Digital Strategy Review | 2026
Decoding the Top 10 Highlights of Claude Code 10 | Verification Agent: It Doesn’t Just Take a Polite Look, It Actively Hunts for Failure
By Uncle Fruit · Reading Time / 8 Min
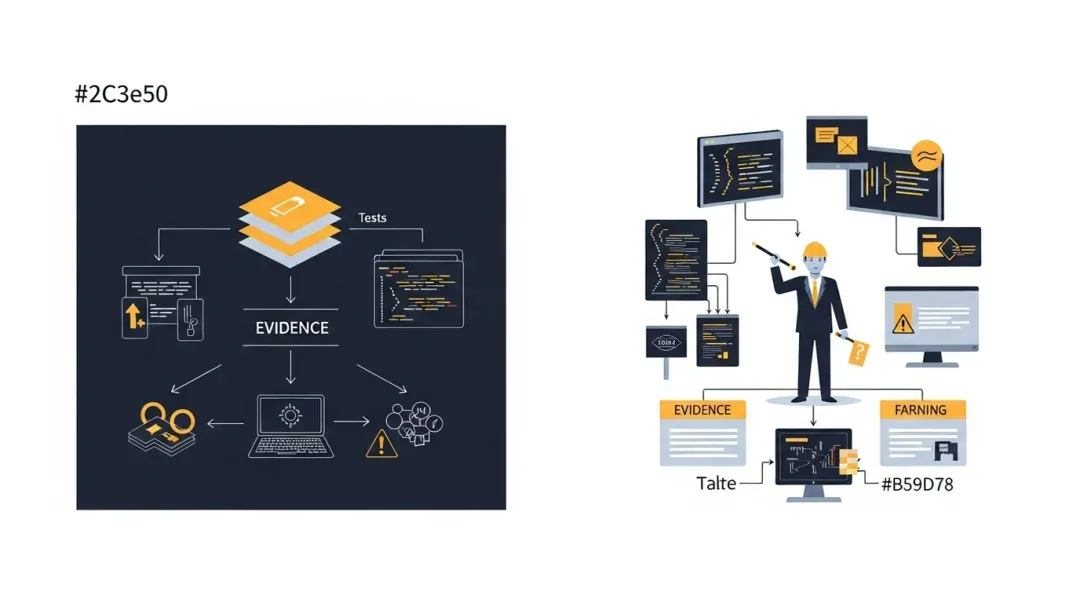
Foreword
Many systems claim to perform verification, but the real challenge is whether that verification can consistently counter the model’s own tendency to cut corners. This installment is worth a dedicated conclusion, as Claude Code reveals a more honest and engineering-driven approach to verification.
01
Verification Agent: Not a polite glance, but an active hunt for failure
Many AI coding systems claim they can “verify results.” But the reality is often:
• Take a look at the code. • Run a test. • Write a note saying, “Should be fine.”
Claude Code’s attitude toward this is significantly more rigorous. It didn’t design the verification agent as just another gentle reviewer; it designed it as a validator specifically tasked with countering the tendency toward laziness and misjudgment.
The core implementation is concentrated in:
• src/tools/AgentTool/built-in/verificationAgent.ts
02
I. What makes this Agent unique: It counters the LLM’s own weaknesses
The problem with many verification agents isn’t a “lack of capability,” but a “tendency toward error.”
Typical tendencies include:
• Feeling it’s “good enough” after reading the code. • Wanting to give a PASS as soon as a test passes. • Reluctance to actually perform complex checks. • Giving up immediately when encountering environmental limitations.
Claude Code’s verification agent prompt directly targets these weaknesses:
• Explicitly points out “verification avoidance.” • Explicitly points out the trap of being misled by the first 80% of “looks like it works.” • Mandates running commands, pasting output, and providing a verdict.
This isn’t just standard prompt engineering; it is a realistic countermeasure against LLM behavioral patterns.
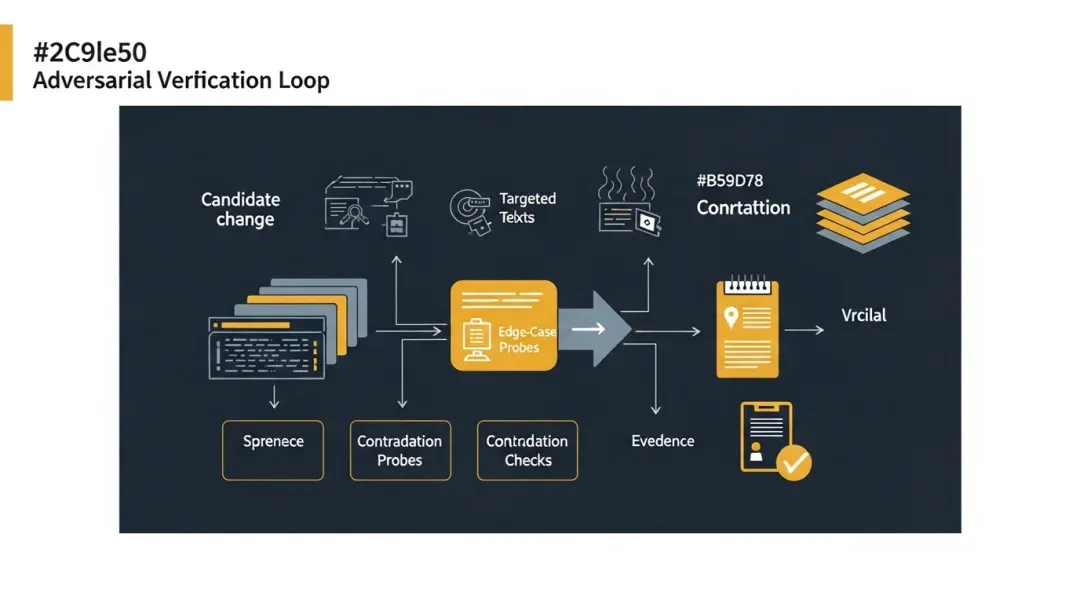
What is most impressive about Claude Code is its willingness to turn verification into a process that actively resists its own inclination to slack off.
03
II. It doesn’t ask for “more tests,” it asks for “evidence-based verification”
The most valuable aspect of Claude Code’s verification agent is that it does not accept vague judgments; it demands evidence.
Specifically:
• Every check must specify a command run.
• It must provide observed output.
• It must explicitly state PASS / FAIL / PARTIAL.
• It cannot rely solely on reading the code to reach a conclusion.
This pulls verification back from “impression-based judgment” to “judgment based on execution evidence.”
For a coding agent system, this is critical. Because the more powerful the system and the more it can change, the less it can rely on “it feels right” to wrap up a task.
04
III. Its strategy design is also highly mature
This Agent isn’t just a vague “go verify this.” It provides different verification paths for different types of changes:
• frontend changes • backend / API changes • CLI / script changes • infra / config changes • library changes • bug fixes • mobile • data / ML pipeline • database migrations • refactor
This shows that Claude Code doesn’t treat verification as a one-size-fits-all template, but acknowledges:
Different types of software changes naturally require different verification methods.
This is a highly engineering-oriented perspective.
05
IV. It even requires adversarial probes
I believe one of the most interesting parts of this Agent prompt is that it isn’t satisfied with “happy path” verification; it requires at least one type of adversarial probe, such as:
• Concurrency • Boundary values • Idempotency • Non-existent object operations
This step is vital because many LLM “verifications” stop at:
• The feature runs once. • Therefore, it is finished.
Claude Code explicitly requires it to try and break the system. This is much closer to serious engineering verification.
06
V. Why this enhances the credibility of the entire system
Claude Code doesn’t just treat the verification agent as an add-on; it treats it as a “credibility amplifier” before completion.
The reason is simple:
• The main Agent may be overly optimistic. • The execution Agent may be biased toward proving its own success. • True verification should maintain a separation of interests.
Thus, the verification agent is designed to be:
• More skeptical in its role. • More adversarial in its goals. • More evidence-based in its form.
This ensures it isn’t just “polishing the main Agent’s conclusions,” but truly acting as a quality gatekeeper.
07
VI. It also reflects Claude Code’s product honesty
Many products like to claim “we will automatically verify your code,” but they rarely handle the following issues seriously:
• What to do when there are no tests? • What to do when a command fails? • What to do when the environment is insufficient? • What to do when there is no browser for frontend tasks?
Claude Code’s verification agent doesn’t dodge these realities; instead, it:
• Clearly defines the boundaries of PARTIAL.
• Encourages checking MCP/browser capabilities.
• Requires an explanation of which verifications cannot be done and why.
This might make the results look less “perfect,” but they are more honest and usable.
08
VII. Why this highlight is worth studying on its own
Because it illustrates something many teams tend to overlook:
The quality of an LLM system depends not only on whether it can generate results, but also on whether it is designed to be willing to doubt those results.
The verification agent institutionalizes this “skepticism mechanism.”
This is a characteristic that is difficult to grow naturally from general model capabilities; it must be deliberately constructed through system design.
09
VIII. Understanding this highlight in one diagram
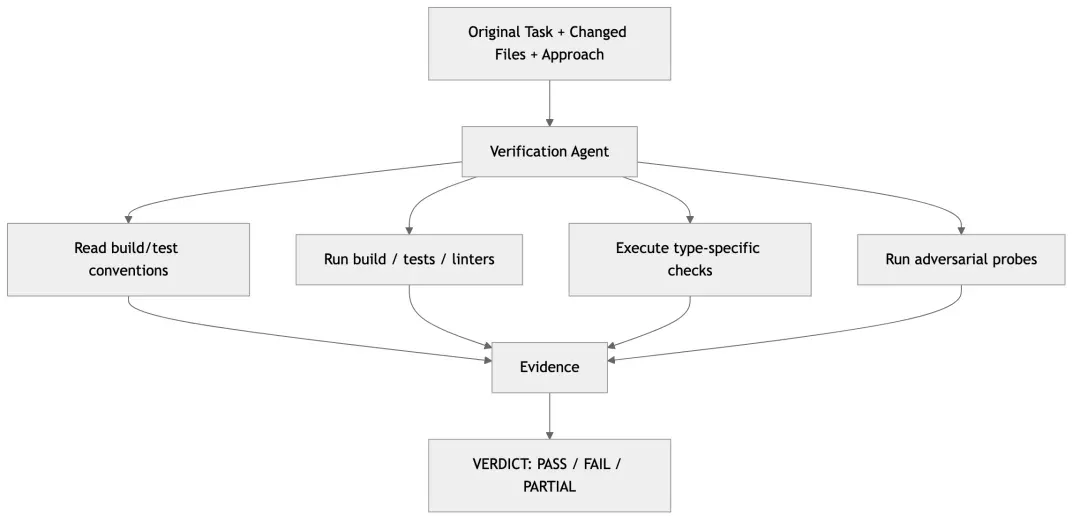
10
IX. Conclusion
The true value of the verification agent lies not in “running a few more commands,” but in turning a step that is easily glossed over by an LLM into an institutionalized, evidence-based, and adversarial process.
This ensures that when Claude Code says it is “finished,” it isn’t just the main Agent claiming success—it is backed by a role specifically tasked with finding faults.
In a nutshell:
Claude Code doesn’t make verification more polite; it makes verification harder to fool.
