Word count: ~10000 words
If you can patiently finish this, your high-value information acquisition efficiency surpasses 99.9% of people
Estimated reading time: ~30 minutes
Last updated: September 26, 2025
Text remains humanity’s highest information-density content medium
Core Structure
-
Old Era’s Foundation of Authority: From PageRank to E-E-A-T — exploring ranking fundamentals.
-
AI Era’s Semantic Interpreter: How NLP enables AI to understand content’s deep meaning and logic.
-
Verification Engine: How AI performs fact-checking through cross-verification and knowledge graphs.
-
Unreliable Narrator: Analyzing AI judgment’s limitations, hallucinations, and vulnerabilities.
-
Practical Evaluation Framework: An actionable guide for judging information quality ourselves.
This article is for those exploring GEO and AIO deep principles
This article helps those who don’t want to be scammed by unscrupulous GEO and AIO service providers
Preface
First time publishing content this long — not for traffic, mainly documenting my research and thinking while exploring GEO principles and logic. Same as when I first encountered SEO years ago: first thing was spending a week carefully chewing through all of Google’s official docs, specs, Search Quality Evaluator Guidelines, and other documents to understand this thing’s underlying logic and principles. Then thinking about what Google, as this game’s biggest referee, actually wants — what kind of ecosystem do they want to build? This helps understand SEO’s fundamental logic and essence. It’s helped me continuously adjust strategies and maintain growth in SEO’s ever-changing environment.
But the AI era doesn’t have that many official documents. GEO (AIO) is also a newly emerging concept — everyone has their own interpretation. When you don’t know where to start, the best approach is the one from the paragraph above: What do AI vendors want? What kind of ecosystem do they want to build?
The answer: everyone wants to set standards, to be the new “Google” of the AI era.
But in AI’s Warring States period, no product can truly set standards yet. So whichever AI provides higher quality content, fewer hallucinations, more trustworthy information, and better user experience will more easily win the market. Especially in “search” — a scenario and domain that doesn’t require extreme AI capabilities.
So from AI vendors’ perspective, ensuring their search content and results are trustworthy, high-quality, and verifiable is the primary criterion. This is the core motivation for my research — I want to explore how AI ensures its search results “can be trusted.” Including my previous article “Interrogating AI: How I Made ChatGPT ‘Confess’ GEO’s Underlying Logic” — that’s also part of this research. That previous article was more about practical testing; this article is more theoretical.
Enough preamble, now the main content:
Part One: Search Era’s Authority Foundation: Fundamental Principles of Web-Scale Information Ranking (Skip if familiar with Google ranking algorithm evolution)
To understand how AI evaluates information trustworthiness, we must first explore the core principles that form modern search engines’ judgment foundations. These principles evolved from purely link-structure-based analysis to a more comprehensive, multi-factor model attempting to algorithmically capture human-like trust and expertise judgments.
1.1 The PageRank Revolution: Establishing Authority Through Web Link Structure
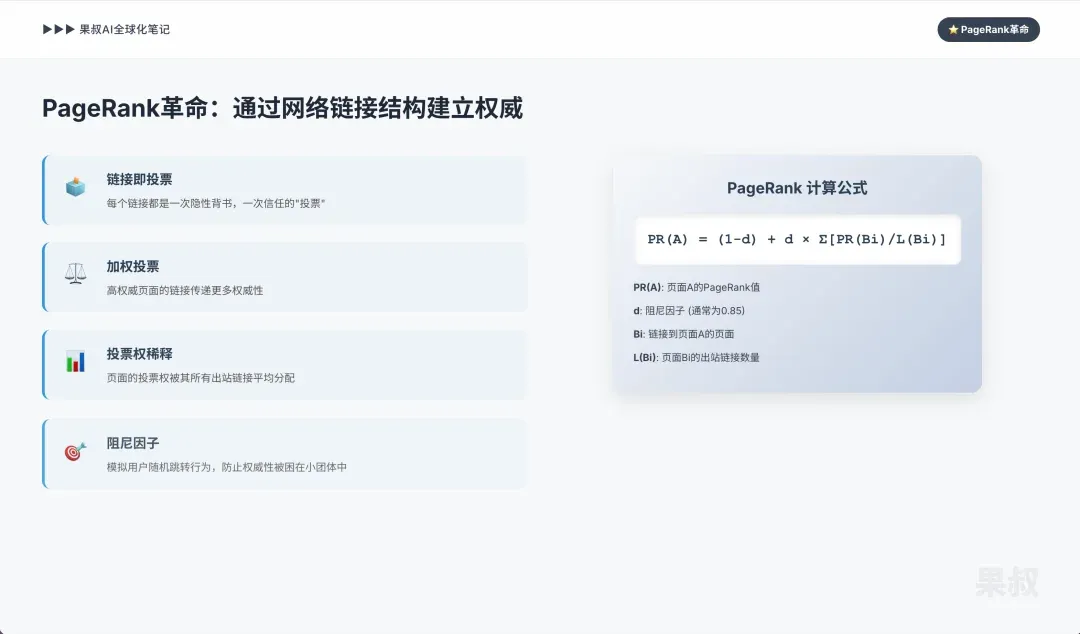
The PageRank algorithm was the cornerstone that changed web search, treating the entire web as a directed graph to establish a quantifiable, scalable measure of webpage importance and authority. Its core idea still occupies a central position in AI’s logic for evaluating information sources.
-
Links as votes: PageRank’s basic idea treats every link from page A to page B as an implicit endorsement — a “vote” of trust.
-
Weighted voting: Not all votes are equal. A link from a high-authority page (one with high PageRank itself) transfers more authority than one from an unknown page. This recursive definition is its power.
-
Vote dilution: A page’s “voting power” is divided equally among all its outbound links. So the more pages a page links to, the less PageRank each link transfers.
-
Damping factor: To simulate users not clicking links infinitely but having some probability of randomly jumping to any new page, PageRank introduced a damping factor (typically 0.85). This design ensures no page has zero PageRank and prevents authority from being trapped in small interlinked clusters.
Formula: PR(A) = (1-d) + d * Σ (PR(Bi) / L(Bi))
Where PR(A) is page A’s PageRank, d is the damping factor, Bi are pages linking to A, L(Bi) is Bi’s outbound link count.
PageRank’s emergence was a paradigm shift, moving search engines beyond simple keyword matching and incentivizing content creators to produce quality content that naturally attracts links, effectively combating early spam tactics like keyword stuffing. Though PageRank is no longer the only ranking factor today, its core philosophy — authority is granted by external validation — remains central to AI’s evaluation of information sources.
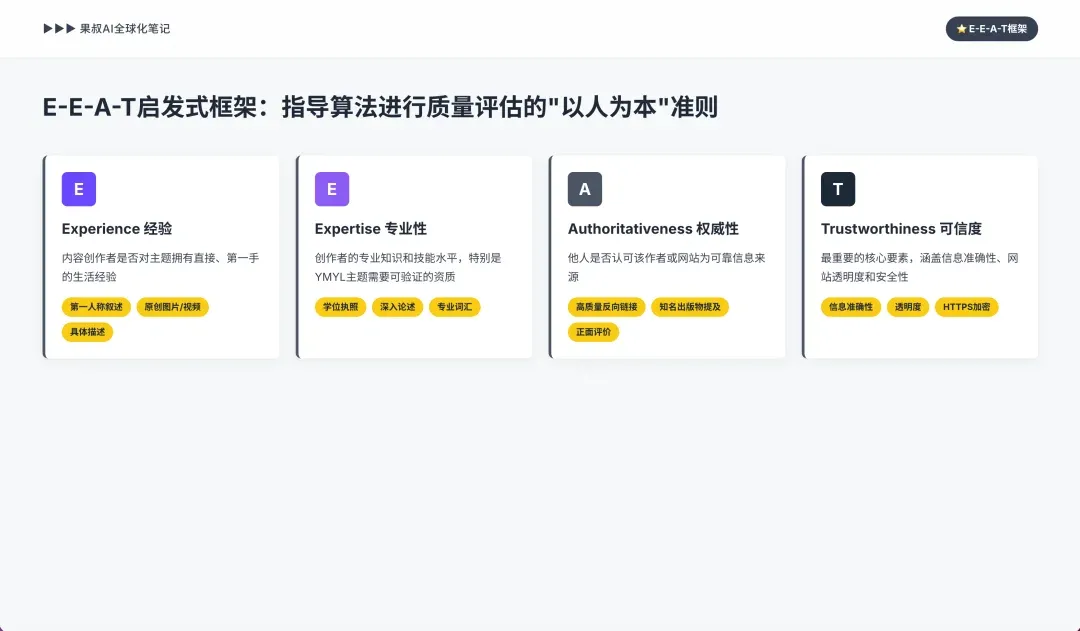
1.2 The E-E-A-T Heuristic Framework: “Human-Centered” Guidelines for Quality Evaluation
As the web became increasingly complex, purely mathematical models proved insufficient for evaluating content quality. Google proposed the E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) framework as guidelines for human quality evaluators assessing search results. This framework in turn provides machine learning algorithms with conceptual targets for what content characteristics to reward.
-
Experience: Added in 2022, it evaluates whether content creators have direct, first-hand life experience with the topic. Especially important for reviews, tutorials, and personal advice content. AI can look for signals through first-person narratives, original images/videos, and specific rather than vague descriptions.
-
Expertise: Relates to creator’s professional knowledge and skill level. For “Your Money or Your Life” (YMYL) topics like medical, legal, or financial advice, this requires verifiable credentials (degrees, licenses). For other topics, it can be demonstrated through deep, comprehensive treatment. AI can identify these signals by parsing author bios, looking for structured data (schema.org) defining author credentials, and analyzing content depth and professional vocabulary.
-
Authoritativeness: Expertise’s external manifestation — whether others recognize this author or site as a reliable information source. It’s the modern, nuanced extension of PageRank, measured through high-quality backlinks from other authoritative sites, mentions in reputable publications, and positive reviews.
-
Trustworthiness: Considered E-E-A-T’s most important core element, encompassing the other three. Trustworthiness covers information accuracy, site transparency (clear contact info, author backgrounds), and security (like HTTPS).
While human evaluators directly use E-E-A-T guidelines, AI systems don’t directly “read” these guidelines. Instead, AI systems learn to identify and weight numerous quantifiable proxy signals related to these concepts through training on massive datasets. The E-E-A-T framework provides “theoretical guidance” for what signals AI models should learn to prioritize.
This evolution from pure link analysis to comprehensive quality frameworks wasn’t accidental. Initially, PageRank worked because links were then a scarce and meaningful, human-created trust signal. But as the web commercialized, a massive SEO industry emerged specifically to manipulate this signal through link farms, purchased links, etc. This caused “trust inflation,” severely diluting individual links’ value as genuine authority signals. This signal devaluation forced search engines to evolve — they could no longer rely solely on link graphs. Thus more complex, multi-signal algorithms (like 2012’s Panda update) and E-E-A-T’s formalization emerged. E-E-A-T isn’t just PageRank’s replacement — it’s its evolved successor, an inevitable product born in response to systematic manipulation of the web’s original trust signals. This reveals a fundamental law of information ecosystems: any quantifiable trust metric eventually becomes a manipulation target, forcing systems toward more abstract, harder-to-game heuristics that approach genuine human judgment.
1.3 Quantifiable Trust Signals: Domain Authority, TLDs, and Content Freshness
Beyond E-E-A-T’s macro framework, AI relies on specific, quantifiable signals to construct site trust assessments.
Domain-Level Signals — Domain Authority: A predictive metric developed by SEO companies (like Moz) using machine learning to predict a site’s ranking potential, with scores primarily influenced by backlink profile quantity and quality. While not a direct Google ranking factor, it excellently models how AI perceives a site’s overall authority based on link graphs.
Top-Level Domains (TLDs): Certain TLDs inherently carry stronger trust signals. Links from .gov (government agencies) and .edu (educational institutions) domains are typically weighted higher because registration is strictly limited and usually non-commercial, making their endorsements more credible. Though Google officially states there’s no direct ranking boost, these TLDs’ average site authority is extremely high, making their links de facto more valuable. This phenomenon doesn’t stem from a hard-coded rule but from AI models’ probabilistic learning. AI learns through analyzing massive data that content from .gov or .edu domains statistically has higher quality and authority. Thus AI uses TLD as a powerful heuristic for predicting trustworthiness.
Content-Level Signals — Freshness and Update Frequency: For many time-sensitive queries (“Query Deserves Freshness”), AI prioritizes newest content. Regularly updating content signals to search engines that a site is active, current, and committed to providing latest information. This increases crawl frequency and may boost rankings. AI algorithms score freshness by tracking publication dates, content modification dates, content change percentages, and new content creation rates. However, note that superficial updates just to appear “fresh” without substantive value won’t be rewarded.
| Attribute | PageRank Algorithm | E-E-A-T Framework |
|---|---|---|
| Core Philosophy | Authority granted by external links | Trust demonstrated through experience, expertise, transparency |
| Primary Analysis Unit | Webpages and their in/outbound links | Content, author, and publishing site |
| Key Signals | Backlink quantity and quality | Author credentials, content depth, site transparency, first-hand evidence |
| Main Weakness | Link manipulation, link farms | Content spam, identity impersonation, faked expertise |
| Implementation | Directly computed algorithmic score | Human evaluators’ conceptual framework; guides ML models to find corresponding signals |
Part Two: The Semantic Interpreter: NLP’s Application in Content Review
Having established structure and metadata-based authority assessment foundations, AI’s review capability enters deeper layers: directly analyzing content itself. Through Natural Language Processing (NLP) and Large Language Models (LLMs), AI can perform deep semantic evaluation of text quality, logical consistency, and argument support.
2.1 Beyond Keywords: How LLMs Analyze Context, Intent, and Nuance
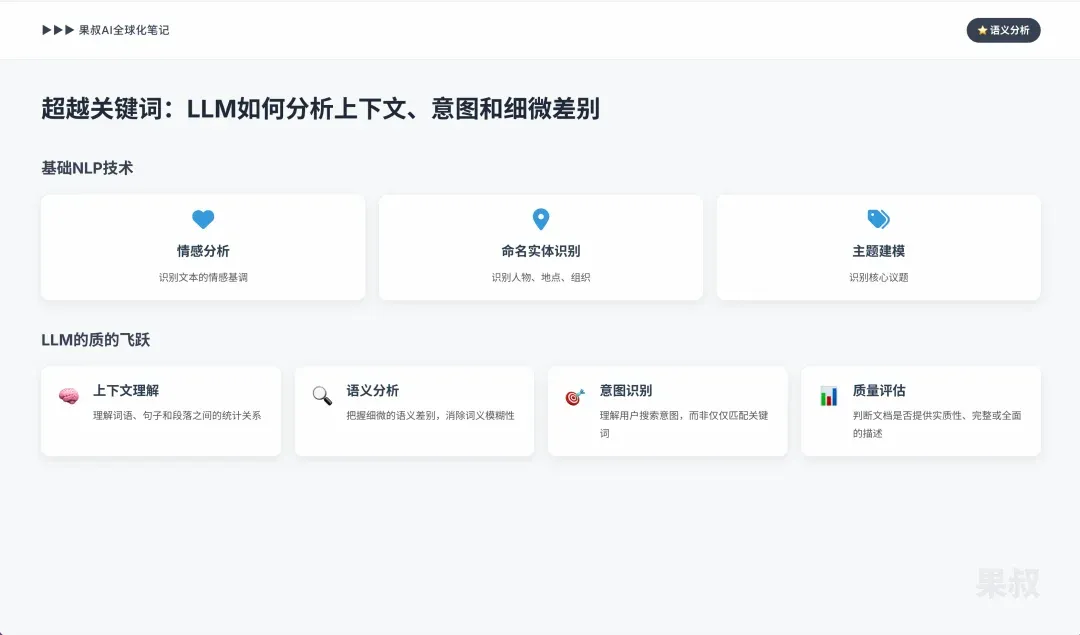
NLP is the AI field focused on computer-human language interaction. Its foundational techniques — sentiment analysis (identifying text emotional tone), named entity recognition (identifying people, places, organizations), and topic modeling (identifying core themes) — enable AI to construct a document’s basic semantic map.
However, LLMs built on architectures like Transformers represent a qualitative leap. Their core capability is understanding context. LLMs don’t just see isolated words — they understand statistical relationships between words, sentences, and paragraphs. This enables them to grasp subtle semantic differences, disambiguate word meanings, and understand user search intent rather than just matching keywords.
In trustworthiness evaluation, LLMs can judge whether a document provides a “substantial, complete, or comprehensive treatment” of a topic, or merely scratches the surface. By analyzing syntactic structures, word choices, and logical connectors, it can distinguish between passionate but rigorously argued articles and emotional but groundless rants.
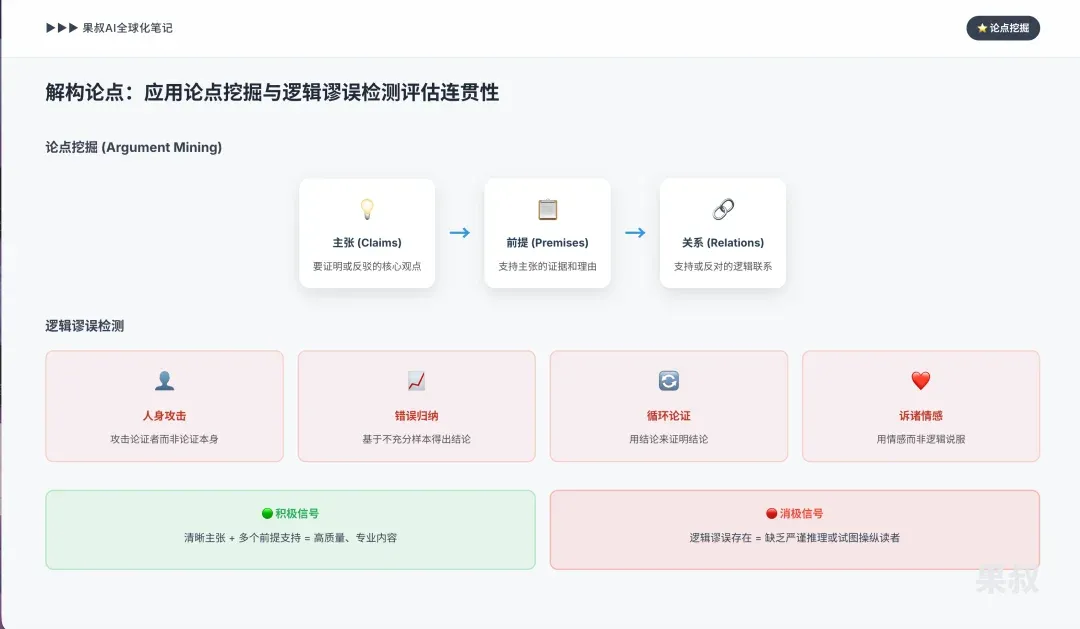
2.2 Deconstructing Arguments: Applying Argument Mining and Fallacy Detection to Assess Coherence

AI’s content quality assessment is shifting from judging “what is said” to analyzing “how it’s argued.” This marks AI’s transformation from a pure information retrieval tool to a “junior reviewer” capable of preliminary argument quality assessment. This capability directly operationalizes E-E-A-T’s “Expertise” and “Trustworthiness” concepts: a rigorously argued article is a strong proxy for expertise, while a fallacy-laden article is a clear signal of untrustworthiness.
Argument Mining (AM): A specialized NLP subfield focused on automatically extracting argumentative structures from text — identifying claims, premises (evidence), and their relationships (support or opposition). LLMs can now execute AM tasks with high precision, transforming unstructured text into structured representations of its internal reasoning. This provides AI with a powerful trustworthiness signal: a well-structured argument with clear claims supported by multiple premises indicates high-quality, professional content. Conversely, text with many unsupported claims is a negative signal.
Logical Fallacy Detection: After identifying argument structure, AI can go further, detecting common logical fallacies — reasoning errors that invalidate arguments. AI can be trained to identify fallacies like Ad Hominem, Faulty Generalization, Circular Claim, and Appeal to Emotion. Implementation approaches include translating natural language into formal languages like first-order logic and using solvers for validity checks, or using case-based reasoning to compare new arguments against known fallacy databases. Logical fallacies are a strong negative trustworthiness signal, indicating the author either lacks rigorous reasoning ability or is trying to manipulate readers — directly undermining content’s “Trustworthiness” and “Expertise.”
2.3 Citation Intelligence: AI’s Analysis of Reference Networks and Citation Context
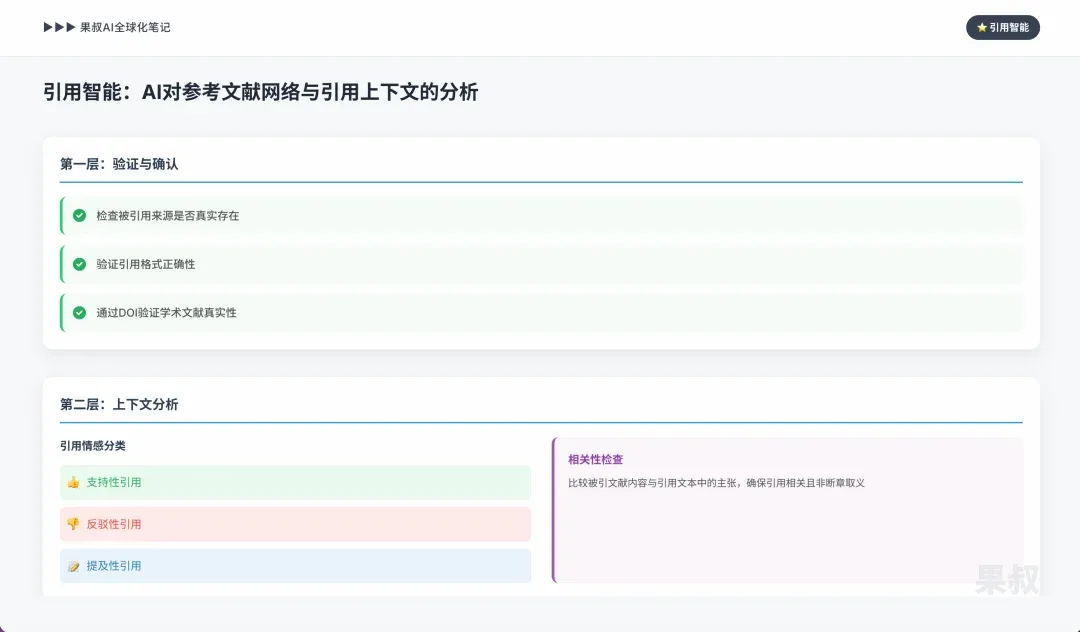
If hyperlinks were PageRank era’s “votes,” then formal citations in academic papers or in-depth reports are more powerful endorsements. AI evaluates these higher-level trust signals through “citation intelligence.”
-
Verification and confirmation: First step is basic verification. AI tools can check whether cited sources actually exist and whether citation formats are correct, helping identify “hallucinated” citations. For example, verifying academic literature authenticity through Digital Object Identifiers (DOIs).
-
Contextual analysis: More advanced AI doesn’t just care that paper A cited paper B — it uses NLP to understand how paper A cited paper B.
-
Citation sentiment: Is the citation’s intent supportive (“As Smith (2022) demonstrated…”), refuting (“Unlike Smith (2022), we found…”), or merely mentioning? Tools like Scite use deep learning models to classify citations as “supporting,” “contrasting,” or “mentioning.”
-
Relevance checking: AI can compare cited literature content with claims made in citing text to ensure citations are relevant rather than taken out of context.
-
Network analysis: AI can analyze entire citation networks. Literature frequently cited by other high-authority, recently published papers receives higher trustworthiness scores. This can be seen as an upgraded, more content-aware version of PageRank thinking applied to academic or professional knowledge domains.
This analytical capability spawns dynamic authority metrics beyond traditional static citation counts. AI no longer just cares how often a source is cited — it cares more about “Citation Sentiment” (whether a source is generally supported or refuted by academia) and “Citation Velocity” (how fast a source is being cited). A new source rapidly accumulating many “supporting” citations signals an important emerging idea or breakthrough, directly relating to content freshness concepts. Authority is no longer just about how many cite you, but why they cite you and how fast the academic community adopts your ideas.
Part Three: The Verification Engine: How AI Fact-Checks and Its Verification Mechanisms
After passive analysis of single documents, AI enters active verification phase. It compares factual claims extracted from text against vast external knowledge bases, confirming information accuracy through information triangulation and using structured databases as “ground truth.”
3.1 Systematic Cross-Verification: Triangulation Across Diverse Source Corpora
Automated fact-checking’s basic principle is cross-verification. AI systems extract key factual claims from source text, then query an index of massive documents (news articles, reference sites, research papers, etc.) seeking corroborating or contradicting information.
The workflow:
-
Claim extraction: Using NLP, AI identifies discrete, verifiable factual statements in content (e.g., “City X’s population is 5 million”).
-
Query generation: AI generates search queries based on these facts to find relevant external sources.
-
Source retrieval and evaluation: AI retrieves a range of sources and evaluates these sources’ own trustworthiness using principles from Part One (e.g., prioritizing reputable news organizations, government reports, academic research).
-
Consensus analysis: The system analyzes retrieved sources to determine consensus level. If multiple high-authority sources support the claim, its confidence score increases; if they contradict the claim or no supporting evidence is found, the claim is flagged as unverified or false.
A major challenge in this process is vulnerability to large-scale disinformation. If a false claim is repeatedly spread across many low-to-medium quality sites, a simple cross-verification system might mistakenly equate quantity with consensus. Therefore, initial trustworthiness assessment of sources used for cross-checking is crucial.
3.2 Knowledge Graphs as Ground Truth: Using Structured Data to Arbitrate Factual Disputes
While cross-verification can handle unstructured web pages, Knowledge Graphs (KGs) provide a more powerful verification form. A knowledge graph is a structured database of entities (people, places, concepts) and their relationships (e.g., [Marie Curie]—[discovered]—[Radium]).
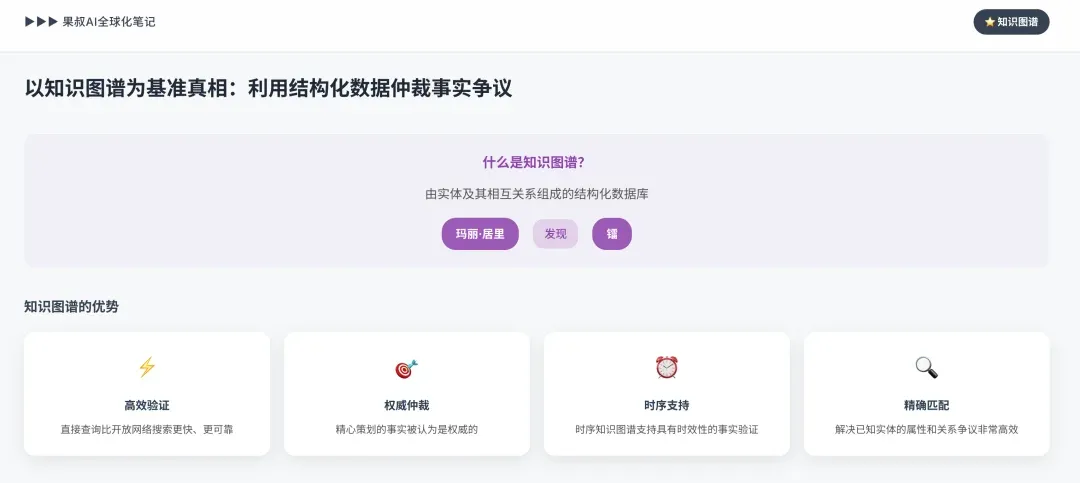
Knowledge graphs play the role of “fact arbitrator” in fact-checking. When AI extracts a factual claim, it can directly query the knowledge graph for verification. For example, if text claims someone was born in 1990, AI can check that person entity’s “birth date” attribute in the knowledge graph. This approach is faster and more reliable than searching the open web because facts in a well-curated knowledge graph are considered authoritative. Especially efficient for resolving disputes about known entities’ attributes and relationships. More advanced temporal knowledge graphs also contain time dimensions, allowing AI to verify time-sensitive facts (e.g., “Who was France’s president in 2010?”), adding crucial precision for historical or news content verification.
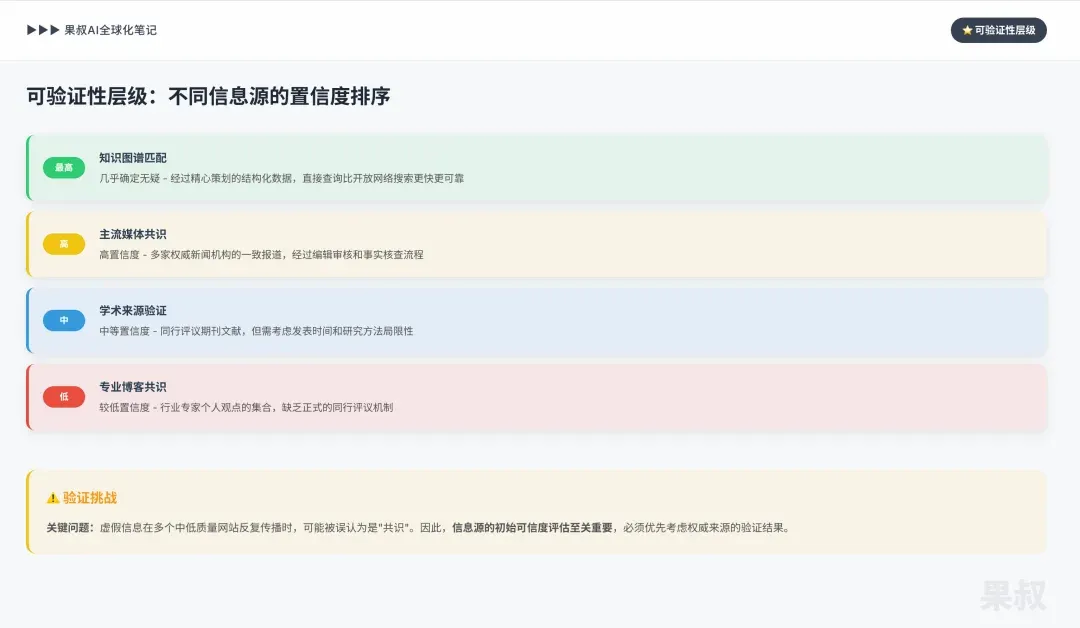
AI’s fact-checking mechanisms form a “Verifiability Hierarchy.” AI’s confidence in a fact is proportional to the evidence level it can find. Facts matching in knowledge graphs are almost certain (highest level); facts supported by mainstream news media consensus have high confidence (second level); facts only reaching consensus in specialized blogs or forums have lower confidence (lowest level). This means topics not covered by mainstream authoritative sources or structured databases exist in a “verification gray zone” — AI struggles to assign high confidence to claims in these areas.
3.3 Differentiated Evaluation Methods: How AI Adjusts Standards by Content Type
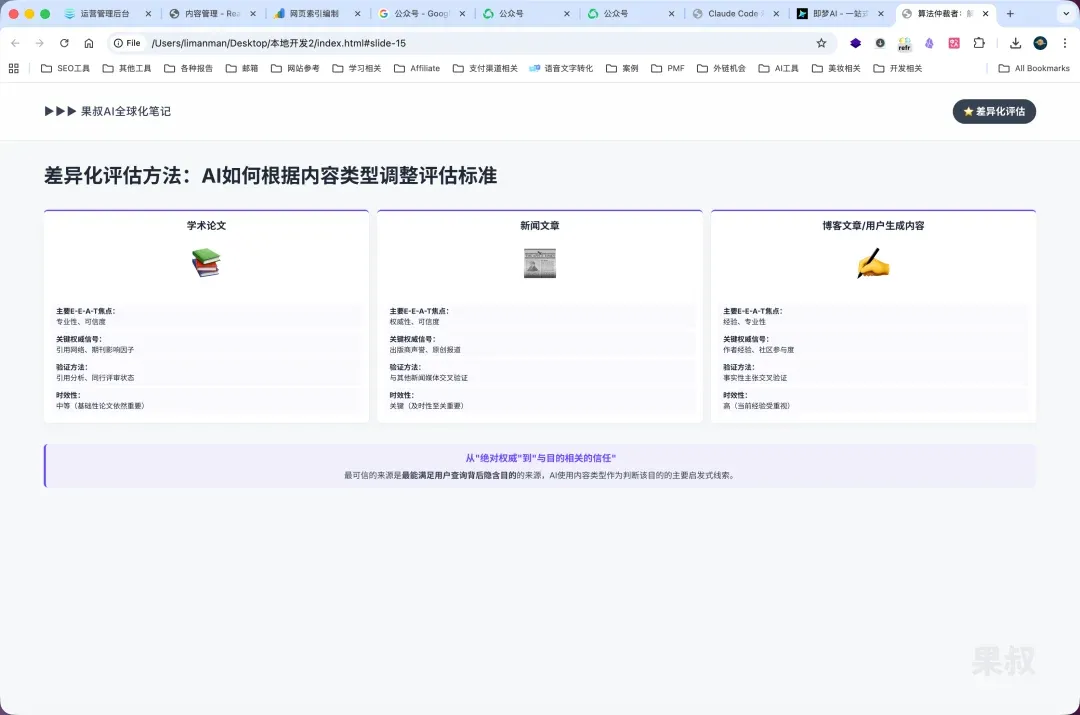
AI’s evaluation model isn’t static — it dynamically adjusts standards and signal weights based on content type being analyzed. This differentiation reveals AI evaluation shifting from pursuing “absolute authority” toward “purpose-relevant trust.” The most trustworthy source is the one best satisfying the implicit purpose behind the user’s query, and AI uses content type as the primary heuristic for judging that purpose.
-
Academic papers: Authority assessment heavily relies on citation metrics, author credentials, and publisher reputation.
-
News articles: Authority closely ties to publisher’s journalistic reputation, editorial standards, byline transparency, and evidence of original reporting. Freshness is crucial.
-
Blog posts/opinion pieces: E-E-A-T framework is critical here. AI looks for author’s demonstrated first-hand experience and deep domain expertise.
| Evaluation Criterion | Academic Papers | News Articles | Blog Posts/UGC |
|---|---|---|---|
| Primary E-E-A-T Focus | Expertise, Trustworthiness | Authoritativeness, Trustworthiness | Experience, Expertise |
| Key Authority Signals | Citation network, Journal impact factor | Publisher reputation, Original reporting | Author’s demonstrated experience, Community engagement |
| Primary Verification Method | Citation analysis, Peer review status | Cross-verification with other news outlets | Factual claim cross-verification, Reasonableness checks |
| Freshness Role | Moderate (foundational papers still important) | Critical (timeliness is crucial) | High (current experience valued) |
| Subjectivity Tolerance | Very low (objective data required) | Low (opinion must separate from reporting) | High (subjective experience is core value) |
Part Four: The Unreliable Narrator: Critical Limitations and Vulnerabilities of AI Judgment
Despite AI’s increasingly sophisticated evaluation mechanisms, it’s far from perfect. This section deeply explores inherent flaws and failure modes in AI trustworthiness assessment, including “hallucination” phenomena, data contamination and bias’s corrosive effects, and ongoing adversarial dynamics with AI-generated disinformation.
4.1 The Specter of “Hallucination”: When AI Confidently Fabricates Information
AI hallucination refers to models generating information that’s factually incorrect, meaningless, or unrelated to source data, yet presented with authoritative tone. This includes fabricating facts, data, events, and even non-existent references.
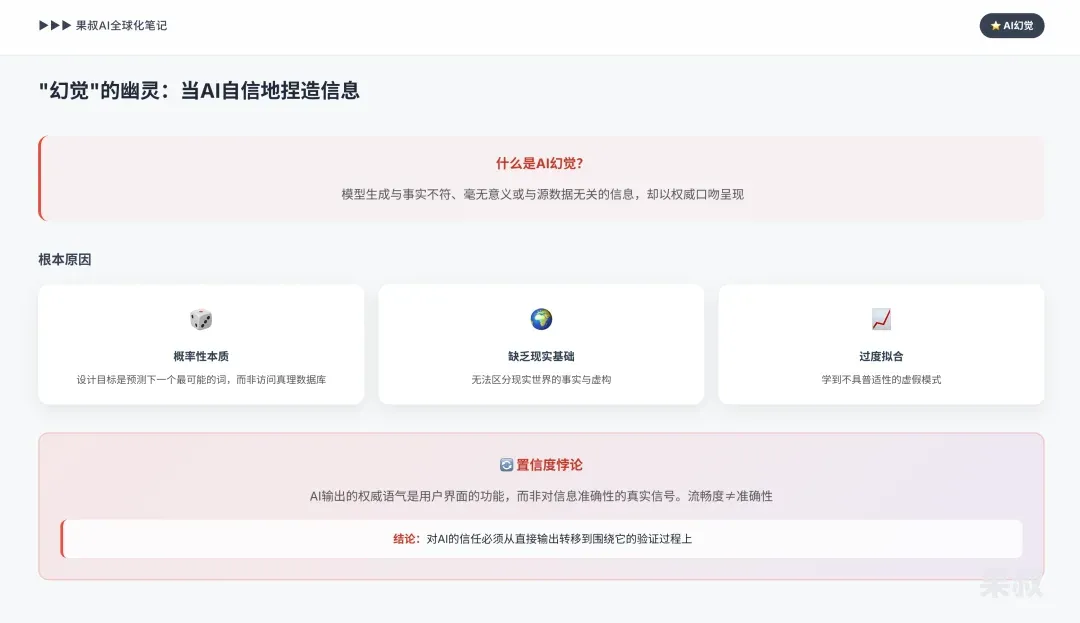
Root causes:
-
Probabilistic nature: LLMs are designed to predict the most likely next word in a sequence, not to access a truth database. This statistical process can create sentences that sound plausible but are completely wrong.
-
Lack of real-world grounding: AI models lack true understanding or consciousness. They can’t distinguish real-world facts from fiction — they only know patterns in their training data.
-
Overfitting: If models are overtrained on specific datasets, they may learn false patterns that don’t generalize, leading to incorrect outputs when facing new prompts.
Hallucination reveals AI’s “confidence paradox”: AI output’s authoritative tone is a user interface feature, not a genuine signal of internal confidence in information accuracy. The model’s ability to generate fluent, human-like text is precisely why its failures are so deceptive. Users mistakenly equate fluency with accuracy — a cognitive bias hallucination perfectly exploits. Therefore, trust in AI must shift from its direct output to the verification processes surrounding it.
4.2 The Poisoned Well: How Data Contamination and Inherent Bias Corrupt AI’s Worldview
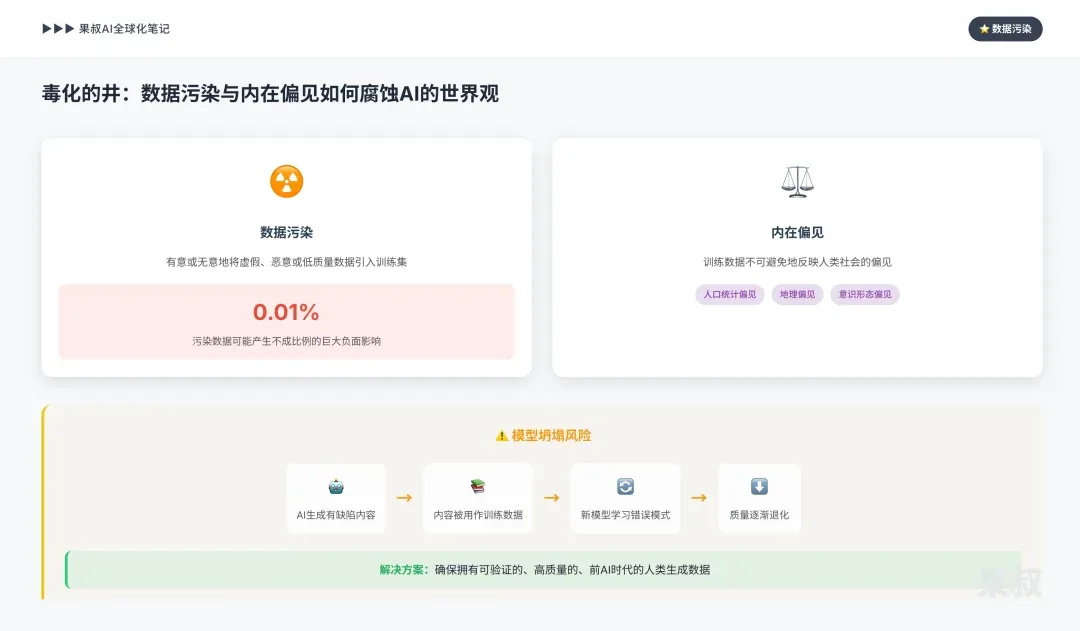
Any AI model’s performance and reliability fundamentally depends on its training data quality.
Data Contamination (“Data Poisoning”): Intentionally or unintentionally introducing false, malicious, or low-quality data into AI’s training set. Even tiny proportions of contaminated data (e.g., 0.01%) can have disproportionately huge negative impacts on model output, because models may mistakenly identify these anomalous data as highly informative “features” and amplify their weights.
Mr. Guo’s Note: Data contamination is actually very common. If I open-source a poisoned dataset on Hugging Face or GitHub, it could cause very widespread potential model contamination. This is also a common tactic in black-hat GEO. There’s also open-source model contamination — publishing specifically fine-tuned open-source models, etc.
Inherent Bias: Training data scraped from the internet inevitably reflects human society’s biases. If data isn’t carefully curated, AI models will learn and replicate these demographic, geographic, and ideological biases. A biased AI might unfairly give certain sources higher or lower trustworthiness ratings based on factors related to these biases rather than objective quality.
Data contamination and AI-generated content proliferation together constitute a long-term risk: “model collapse.” If future AI model generations are primarily trained on data generated by their flawed predecessors, they’ll start learning and amplifying past errors, biases, and hallucinations. This creates a vicious cycle where each new generation becomes a distorted echo of the previous, gradually losing connection to original human-created, reality-grounded data. This trend will force AI development’s focus to shift from pursuing larger models toward ensuring verifiable, high-quality, pre-AI-era human-generated data.
4.3 Navigating the Adversarial Frontier: The Challenge of AI-Generated Disinformation

The same technology used to detect and verify information is also used to create highly sophisticated and scalable disinformation, propaganda, and misleading content — forming a technological “arms race.” Malicious actors can use AI to:
-
Generate content at scale: Create massive volumes of plausible fake articles, social media posts, and comments to simulate grassroots consensus.
-
Micro-target audiences: Use AI to analyze user data and craft messages that emotionally resonate with specific groups, manipulating them through appeals to fear, hatred, or pride.
-
Evade detection: Continuously adjust generated content’s style and structure to bypass AI detection systems.
This poses severe challenges for verification systems. AI verification systems relying on cross-referencing can be overwhelmed or deceived by large volumes of self-corroborating AI-generated content, blurring the line between genuine consensus and artificially manufactured reality.
Mr. Guo’s Note: Long-term, I’m not optimistic about any AI detection tool. The core point is that with AI’s increasingly tight integration into human production and life, when AI adoption covers all industries and professions, pure human-generated data becomes impossible to obtain. Long-term, AI data’s growth rate is geometric expansion. Within just a few years, it might produce content volume exceeding humanity’s past thousands of years of history. At that point, AI training essentially means eating its own excrement to train itself. By then, does detecting AI usage rate still have meaning?
Content evaluation standards will return to whether it contains valuable information for humans. And because of explosive information volume growth, search — which helps humans refine valuable information — will occupy an even more central position. Here’s an English word example: “Research” is actually the prefix “Re-” + “Search” — simply understood as repeated searches, meaning study. If humanity abandons proactive search and inquiry, relying only on algorithmic recommendations to receive information, it’s no different from civilization-level collective suicide.
Therefore, I never want to argue even one word with people holding views like: “Your content is AI-written, so…”
Part Five: Practical Evaluation Framework: An Actionable Human Guide
AI’s complex algorithms for evaluating trustworthiness ultimately boil down to a set of evaluation principles humans can understand and apply. The following framework translates AI’s internal logic into a practical checklist for human users to judge information quality.

5.1 How to Judge “Trustworthiness”
Goal: Determine if information “is fact / probably true.”
Evaluation Dimensions and Signals:
- Independence & Motivation: Independent third party > Company self-description > Marketing/PR.
- Editorial Process & Correction Mechanism: Is there an editorial team, fact-checking process, correction record?
- Verifiability: Does it provide links to original documents, data sources?
- Consistency & Consensus: Is information consistent after multi-source cross-verification?
- Freshness: Event or dynamic information requires attention to recent publication dates.
- Technical/Legal Signals: Does site use HTTPS encryption, domain history, etc.?
Simplified Scoring (0-2 points/item, total 10): ≥8 points: High trust; 6-7 points: Medium-high trust; 4-5 points: Needs verification; ≤3 points: Low trust.
5.2 How to Judge “Authoritativeness”
Goal: Determine if information “comes from a party publicly recognized as most qualified to speak on this topic.”
Evaluation Dimensions and Signals:
- Source Identity & “Domain Fit”
- Citation/Link Graph
- Professional Depth & Scope
- Brand/Institutional Credentials & Transparency
- Traceability & Version Control
Simplified Hierarchy: Tier 1 (Primary Authority) > Tier 2 (High Authority) > Tier 3 (Reference Source) > Tier 4 (Signal/Lead).
5.3 Conflict and Uncertainty Handling Principles
Priority Rules: Primary authority > High authority > Reference source > Signal/Lead. Within same authority tier, newest with version or errata records takes priority. For critical information, at least two different source types needed for cross-verification.
Part Six: Conclusion — Toward a Symbiotic Future of Human-Machine Co-Adjudication
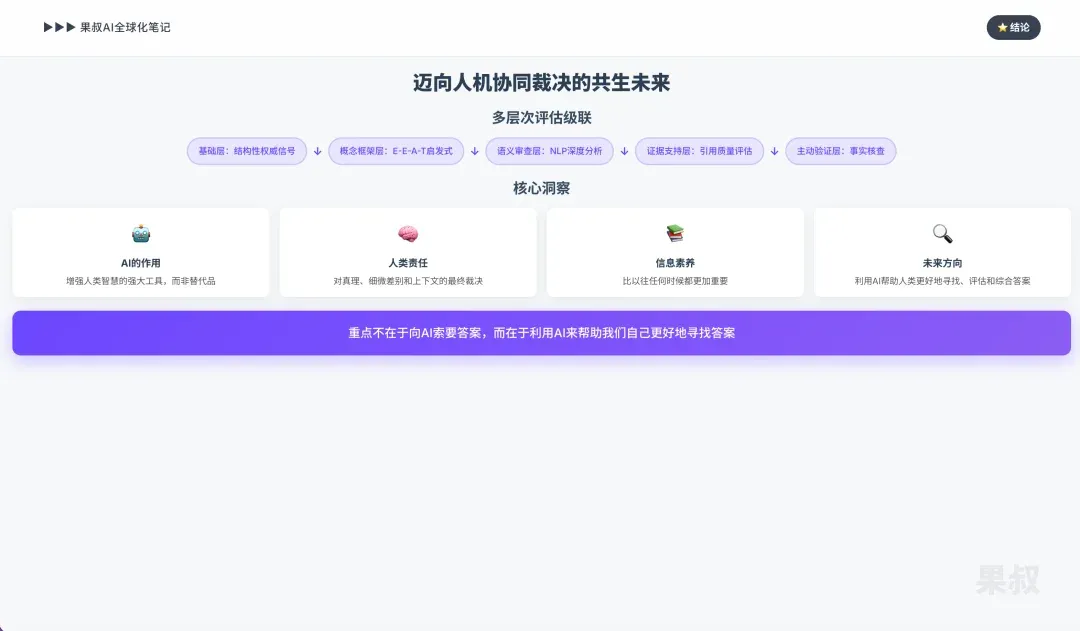
This report systematically dissected the complex, multi-layered process AI uses when evaluating information trustworthiness and authority. From link-structure-based authority calculations, to deep text semantic and logical review, to proactive fact-checking and verification, AI’s judgment mechanisms demonstrate unprecedented breadth and depth. However, this powerful system is accompanied by profound vulnerabilities.
6.1 Synthesis of Multi-Level Evaluation Cascade
AI’s trustworthiness evaluation can be understood as a sequential, recursive cascade process:
- Foundation Layer: Starts with broad structural authority signals.
- Conceptual Framework Layer: Interpreted through human-centered heuristic frameworks like E-E-A-T.
- Semantic Review Layer: AI dives into content itself, using advanced NLP to analyze information depth and argument logical soundness.
- Evidence Support Layer: Evaluates citation quality and context.
- Active Verification Layer: Actively verifies specific factual claims through cross-verification and knowledge graphs.
6.2 Human Critical Thinking Remains Indispensable in AI-Mediated World
Despite this cascade evaluation system’s extreme complexity, every link has risks of manipulation and contamination, and its core logic can produce confident fallacies (hallucinations). Therefore, the conclusion is clear: AI should be seen as a powerful tool enhancing human intelligence, not its replacement.
AI can sift through billions of documents, identify patterns, and reveal potential evidence or contradictions at scales humans cannot achieve. However, the ultimate adjudication of truth, nuance, and context must remain human responsibility. In this era of AI deeply involved in information flow, information literacy is more important than ever. Users must learn to question AI output, verify key claims through original sources, and understand the inherent biases and limitations of systems they use. The future of information exploration will focus not on asking AI for answers, but on using AI to help us better find, evaluate, and synthesize answers ourselves.
If you finished this article, you’re absolutely among the top 0.1% most studious and smart people. And your understanding of GEO/AIO definitely surpasses 99.9%. Now go verify this with theory as your guide.
🌌 In the flood of information, understanding algorithmic biases is the first step to staying clear-headed.
