Digital Strategy Review | 2026
Harness Engineering Deep Dive: Which Engineering Guardrails Has Claude Code Truly Built into Runtime?
By Uncle Fruit · Reading Time / 8 Min
Foreword
In this article, I prefer to approach the subject from an engineering problem perspective rather than a conceptual one: When everyone is talking about “Harness Engineering,” what exactly has Claude Code—a system that is already public and clearly battle-tested through real, complex tasks—turned into functional, operational “guardrails”?
By early 2026, “Harness Engineering” suddenly became a high-frequency term in the AI engineering circle. This isn’t because a brand-new technology category was invented, but because more and more teams have finally realized one thing:
When models are sufficiently powerful, what truly determines whether an AI Agent can work reliably over the long term is no longer whether the model can write code, but the constraint systems, feedback systems, execution systems, and recovery systems built around the model.
In other words, the problem is no longer “Can the LLM do it?” but “How does the system enable the LLM to do it continuously, controllably, recoverably, and with low entropy?”
The article you provided has already laid out the industry context of Harness Engineering quite completely: Mitchell Hashimoto is responsible for the naming, OpenAI provided the engineering report on an “agent-first world,” Anthropic supplemented it with a wealth of first-hand experience from long-running Agents and C compiler projects, and Martin Fowler further abstracted these practices into discussable engineering concepts.
But if we shift our perspective from “industry consensus” back to a “concrete system,” a more interesting question arises:
As a real, open-source system that has clearly reached the stage of multi-agent/long-task/heavy tool-calling, what actual optimizations has Claude Code made in terms of Harness Engineering?
This article answers only that question.
I will not redefine Harness Engineering itself. Instead, I will map the key frameworks mentioned in your article to the actual implementation in the Claude Code src directory, focusing on:
To ensure this article functions as an engineering analysis rather than a conceptual essay, I will repeatedly ground my points in the source code. The primary implementation areas referenced include:
I will state my core conclusion upfront:
Claude Code does not write “Harness Engineering” as an explicit slogan in its code, but it has effectively implemented a highly mature Harness Runtime. It is not driven solely by Prompt Engineering; instead, it has woven context governance, role division, task systems, permission centers, isolated execution, recovery logic, tool orchestration, and notification/UI control planes into a comprehensive runtime safety net.
If I had to summarize it in a more focused judgment, I would put it this way:
The greatest strength of Claude Code is not that “it has many Agents,” but that “it has placed Agents into a governable, observable, recoverable, and extensible engineering Harness.”
01
I. A Preliminary Judgment: What Style of Harness Does Claude Code Belong To?
This section provides a high-level judgment to ensure we don’t lose the forest for the trees when reading the source code later. If we roughly categorize the styles of the teams mentioned in your article:
- Hashimoto / Ghostty: Failure-driven documented guardrails.
- OpenAI: Systematic engineering of architectural constraints, tools, and feedback loops.
- Anthropic: Cross-session continuity, persistent progress, and long-task homeostasis.
- Stripe: Strong tool integration, isolated environments, and autonomous parallel PRs.
- Huntley / Ralph Wiggum Loop: Strong backpressure + rapid self-healing.
Then, the “temperament” of Claude Code is closest to:
OpenAI’s “Agent Runtime + Mechanized Guardrails” plus Anthropic’s “Long-task continuity and cross-session recovery” plus a touch of Hashimoto’s “Folding historical failures back into system constraints.”
It is not exactly like Stripe’s “enterprise-grade unattended parallel PR factory,” because Claude Code still emphasizes the foreground REPL control plane, user approval, task visibility, and interactive control. It is also not entirely like Hashimoto’s AGENTS.md-first approach, because Claude Code is clearly not satisfied with just document feedback; it has built many rules directly into the runtime.
Therefore, a more accurate statement would be:
Claude Code is not a purely document-driven Harness, nor is it a purely CI-driven Harness; it is a runtime-centric Harness.
This judgment is critical. As you will see later, many of its optimizations are not about “writing more documentation,” but about internalizing rules into:
- Tool exposure boundaries
- Task lifecycles
- Agent role specifications
- Automatic compaction of the query loop
- Permission gates
- Worktree / remote / teammate execution backends
- A unified control plane within the REPL
This shows that it has pushed the Harness from the “instructional layer” to the “system layer.”
02
II. The First Consensus of Harness Engineering: The Bottleneck is Infrastructure, Not Model Intelligence
This is one of the core industry consensuses in your article. The source code structure of Claude Code strongly supports this judgment.
2.1 If the bottleneck were the model, the codebase wouldn’t look like this
If a team truly believed “the model is smart enough, and the rest is not a problem,” its product code would typically have these characteristics:
- A very thin entry point.
- Casual tool registration.
- Agents that are just prompt templates.
- A lack of complex task state.
- No complete recovery mechanism.
- No systematic permission/task/view state.
Claude Code is nothing like this.
On the contrary, it has invested heavily in structured engineering in these areas:
- The long-turn main loop in
query.ts. - Semantic concurrent scheduling in
toolOrchestration.ts. LocalAgentTask/RemoteAgentTask/InProcessTeammateTask.- Unified delegation entry points and multi-backend routing for
AgentTool. - Unified modeling of tasks, permissions, MCP, plugins, teammates, and remote viewers in
AppState. REPL.tsxas a unified control plane.
This type of investment shows that the author is very clear:
The real challenge is not getting the model to “say one more correct thing,” but keeping the system stable, controllable, and recoverable during complex execution.
2.2 Claude Code’s tool system itself is a counter-proof
src/tools.ts demonstrates a very important engineering attitude:
- Tools are not “functions casually exposed to the model.”
- Tools are dynamically cropped capability surfaces.
- Tools are subject to feature gates, permission contexts, and mode constraints.
This proves that the Claude Code team does not consider “whether the model can choose the right tool” as the only problem. They are more concerned with:
- What should be exposed in the current session?
- Should different roles see different tools?
- Should capability surfaces switch based on different running modes?
This is typical infrastructure-first thinking.
2.3 The complexity of the query loop also proves this
query.ts contains a large amount of complex processing related to “non-intelligent parts”:
- microcompact
- autocompact
- reactive compact
- max output tokens recovery
- stop hooks
- task budget
- synthetic tool_result
- tool result budget
None of these things exist to make the model “smarter”; they exist to make the model “less likely to lose control” during real-world execution.
This is highly consistent with the first principle of Harness Engineering:
Admit that the model will make mistakes at the system boundaries, then design guardrails and recovery mechanisms around those mistakes.
Therefore, if I had to use one sentence to correspond to the industry consensus, I would say:
The entire architecture of Claude Code is source-code-level evidence that “infrastructure is the bottleneck.”
03
III. The First Pillar: Context Architecture, Claude Code Has Gone Very Deep
You correctly placed Context Architecture as the first of the four pillars. Claude Code does not stop at “supporting context injection”; it has achieved layering, cropping, compression, role-based assignment, and dynamic assembly.
3.1 Claude Code’s context is not one big prompt, but a composition
Between main.tsx, query.ts, runAgent.ts, various Agent definitions, memory, and MCP mechanisms, Claude Code’s context sources can be broken down into these layers:
01 Session-level system prompt 02 User context / system context 03 Tool definitions and tool surfaces 04 Agent-specific prompt / role constraints 05 Memory injection 06 MCP tools / resources 07 Hook effects and session state 08 Transcript / messages
This means Claude Code did not adopt the “stack everything into a static document” approach from the start.
It is more like the three-tier context system you mentioned, but implemented with a more runtime-oriented approach:
- Tier 1: Resident Context: Composed of system prompts, session configurations, and core instructions.
- Tier 2: Role/Capability-based Loading: Composed of Agent definitions, skills, mcpServers, memory scopes, etc.
- Tier 3: On-demand Query or Runtime Emergence: Composed of specific file reads, grep, MCP resources, historical transcripts, progress files, etc.
3.2 It takes “more context is not always better” very seriously
This is highly consistent with Horthy’s observation of the “40% Smart Zone / 40%+ Dumb Zone.”
Although Claude Code’s code does not explicitly write “40% sweet spot,” it reflects the same judgment in multiple dimensions:
omitClaudeMd: Some read-only Agents do not inherit massive project instructions by default, switching to on-demand reading instead.ToolSearchand tool cropping: Not all sessions expose the full set of tools.compact/microcompact/reactiveCompact: It doesn’t wait for an explosion to clean up; it governs continuously.forkSubagent: It tries to share context prefixes to avoid repeatedly stacking large chunks of context.- Dedicated roles like
Explore/Plan: Reducing pollution from irrelevant context.
In other words, Claude Code’s context architecture is not “sending all potentially useful information to the model,” but:
Define boundaries first, then dynamically assemble context based on the current task and role.
This is the mature form of Harness Engineering for Context Architecture.
3.3 It treats “compression” as a primary path, not an exception
The compact system in query.ts is particularly worth emphasizing, as it is one of the deepest areas Claude Code has worked on regarding Harnesses.
There are at least four related mechanisms here:
- microcompact
- auto compact
- reactive compact
- snip compact
The implication of this design is very clear:
01 System tasks will naturally become longer. 02 Long tasks will naturally approach context limits. 03 Therefore, context governance must be a built-in capability of the main loop.
This is a major difference from many other systems. Many systems only throw errors or perform crude cropping when the prompt is too long, whereas Claude Code has entered the stage of “continuous, incremental, semantically-aware context maintenance.”
3.4 It links context governance with role division
Claude Code does not say “context must be concise” on one hand while giving every Agent full capabilities on the other. Instead, it makes the role itself part of context governance through specialized Agents, specialized tool surfaces, and specialized memory scopes.
This aligns perfectly with your judgment that “Agent Specialization is itself a Context Management strategy.”
So, looking only at the first pillar, my conclusion is:
Claude Code no longer just “has context engineering”; it has made context architecture a runtime-level capability.
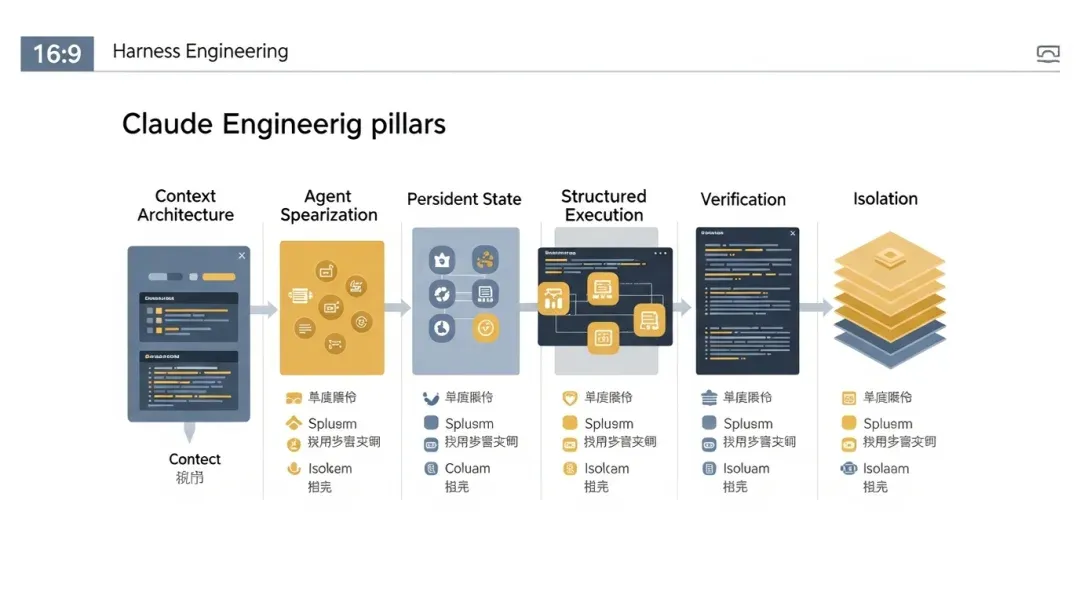
If you break Claude Code apart, the most telling aspect is not a single feature, but how several engineering pillars work together.
04
IV. The Second Pillar: Agent Specialization, Claude Code is Almost Native Support
Agent Specialization is the second pillar in your article. In Claude Code, this not only exists but is a core system capability.
4.1 Its Agents are not prompt roles, but runtime specification objects
In loadAgentsDir.ts, an Agent definition can declare:
whenToUsetoolsdisallowedToolsskillsmcpServershooksmodeleffortpermissionModebackgroundmemoryisolationmaxTurns
This shows that Claude Code’s Agent specialization is not “writing different system prompts for different personalities,” but:
Assigning different execution capabilities, tool boundaries, isolation strategies, and running budgets to different roles.
This is highly consistent with the role paradigm of “Research Agent / Planning Agent / Execution Agent / Review Agent / Debugging Agent / Cleanup Agent” mentioned in your article.
4.2 Built-in roles already reflect a typical specialization paradigm
The three built-in agents best illustrate this:
Explore Agent
- Read-only.
- Fast search.
- Emphasizes concurrent read tools.
- No editing tools. This is almost exactly the “Research Agent” template from your article.
Plan Agent
- Read-only.
- Focuses on requirement breakdown, architectural analysis, and critical files.
- No direct write execution allowed. This is the “Planning Agent” template.
Verification Agent
- No arbitrary modifications in the project directory.
- Forces command-level verification.
- Forces a PASS / FAIL / PARTIAL verdict.
- Emphasizes adversarial probes. This corresponds perfectly to the “Review/Verification Agent.”
Although Claude Code does not copy the role naming system from your article, the actual capability layering is very close.
4.3 Specialization is also reflected in tool surface cropping
This is where Claude Code differs most from many “multi-role prompt” systems.
Many systems give Agents different names, but all roles can see all tools. Claude Code is clearly not like this:
- Different roles, different tools.
- Different roles, different permission modes.
- Some roles deliberately strip away editing capabilities.
- Some roles are better suited for background execution by default.
This means role differences have moved from “thinking style” to “operational authority.”
4.4 Specialization in Claude Code is platform-level, not just built-in roles
Because it supports:
- built-in agents
- user / project / policy / plugin agents
So these are not just a few roles hardcoded into the system, but an extensible specialization framework.
From a Harness Engineering perspective, this is critical. Because once specialization is only built-in and non-extensible, it is more like a product feature; only when it becomes a platform capability can it truly support long-term evolution.
Therefore, regarding the second pillar, I give Claude Code a high rating:
It doesn’t just support Agent Specialization; it has made specialized Agents first-class objects in the runtime.
05
V. The Third Pillar: Persistent Memory, Claude Code Takes the “Task/Session State + Agent Memory” Dual Route
The third pillar in your article is Persistent Memory, with a special emphasis on:
- Progress must be persisted to the file system.
- It must be possible to recover from artifacts after session switching.
- Structured formats are more stable than free text.
Claude Code did not implement this exactly according to the Anthropic init.sh + progress.txt + feature_list.json pattern, but it already has its own quite mature two-layer scheme:
01 Persistence of task/session state. 02 Persistence of Agent role memory.
5.1 Task and session state persistence is very strong
Claude Code’s Task system, session storage, outputFile, transcript subdir, remote metadata, and resume logic show that it places a high degree of importance on “cross-session continuity.”
In particular, these features are very similar to the goals of Anthropic’s long-task practices mentioned in your article:
- Sub-Agents have their own transcripts.
- Task output can be written to disk.
- Tasks can be resumed.
- Remote tasks can be restored.
- Viewing agents can bootstrap existing transcripts.
This shows that Claude Code does not assume “all important information stays in the current context window.”
It has offloaded a large amount of critical state to:
- task output files
- session storage
- task metadata
- remote agent sidecar metadata
This “file system as a carrier of continuity” approach is highly consistent with the requirements of Harness Engineering for persistent artifacts.
5.2 Agent Memory is another layer: role-level long-term memory
agentMemory.ts supports:
userprojectlocal
This allows Claude Code’s persistence system to store not only “task status” but also “role experience.”
The combination of these two layers is very interesting:
- The task layer is responsible for “how far this work has progressed.”
- The memory layer is responsible for “what this role knows in the long term.”
This is more general than a single progress.txt and is better suited for a system like Claude Code that involves long-term evolution, multiple roles, and multiple projects.
5.3 Similarities and differences with the Anthropic route
Similarities
- Both place great importance on cross-session continuity.
- Both acknowledge that the context window cannot handle all memory responsibilities.
- Both view file system artifacts as first-class recovery materials.
Differences
- Anthropic’s case is more “project advancement file-driven.”
- Claude Code is more “runtime state + transcript + task metadata-driven.”
From a practical standpoint, neither route is absolutely superior; they just represent different system forms. Anthropic is more like “long-distance Agent project site management”; Claude Code is more like a “general-purpose agent runtime with a complete control plane.”
5.4 Weaknesses must also be pointed out honestly
If we score it strictly according to the ideal form of Persistent Memory in your article, Claude Code still has several obvious gaps:
- I haven’t seen a strong, file-driven feature list/done criteria workflow like Anthropic’s.
- I haven’t seen a default, unified, and strictly constrained structured progress spec become the main development flow.
- There is no clearly formed two-stage long-run routine like “Initialize Agent -> Coding Agent.”
In other words, Claude Code is strong in “task recovery” and “role memory,” but it has not yet fully systematized the “long-term project progress file-based workflow.”
The conclusion can be summarized as:
Claude Code already possesses the core infrastructure for persistent memory, but it is more like runtime-state persistence rather than the complete form of an Anthropic-style project progress-driven Harness.
06
VI. The Fourth Pillar: Structured Execution, Claude Code Implements This Almost Across the Board
The fourth pillar in your article is Structured Execution, namely:
- Understand
- Plan
- Execute
- Verify
In Claude Code, this is not a suggestion; it has been broken down into different runtime roles and tool mechanisms.
6.1 Plan Mode and Plan Agent are already explicitly institutionalized
Claude Code clearly has a “plan before executing” awareness, which is reflected in several places:
EnterPlanModeToolExitPlanModeToolPlan Agent- Support for plan mode requirements in various teams/teammates.
In other words, the system doesn’t just tell the model “please think first”; it provides an explicit mode-switching and role-separation mechanism.
This is very close to the principle mentioned in your article by Boris Tane: “Approve the written plan first, then write the code.”
6.2 Execute and Verify are separated
Claude Code does not let the main Agent handle everything alone; it explicitly has:
- execution-oriented agents
- verification agents
This role separation is the implementation of the most critical “separating thinking and doing” in Harness Engineering.
Without this, the system easily falls into:
- Writing it itself.
- Judging its own work as good.
- Declaring completion itself.
The existence of the Verification Agent is essentially a countermeasure against this endogenous bias.
6.3 The query loop itself is also the underlying support for structured execution
Structured execution is not just at the role level; it is also reflected in the control semantics of the main loop:
- assistant generates tool_use
- tool round execution
- tool result feedback
- stop hook
- compact boundary
- continue to the next round
This path is essentially a structured execution state machine. It is not “think everything at once and say everything at once,” but:
A cyclic structure of Thinking, Acting, Feedback, Compressing, and Continuing.
6.4 Team-based collaboration further strengthens structured execution
In the in-process teammate / swarm route, this structure is even more obvious:
- The leader can dispatch.
- Workers have role and permission boundaries.
- Plan mode can require planning first.
- Permissions are centralized.
- Results flow back through tasks and notifications.
This has already exceeded the scope of “structured prompts” and entered the realm of “structured organizational processes.”
Therefore, regarding the fourth pillar, Claude Code’s match is also very high.
07
VII. AGENTS.md and Live Document Feedback Loops: Claude Code Supports Them, But Doesn’t Rely Solely on Them
Your description of AGENTS.md in your article is very precise: it is essentially a live document for Agents and a precipitation layer for historical failure cases.
Claude Code does not conflict with this approach; it is even compatible with and respects it in its operational logic. However, it has one very obvious characteristic:
It does not build the Harness primarily on AGENTS.md, but uses AGENTS.md as part of a larger runtime.
7.1 Claude Code clearly respects the repository-level instruction system
From the way the entire project runs and the rules for reading AGENTS.md in your task, it is clear that Claude Code takes the following very seriously:
- Repository-level instruction files.
- Directory-level override rules.
- Scope constraints.
In other words, it fully acknowledges that “document artifacts within the code repository are one of the sources of truth for the agent.”
7.2 But it does not stop at “document constraints”
Where Claude Code goes further than the simple AGENTS.md model is:
- Role boundaries are encoded into Agent definitions.
- Execution boundaries are encoded into tool permission contexts.
- Running modes are encoded into Task and AgentTool routing.
- Long-task recovery is encoded into transcripts / metadata / outputFiles.
This means:
AGENTS.md is important in Claude Code, but it is not the only guardrail. The real design philosophy is more like:
Documents tell the Agent what to comply with, and the runtime is responsible for making these constraints executable, verifiable, and recoverable.
This is actually a more mature stage than a pure document feedback loop.
7.3 From the Hashimoto route, what is Claude Code’s advantage?
Hashimoto’s core experience is:
- If an Agent makes a mistake once, write it into AGENTS.md / constraints to avoid repeating it.
The further answer provided by Claude Code’s source code is:
- If it can be solved by documentation, use documentation.
- If it cannot be stably solved by documentation, upgrade it to a runtime constraint.
This is also one of the most critical evolutionary directions in Harness Engineering. Because pure document constraints will inevitably hit a boundary in the long run:
- Just because the model sees it doesn’t mean it will execute it.
- Too many instructions will pollute the context.
- Some constraints should be mechanized by nature.
Claude Code has actually taken this step.
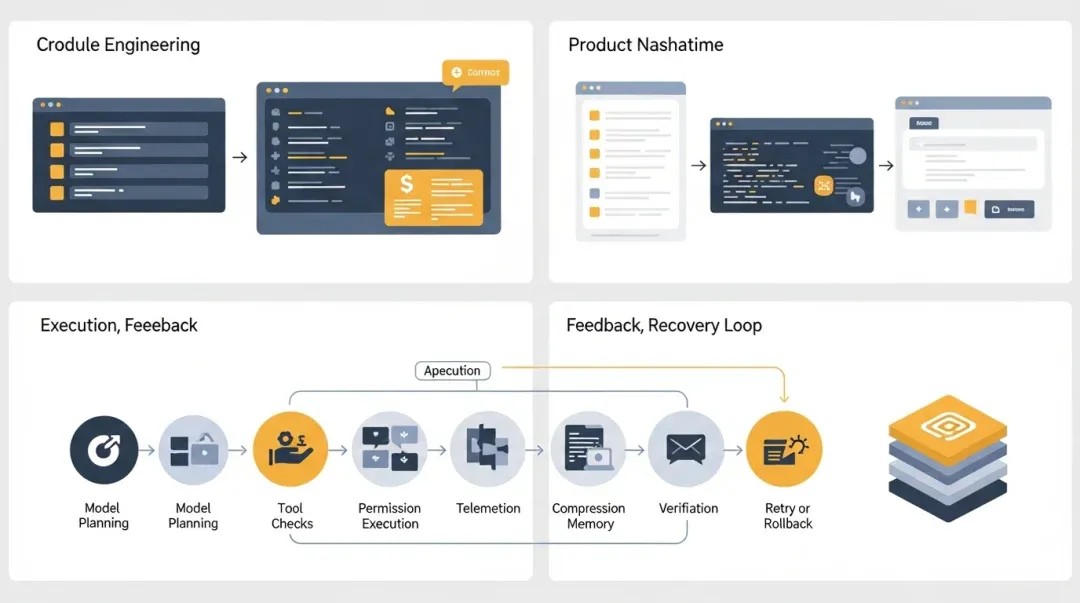
A mature coding agent doesn’t just move forward; it must know when to contract, verify, recover, and then continue to advance.
08
VIII. Architectural Constraints and Automated Execution: Claude Code Has Achieved Part of It, But It’s Not Yet an OpenAI-style “Hard Architectural Pipeline”
You emphasized the OpenAI practice of:
- Custom Linters.
- Clear dependency directions.
- Error messages that directly teach the Agent how to fix them.
The question is: How much of this has Claude Code achieved?
8.1 It already possesses the thinking of “mechanized execution constraints”
This is most evident in:
- The permission system is mechanized.
- Tool boundaries are mechanized.
- Plan mode / exit plan mode is mechanized.
- Execution boundaries for worktree / remote / fork / teammate are mechanized.
In other words, Claude Code is already very strong in “runtime constraints.”
8.2 It also has a lot of lint / validation / schema-based thinking
The entire project contains a large amount of:
- schema
- validation
- settings verification
- parsing and verification of commands / keybindings / hooks / agent frontmatter
This shows that the team’s basic engineering style leans towards “rules encoded first.”
8.3 But in the publicly exposed parts, I haven’t fully seen the OpenAI-style “Architectural Dependency Direction Linter System”
From what I can clearly see in src, Claude Code is very strong on runtime harness; but it hasn’t yet shown at the document level, as the OpenAI report did:
- Codebase-level dependency directions are fully mechanized.
- There are dedicated linters that teach the agent how to fix architectural errors.
This doesn’t mean it doesn’t have relevant practices, but from the main body of src read this time, the strongest guardrails are clearly still at the runtime layer rather than the repo architecture linter layer.
8.4 This is actually related to its product positioning
OpenAI’s practices are more geared toward deep development of specific internal projects; Claude Code is more like a general-purpose agent runtime product.
Therefore, Claude Code prioritizes strengthening:
- Execution guardrails common to multiple scenarios.
- Unified task control for multiple Agents.
- General permission models.
- Context compression and recovery.
Rather than hardcoding the architectural dependency constraints of a specific repository as a default product capability.
So on this item, my conclusion is:
Claude Code has deeply implemented the mechanization of runtime constraints, but it has not yet reached the stage where “repository architectural constraints are the main body of the harness” in a publicly visible way.
09
IX. Observability Integration: Claude Code Has Taken “Seeing the Runtime” Very Seriously
You included Observability as a core component of the Harness in your article, which is absolutely correct. Without observability, an Agent is just stumbling around in a black box.
Claude Code’s implementation of this is very representative.
9.1 Its observability for tasks is very strong
LocalAgentTask tracks:
- toolUseCount
- tokenCount
- lastActivity
- recentActivities
- summary
Remote tasks also have their own state and progress models. This shows that the system cares not only about “what the result is” but also “what is happening during the task process.”
This is highly consistent with the OpenAI approach of connecting runtime observations to the Agent.
9.2 Its observability for the query loop and tool execution is also very strong
In the code, you can see a large amount of:
- analytics events
- tool duration
- query profiler
- tracing
- startup profiler
- internal logging
These things are not just for show; they exist so the system knows:
- Where is the task stuck?
- Where is the tool time being spent?
- Where is the query bottleneck?
- What is the agent’s behavioral chain?
This is one of the foundations of Harness Engineering: if the system cannot observe agent behavior, it cannot continuously converge guardrails.
9.3 It even unified observability with the UI
Many systems do background tracing, but users cannot see it. Claude Code productizes part of observability through the REPL:
- task list
- progress
- notifications
- viewing agent transcript
- permission queue
This is a very pragmatic form of productized observability: it serves both the engineering team’s debugging and the user’s understanding of the system state.
9.4 Differences from the OpenAI-style “connect to browser, check logs, look at metrics”
Claude Code also has browser / MCP / diagnostics / terminal capture capabilities, but from the core structure read this time, its most mature observation surfaces are still:
- Task-level observation.
- Tool-level observation.
- Query-level observation.
- Session-level UI visibility.
In other words, it already has a strong foundation for “observability connected to Agents,” but whether it deeply integrates product logs and business metrics in all default scenarios like the OpenAI report depends on the specific usage environment.
However, from a Harness perspective, it has clearly surpassed the “blind running” stage.
10
X. Entropy Management and Garbage Collection: Claude Code Has Built-in Multi-layer Anti-Entropy Mechanisms
You mentioned OpenAI’s “AI Slop cleanup” and regular garbage collection agents; that is a very important but often overlooked layer of Harness Engineering.
Although Claude Code doesn’t explicitly write a narrative like “20% of time every Friday is for cleaning AI Slop,” it actually already possesses various anti-entropy mechanisms.
10.1 Context Entropy: Continuous cleanup through compact
The most direct layer of entropy is the entropy of dialogue and context. Claude Code is very strong in this regard:
- microcompact
- auto compact
- reactive compact
- snip
These mechanisms are essentially doing one thing:
Preventing ineffective accumulation in the context from dragging the system into the Dumb Zone.
10.2 Code Execution Entropy: Controlled through role division and verification roles
The division of labor between the Verification Agent, Plan Agent, and Explore Agent essentially reduces the entropy brought about by a single Agent arbitrarily expanding its responsibilities.
A system without specialization and verification roles easily allows the entropy of “write a little -> think it’s done -> mess it up a little more” to accumulate rapidly. Claude Code mitigates this to a certain extent through structured roles.
10.3 Task Entropy: Flattening complexity through Task lifecycles and notifications
If a system allows a large number of background tasks without a unified task model, over time, it will inevitably lead to:
- Not knowing which tasks are still alive.
- Not knowing which results are invalid.
- Not knowing which transcripts are still worth reading.
Claude Code’s Task system itself is an anti-entropy design because it converges execution objects into a unified state machine.
10.4 Document and Capability Entropy: Explicit scope management through plugins, agents, settings, and hooks
The entire system makes extensive use of:
- Source differentiation.
- Permission source differentiation.
- Layering of plugin / built-in / user / policy.
This is also a way of anti-entropy: not letting all customization information mix in one place, but clarifying “where capabilities come from, what the override order is, and what the scope is.”
10.5 But it is not exactly the same as OpenAI’s “Background Cleanup Agent”
Claude Code already has many guardrails and cleanup mechanisms, but if strictly compared to the OpenAI route in your article:
- Regularly running cleanup Agents.
- Specifically scanning for expired documents.
- Cleaning up redundant low-quality code.
In the publicly visible part, Claude Code has not yet fully made the “entropy management Agent” a similarly strong fixed product surface.
It is more like:
- Anti-entropy via runtime.
- Entropy reduction via structured roles.
- Removing context noise via compact.
Rather than explicitly establishing a “cleanup Agent” as a main-line feature.
Therefore, on this item, Claude Code is a “strong anti-entropy foundation, weak explicit scavenger productization.”
11
XI. Engineer Role Shift: Claude Code Has Encoded “Designing the Environment” into the System
An important point in your article is:
- The engineer’s role is shifting from “writing code directly” to “designing the Agent’s working environment + managing the Agent’s workflow.”
The existence of Claude Code supports this shift.
11.1 It makes “environment design” first-class work
Because the real capability of Claude Code depends to a large extent on:
- AGENTS.md / repository instructions.
- Agent definitions.
- Tool exposure methods.
- Permission rules.
- MCP / plugins / hooks.
- Worktree / remote / plan mode choices.
This means that for engineers and teams to use Claude Code well, the focus of their work will naturally shift to:
- Designing capability boundaries.
- Designing task flows.
- Designing verification flows.
- Designing recovery and approval mechanisms.
This is highly consistent with your judgment that “engineers are shifting from writing code to designing environments.”
11.2 It also reinforces that “planning is more valuable than coding”
Plan Mode, Plan Agent, Verification Agent, and the Task system all tell users:
Do not consume all your intelligence on “starting to write immediately,” but focus more on how to organize execution.
This is actually the core cultural migration of Harness Engineering.
11.3 Claude Code’s REPL is more like a management console than a typing box
This is particularly worth emphasizing. Because the REPL is easily misunderstood as a “chat UI.” But when it starts to take on:
- Task lists.
- Agent transcript switching.
- Permission control.
- Sandbox approval.
- Teammate navigation.
- Notifications.
It has actually become an “Agent Workbench.”
This fits the shift in the engineer’s role perfectly:
- No longer just “I will write.”
- But “I will orchestrate, review, authorize, recover, and view.”
In other words, Claude Code not only supports Harness Engineering technically, but it also trains engineers to enter the Harness mindset through its interaction model.
12
XII. If We Score Based on the Six Consensuses in Your Article, Where Does Claude Code Stand?
Below, I will quickly map Claude Code based on the six consensuses summarized at the end of your article.
Consensus 1: The bottleneck is infrastructure, not model intelligence
Match: Extremely High. The entire code structure proves it believes in this.
Consensus 2: Documents must be a live feedback loop
Match: Medium-High. Claude Code respects repository documents and the AGENTS system, but goes further by upgrading many constraints into runtime rules.
Consensus 3: Thinking and execution must be separated
Match: High. Plan Mode, Plan Agent, Verification Agent, and structured execution loops all support this.
Consensus 4: More context is not always better
Match: Extremely High. Compact, role cropping, tool cropping, omitClaudeMd, and fork cache designs all demonstrate this.
Consensus 5: Constraints must be mechanized
Match: High, but leans toward runtime constraints. Permissions, tools, tasks, and modes are mechanized; but repo architecture linter-level mechanization hasn’t reached the extreme seen in the OpenAI case.
Consensus 6: Engineer role shifts from writing code to designing environments
Match: High. The entire product form of Claude Code is amplifying this new role.
Therefore, if we estimate based on the Harness Engineering maturity model, I would say:
Claude Code has clearly surpassed Level 2, is approaching Level 3, and has touched the edge of Level 4 in several dimensions. But it is more like an “interactive, high-control-plane autonomous system” rather than a Stripe-style extreme unattended PR factory.
13
XIII. Compared to OpenAI / Anthropic / Stripe, What is Most Unique About Claude Code?
If OpenAI’s specialty is “mechanized architectural constraints + zero-hand-written-code environment design,” Anthropic’s specialty is “long-task cross-session continuity,” and Stripe’s specialty is “enterprise-grade unattended parallel PRs,”
Then the most unique thing about Claude Code is:
It has made the Harness a unified, user-interactive runtime control plane.
This feature is reflected in three aspects:
13.1 It does not hide the Harness in the background
Many teams have strong Harnesses, but they mainly exist in:
- CI
- Devbox
- Linter
- Pipeline
Claude Code exposes a large amount of the Harness directly in the foreground product:
- task list
- permission dialog
- viewing agent
- plan mode
- background agent notifications
This makes the Harness not just infrastructure within the engineering team, but also a product capability directly perceived by the user.
13.2 It is a “multi-backend unified Agent Runtime”
The same AgentTool can be routed to:
- local
- background
- fork
- worktree
- remote
- teammate
This shows that Claude Code’s Harness is not designed for a single point of a specific execution environment, but is designed around a unified abstraction of “Agent Runtime.”
13.3 It places special emphasis on “control always remaining in human hands”
Whether it’s permissions, plan mode, sandboxes, or foreground tasks, Claude Code clearly leans more toward:
- Strong interaction.
- Interruptibility.
- Observability.
- Recoverability.
Rather than extreme unattended operation.
This makes it more suitable for a broad-spectrum product, rather than just for internal high-maturity teams.
14
XIV. Three Obvious Gaps Still Existing in Claude Code
To make this analysis more complete, I must also honestly point out that compared to the ideal form of the Harness in your article, Claude Code still has some obvious gaps.
14.1 Lack of a stronger “project progress file-driven workflow”
Anthropic’s typical approach is:
init.shprogress.txtfeature_list.json
These things explicitly externalize long-term project status, which is particularly suitable for long-running cross-session tasks.
Although Claude Code has task state, transcripts, and agent memory, it has not yet made “structured feature lists and progress files” a core layer in the default workflow.
14.2 Lack of stronger repo-level architecture enforcement productization
Claude Code is very strong on runtime constraints, but I haven’t fully seen the OpenAI-style:
- Clear hierarchical dependency directions.
- Custom linter errors that directly teach the agent how to fix them.
- Architectural constraints entering the default toolchain.
If this part is filled in, it will make its Harness look more like “extending from runtime to repository design rules.”
14.3 The explicit product surface for “long-term maintainability / AI slop cleanup” is not yet strong enough
Claude Code already has anti-entropy mechanisms like compact, specialization, and verification. But if compared to the OpenAI / “garbage collection Agent” route in your article, it has not yet established “codebase long-term cleanup and quality recovery” as a particularly clear first-class product feature.
This might be an area worth strengthening in the future.
15
XV. If You View Claude Code as a Harness Engineering Product, Here Are the Five Things Most Worth Learning
If you don’t want to replicate all the functions of Claude Code, but want to extract Harness experience from it, I would summarize the following five things most worth learning.
15.1 Turn Agents into Tasks first, then talk about multi-Agent
Without a Task model, all multi-Agent systems will eventually degenerate into “sending another sub-request.”
15.2 Make context governance a built-in capability of the main loop
Don’t wait for the prompt to explode before remedying it. Mechanisms like compact / microcompact / reactive compact should be the main path as much as possible.
15.3 Role differences must be reflected in tool surfaces and permission surfaces, not just prompt tone
Otherwise, Agent specialization will only stay at the performance level.
15.4 Permissions must be centralized, otherwise multi-Agent systems will quickly lose control
Leader-centered permission is very worth copying.
15.5 The REPL / UI control plane is not an accessory; it is part of the Harness
Allowing users to see tasks, switch agent transcripts, and understand what the system is doing is part of reliability engineering.
16
XVI. A Summary Diagram: Viewing Claude Code from the Perspective of Harness Engineering

17
XVII. Final Conclusion
Returning to the judgment at the end of your article:
The bottleneck is not intelligence; it is infrastructure.
The source code of Claude Code is almost a large footnote to this sentence.
Its most commendable aspect is not how many tools, Agents, or modes it has, but that it has effectively achieved the following:
01 Context Architecture: It doesn’t just stuff context in; it continuously governs it. 02 Runtime-based Roles: Agents are not just prompts, but runtime specifications with tool boundaries, memory, permissions, and isolation strategies. 03 Structured Execution: Planning, execution, verification, recovery, and notifications are no longer mixed together. 04 Task-as-First-Class: Agents are incorporated into the Task system, gaining lifecycles, visibility, and recoverability. 05 Centralized Control: Multiple Agents can execute in a distributed manner, but ultimate control returns to the main interface that the user can understand. 06 Productized Harness: It doesn’t just build guardrails in the background; it turns guardrails into a user-perceivable control plane.
So, if you must answer “what actual Harness optimizations has Claude Code made,” the most accurate answer is not a scattered checklist, but the following:
Claude Code has pushed Harness Engineering from “documents and conventions” to “runtime and product structure” itself.
It is not just telling the Agent what to do; it is striving to construct an environment where:
- It is easier for the Agent to do it right.
- It is harder to do it wrong.
- Recovery is possible if it goes wrong.
- Multiple Agents do not lose control when working simultaneously.
- The user always knows what the system is doing.
If Harness Engineering truly represents a paradigm revolution in software engineering in the AI Agent era, then Claude Code is no longer a bystander to this revolution, but a concrete, solid, and representative implementation sample.
Of course, it hasn’t filled all the gaps:
- Long-term project structured progress management can still be stronger.
- Mechanized execution of repo-level architectural constraints still has room for improvement.
- Long-term AI slop cleanup and maintainability guarantees can still be more productized.
But this does not affect the overall judgment.
Because what truly matters is that it has crossed the watershed:
From “making the model able to write code” to “designing a system that allows the model to reliably write code over the long term.”
This is the core of Harness Engineering.
18
Appendix: One-Sentence Summary
If you only remember one sentence, remember this:
The most important optimization in Claude Code is not making the Agent freer, but placing the Agent’s freedom into a governable, observable, recoverable, and verifiable engineering Harness.
