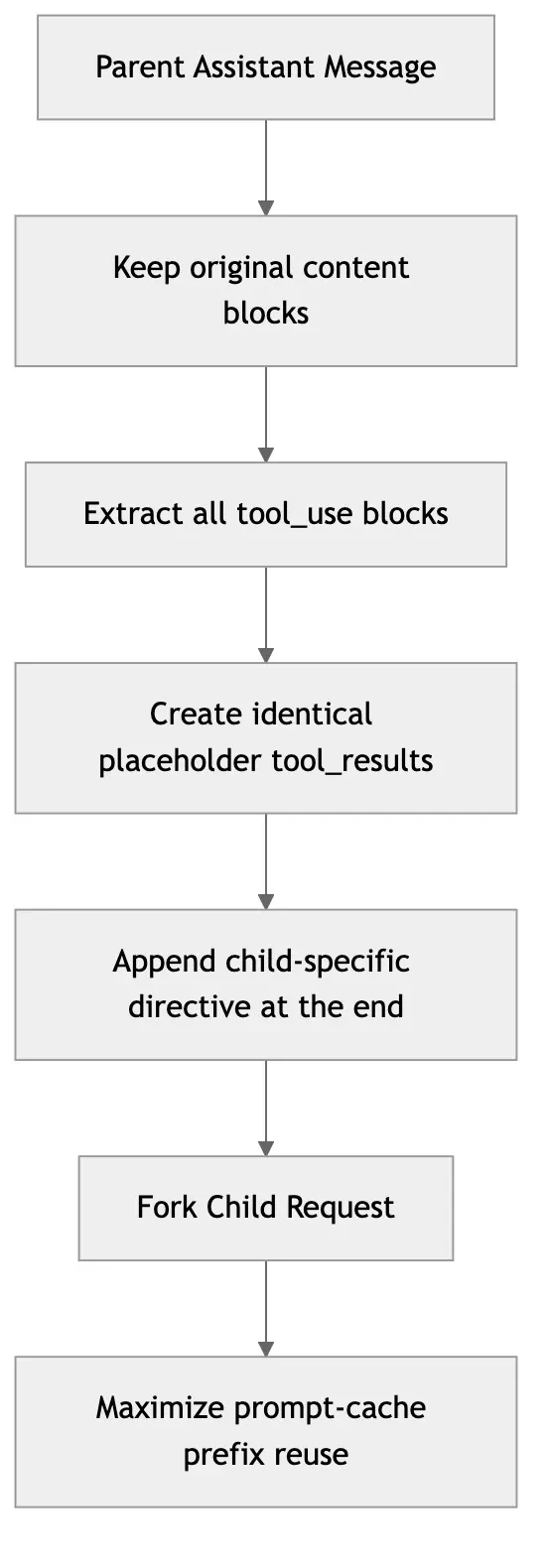
1. Don’t rebuild the parent context; reuse the original assistant message whenever possible
The forked child retains the full content of the parent assistant message, including:
• thinking
• text
• tool_use blocks
This means the system avoids “reorganizing” existing context, instead reusing the existing structure.
2. Generate a unified placeholder tool_result for all tool_use
This is the most crucial stroke in the entire design.
Instead of generating different tool_results for each forked child, it uses a unified placeholder, such as “Fork started — processing in background.”
The effect of this is: • All sub-agents maintain consistency in their long prefixes. • Truly changing content is pushed to the very end.
3. Keep the actual changing directives at the end
Each forked child naturally has a different task, but Claude Code tries to ensure that differences only appear in the final directive text.
This “stable prefix, changing tail” construction is highly conducive to prompt cache reuse.
4. Reuse the system prompt bytes already rendered by the parent session
This point is particularly sophisticated.
The system does not simply call getSystemPrompt() again for the sub-agent, as that could be affected by runtime conditions, feature gates, or GrowthBook hot states, leading to deviations in generated bytes.
Instead, Claude Code tries to pass the prompt bytes already rendered by the parent session in a thread-like manner.
This is a level of rigor that is rarely seen.
05
IV. Why This Matters
1. It makes multi-agent systems more scalable
Many multi-agent systems are capable in terms of performance but unsustainable in terms of cost. Especially when every sub-agent carries a large, nearly identical context, costs rise linearly.
Claude Code’s fork design is effectively “batch inference optimization” applied to multi-agent systems.
2. It makes forking a default strategy rather than an expensive privilege
If forking is expensive, the system will tend to reduce delegation. If forking can share a large amount of prompt cache, the runtime becomes much more confident in using delegation as a standard tool.
3. It reflects the engineering team’s deep understanding of LLM cost structures
This highlight best demonstrates that Claude Code is not just a “product that knows how to write prompts,” but a system that truly understands inference infrastructure.
06
V. How This Fundamentally Differs from Ordinary “Shared Context”
When many people hear about this design, their first reaction might be: “Isn’t that just sharing context?”
It is not.
Ordinary shared context only means: • The sub-agent can also see the parent context.
What Claude Code is doing is: • The sub-agent’s input construction is meticulously designed so that the caching layer treats them as having the same prefix as much as possible.
The former is functional sharing. The latter is cost engineering.
07
VI. Why This Design Is Difficult to Implement
Because you have to satisfy many conditions simultaneously: • The sub-agent must still correctly understand the task. • The parent context must not be corrupted. • Tool call relationships must remain valid. • Different children must be sufficiently similar. • Recursive forking must be avoided.
Claude Code even added specific protections in forkSubagent.ts, such as detecting forked children to prevent further recursive forking.
This shows it wasn’t just a “clever trick,” but a path turned into a long-term, usable feature.
08
VII. Understanding the Highlight in One Diagram
09
VIII. Conclusion
The most commendable aspect of the fork subagent design is not that it makes sub-agents smarter, but that it makes them “cheaper.”
When agent systems are actually deployed, this type of cost-level innovation is often scarcer than feature-level innovation. This is because the former requires the team to simultaneously understand: • Model context structure • Prompt caching behavior • System prompt stability • Multi-agent scheduling patterns
Claude Code’s answer here is beautiful:
Don’t just let the agent clone itself; let the agent’s clones share the same brain prefix as much as possible.
