The discussion around GEO has moved past slogans. It now needs evidence.
For a while, content teams have been asking the same questions: ChatGPT, Google AI Overview / Gemini, and Perplexity are changing how information is presented. Will people still click web pages? Can content still enter the answer layer? How much of traditional SEO still works?
These are real questions. The problem is that many industry answers are still stuck at the slogan level. Some people describe GEO as a replacement for SEO. Some reduce it to a set of page-structure tricks. Others package FAQ blocks, headline formulas, Schema, and a handful of local observations into a universal playbook.
The noise is loud, but the real questions are simpler: when does AI search, which sources does it choose after searching, and how much of those sources actually remains inside the final answer?
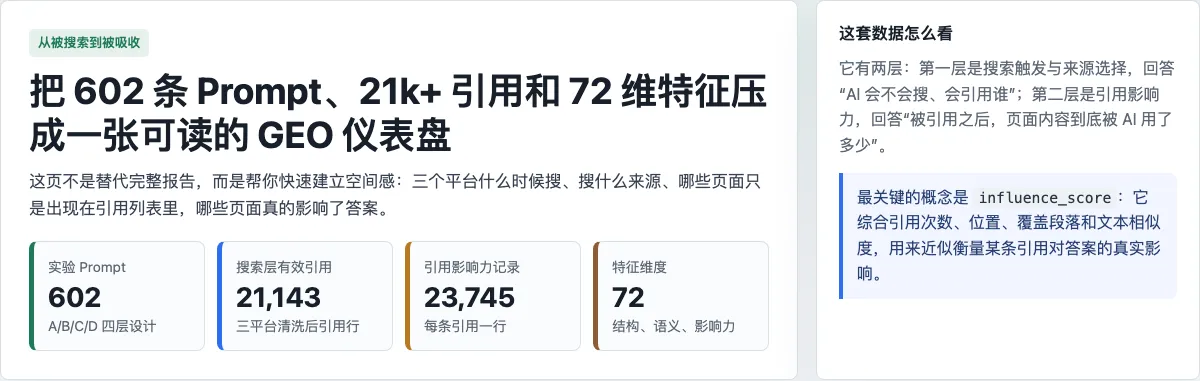
This article is based on a public research repository called geo-citation-lab. The researchers designed 602 prompts and observed search triggering, source selection, and citation usage across ChatGPT, Google AI Overview / Gemini, and Perplexity.
Its value is that it does not stop at “citation count.” The researchers crawled the cited pages, produced 23,745 citation-level records, and extracted 72 features. They tried to break down a fuzzy question: when two pages both appear in an AI source list, why does one leave only a link while another gets absorbed deeply into the answer?
In day-to-day content work, that question becomes very concrete.
An operator opens AI Overview and sees a competitor’s official site cited. There is a source link, but no click data. Another page appears several times inside a ChatGPT answer, and the facts in the answer closely resemble the original page. Both are “AI citations,” but their business value is not the same.
The first is closer to exposure.
The second is closer to evidence.
The importance of this research is that it puts that difference into data.
How the Experiment Separates AI Search Into Layers
Start with the research design. A user asks a question. The AI decides whether to search. After searching, it displays sources and then uses those sources to organize an answer. Traditional SEO mainly looks at where pages appear in search results for humans. GEO has to keep going: did the page enter the AI’s candidate source set, and once it entered, was it actually absorbed into the answer?
The 602 prompts were divided into several groups. Layer A covered industry questions across Commerce, Finance, Healthcare, Local, News, Technology, and other verticals. Layer B compared three expression styles: natural questions, source-requesting prompts, and expert-role prompts. Layer C included Chinese-English comparisons. Layer D added high-risk, ambiguous, multi-constraint, and long-decision prompts.
The search layer recorded 21,143 valid citations. Fields included search triggering, cited domain, site type, country, language, domain authority, and related source-level signals.
The citation influence layer is more granular. Each citation becomes one row. Page length, heading count, paragraph count, list density, whether the page contains numbers, definitions, comparisons, or steps, semantic similarity between page and question, and semantic similarity between page and answer all sit in the same table.
One combined metric is called influence_score. It is calculated from citation frequency, first occurrence position, answer-paragraph coverage, TF-IDF similarity, and bigram / trigram overlap.
It does not represent the model’s internal weights, and it does not prove causality. What it can do is estimate, from observable traces on the answer surface, how deeply a cited page was used.
That restraint matters. One of the easiest mistakes in GEO is turning a local observation into a supposed law of the system.
When Three Platforms Answer the Same Prompts
Start with search triggering.
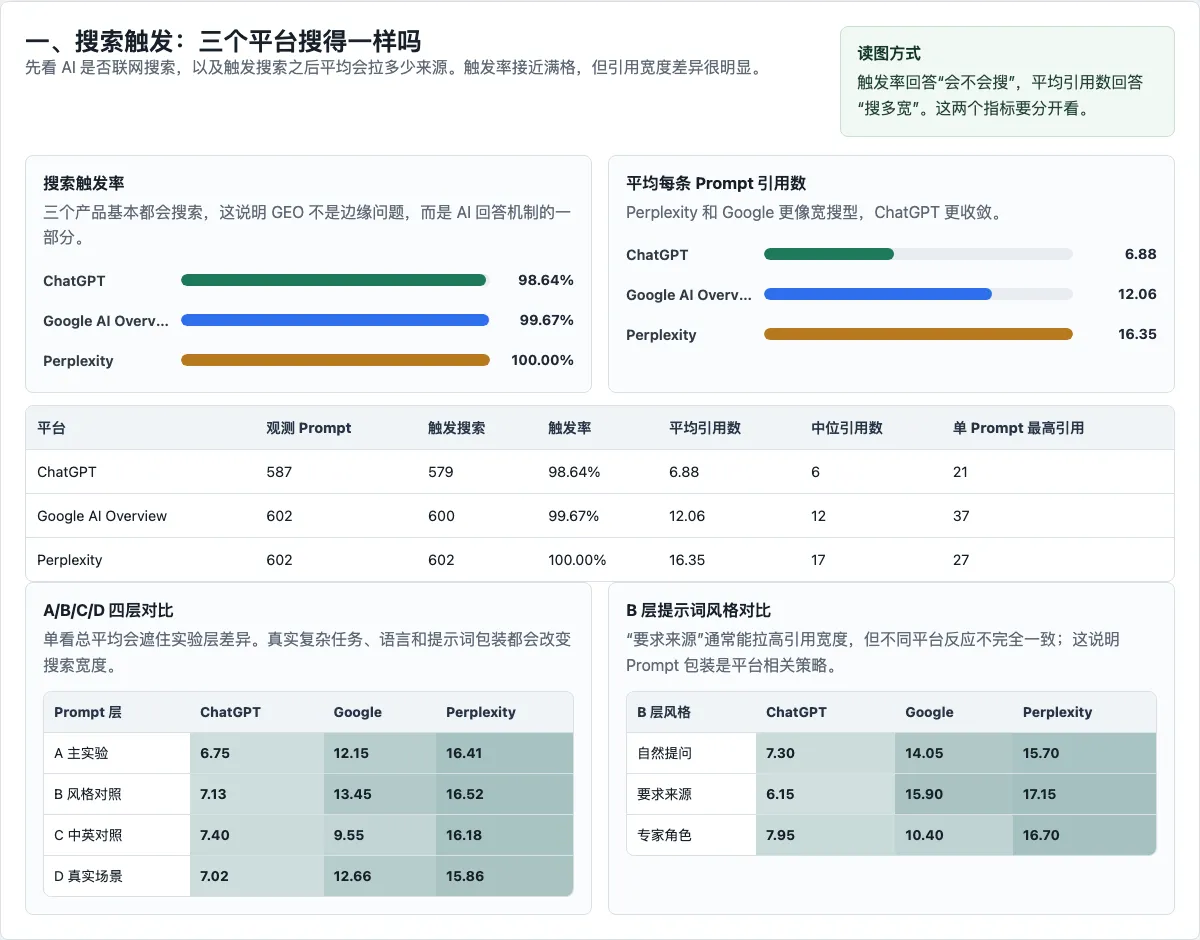
In this experiment, ChatGPT triggered search 98.64% of the time, Google AI Overview 99.67%, and Perplexity 100%. If you look only at this metric, it is easy to form a comforting illusion: if all three platforms almost always search, then once content is on the web, AI will see it.
The data quickly pushes back.
ChatGPT cited an average of 6.88 sources per prompt. Google cited 12.06. Perplexity cited 16.35. All three search, but the size of the source packet they open is different.
Imagine a very ordinary scenario.
Someone asks, “What are the most important recent advances in AI?” Perplexity may pull a long list of sources: news, blogs, official sites, and forum discussions mixed together. Google AI Overview also tends to show a broader source set, especially when the prompt requests citations. ChatGPT is more concentrated; it may use only a few sources to organize the answer.
If your job is brand exposure, wider source lists feel attractive. More sources means more chances to enter the list.
But if you care about how the answer itself is formed, another metric becomes more important.
Among successfully crawled pages, the average influence per citation was 0.2713 for ChatGPT, 0.0584 for Google, and 0.0646 for Perplexity. ChatGPT cites fewer pages, but each citation leaves a deeper trace in the answer. Google and Perplexity cite more, but the average use depth of each source is shallower.
That creates a practical fork for content teams.
Some pages are designed to win more appearances in the candidate list. They serve a distribution role. Other pages need to become stronger evidence sources: once selected by the model, they can support the substance of the answer. They serve an argument role.
In the past, we often collapsed both into one phrase: “being cited.” This dataset separates them.
Familiar Faces in the Candidate Pool
When people talk about GEO, they often imagine AI search building an entirely new information order. That idea is attractive, but the search-layer data is less romantic.
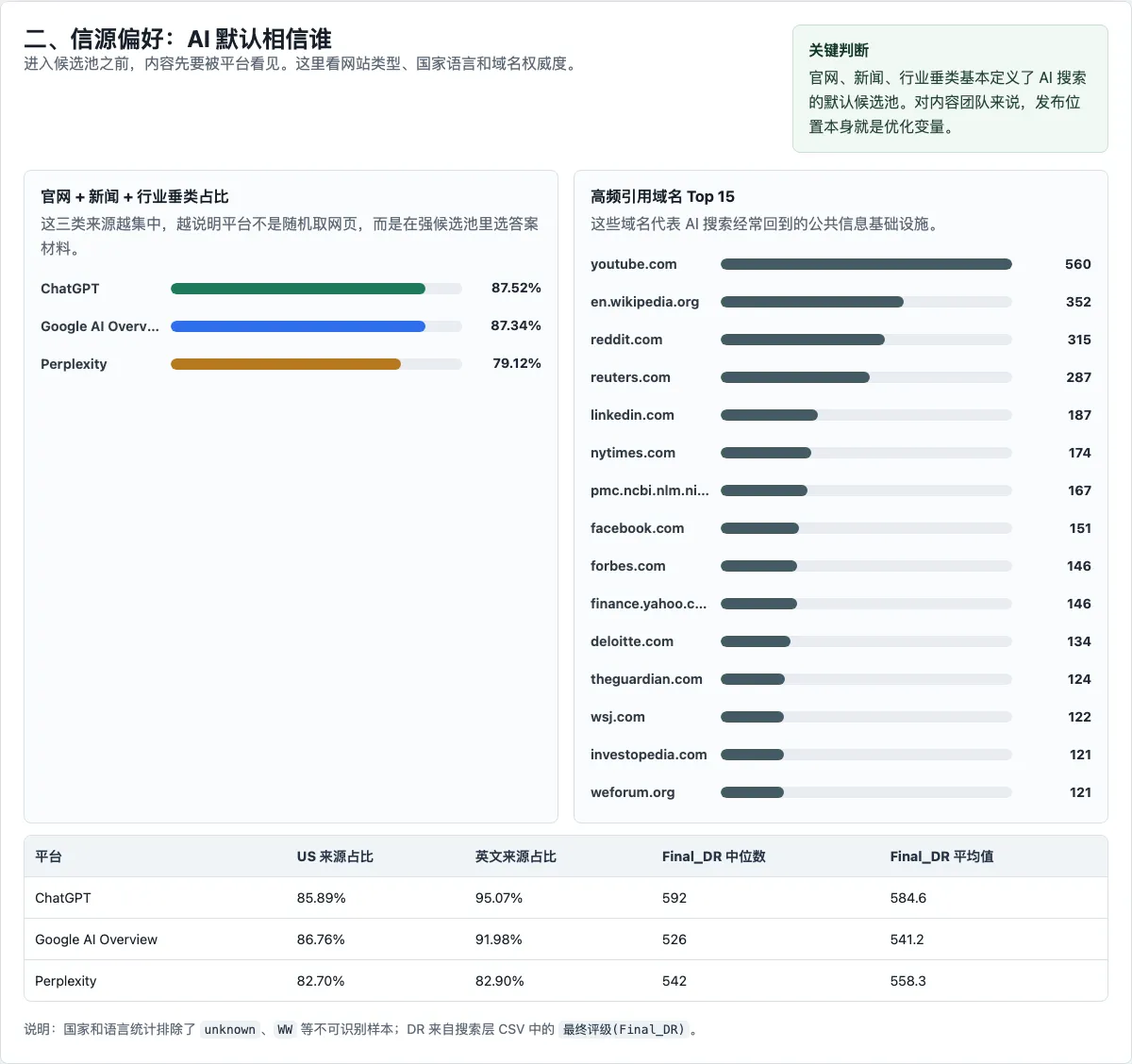
Across the three platforms, official websites, news sites, and industry vertical sites account for a large share of cited site types. In ChatGPT, these three categories make up 87.52%. In Google, 87.34%. In Perplexity, 79.12%.
Put those numbers on a real content desk and they become easier to understand.
An overseas SaaS team writes a thoughtful industry article and publishes it on its own small site. The structure is clear, and the title matches the target question. But when AI Overview answers a related query, the sources are still large media outlets, official documentation, industry associations, and leading vertical sites.
The small-site content may not be bad.
It simply has not yet entered the public information layer that models are likely to trust.
Country and language show a similar pattern. After excluding unknown and WW values, US sources account for more than 82% across all three platforms. English sources are also heavily represented: 95.07% for ChatGPT, 91.98% for Google, and 82.90% for Perplexity.
This reminds us that GEO has not escaped the old information infrastructure. AI search looks like a new entrance, but underneath it still sits web indexing, domain authority, language ecosystems, media distribution, and external links.
So page-level AI-friendly optimization is only part of the work. Clearer titles, fuller FAQs, and cleaner structure may help. But if a page lacks authority signals, external links, stable indexing, and visibility in the English-language information network, it is unlikely to become a heavily used model source overnight.
This is the part of GEO that is most often skipped.
Many teams rush to adjust pages before handling publishing position, topical authority, and external trust. The result is a page that looks more like a standard answer, while still failing to enter the candidate pool.
What Pages That Actually Feed Answers Look Like
The citation influence layer is closer to the writing desk.
The gap between the top 25% and bottom 25% pages is obvious. High-influence pages average 1,943 words, while low-influence pages average only 170. High-influence pages average 10.59 headings, while low-influence pages average 0.85. Paragraph count is 47.49 versus 8.34. List item count is 19.66 versus 0.98.

Imagine a model answering a complex question and extracting material from source pages. A page with only one short introduction can provide, at most, a background citation. Another page has definitions, data, comparisons, constraints, steps, and clear subheadings. The second page can be cut into multiple fragments and placed into different parts of the answer.
That is the distance between “being cited” and “being absorbed.”
Content format also matters. Pages containing numbers or statistics have an average influence score 61.5% higher than pages without them. Pages with definitions are 57.3% higher. Pages with comparisons are 55.3% higher. Pages with steps or guides are 41.2% higher. Pure Q&A format is 5.7% lower.
There is a useful detail here: FAQ has no automatic advantage.
In traditional SEO, FAQ is a familiar tactic. It can cover long-tail questions and make the page easier to structure. In AI search, FAQ can still be useful, but it does not automatically turn a page into good evidence. The model is looking for factual units it can reuse, not merely a sequence of questions and answers.
If a page has clear conceptual boundaries, numbers that support judgment, differences between two options, and executable steps, the model has material to draw from when composing an answer.
These elements do not have to be piled into checklists. They should be embedded naturally, so the page reads smoothly for humans and can also be extracted cleanly by models.
Good GEO content may look less like a trick page and more like an edited evidence page. It still needs human reading rhythm, but internally it has enough solid pieces that can be cited and reused.
Relevance Lives in the Title, Opening, and Sub-Questions
In this research, the independent variable most correlated with influence_score is llm_relevance_score, with a correlation coefficient of 0.432. Answer-to-page embedding similarity is 0.356. LLM content quality score is 0.292. Question-to-page embedding similarity is 0.255.
In plain content-work terms, high-influence pages usually sit close to the question.
But “close” does not simply mean keyword matching.
For example, suppose the user asks, “What kinds of content does AI search prefer to cite?” One page has a broad title like “AI Is Changing the World.” It talks about AI, and it may even be well written, but when the model looks for evidence, it is hard to place that page directly into the answer.
Another page is titled “What AI Search Prefers to Cite: A Structural Analysis Based on 23,745 Citation Records.” The opening states the research object, sample size, and core findings. The following H2 sections separately handle source type, page structure, semantic relevance, and content format.
Faced with the two pages, the model is more likely to treat the second as material that can be moved directly into an answer.
Future content work cannot stop at keyword lists. A content lead needs to break a commercial question into the sub-questions users actually ask. The title should first frame the question. The opening should state exactly what the page answers. The following paragraphs should then catch the next layer of follow-up questions. Data and examples should not sit isolated in the middle of the page; they should appear where the model is most likely to need evidence.
When those layers are disconnected, the page enters an awkward state: humans can understand the general idea, and models can identify the topic, but there are not enough clearly reusable fragments.
Bringing the Research Back to Content Production
If a content team wants to use this research, it does not need to redesign the whole site at once.
A more realistic move is to open the keyword table and conversion path, then choose a group of commercially meaningful questions. These often involve buying, selection, comparison, alternatives, risk, methods, and evaluation. General industry education can still be useful, but it may not deserve the highest priority.
Next, prepare real evidence pages for those questions.
An evidence page is not just a long article. It needs clear definitions, verifiable data, comparisons, usage boundaries, operating steps, and source notes. Page length should not be too short. In this dataset, pages between 1,000 and 3,000 words already outperform short content clearly, and pages above 3,000 words are stronger still, though they also cost more to produce.
At that stage, a content lead can focus on a dozen or so critical questions and make those pages thick enough. Volume can come later.
Then look outside the page.
Official sites, industry vertical media, authoritative directories, press releases, research reports, and public documentation can all become AI search candidate sources. For global projects, English content and visibility inside the US information network still matter.
If a small site only optimizes pages internally while having no external signals, the result is usually not encouraging. It is competing against the entire public information layer. Major media, official docs, encyclopedic pages, forum discussions, and industry reports may all stand in the same candidate pool.
That does not mean small teams have no chance.
On the contrary, small teams need to be more specific. Large sites can enter the candidate pool through authority. Smaller sites have to win through sharper topics, stronger evidence, narrower scenarios, and faster updates, leaving usable material in specific sub-questions.
There are not many shortcuts here.
But there are mistakes you can avoid.
The Boundaries of This Research
This experiment is worth reading, but it should be used with restraint.
It is closer to a static research snapshot. The repository does not include one unified collection timestamp. ChatGPT’s search layer covers 587 prompts and is still missing 15 prompt outputs. Country, language, and site-type fields include unknown, WW, and a small amount of noisy data.
influence_score is also a constructed metric. It is explanatory, but it is not the model’s real internal weight. Correlations provide observational clues; they do not reach causal proof.
Platform behavior will continue to change. ChatGPT may use sources deeply today and change its search strategy tomorrow. Google AI Overview and Perplexity will also keep adjusting interfaces, source presentation, and answer behavior. The citation shape we see now may be rewritten by the next round of product design.
So this research should not be treated as a copy-and-paste guide. It is better used as a decomposition framework.
It asks us to observe three things: whether AI searches, whom AI selects, and how much AI uses.
Together, those three questions get closer to the practical field of GEO.
A More Stable Stage Judgment
Let us pull the thread back.
GEO still stands on the foundation of SEO. Web indexing, domain authority, content structure, external citations, and language ecosystems have not disappeared. The change happens at the answer layer: content value is sometimes no longer expressed through clicks, but through citations and rewrites inside model-generated answers.
That makes content performance harder to measure.
One page may receive no click, yet still influence a user’s understanding of a problem. Another may appear in a source list while barely being used by the answer. Old metrics like click-through rate and ranking cannot fully explain those situations.
For ordinary content teams, the more stable actions are not complicated.
Build the SEO fundamentals first so pages can be reliably discovered. Then, around core commercial questions, create content that behaves more like an evidence asset. After that, keep watching how ChatGPT, Google AI Overview, and Perplexity cite your own pages and competitors’ pages.
GEO is worth preparing for, but it does not reward laziness.
It is more likely to reward accumulated trust and information structures that models can understand, split, and reuse at low cost.
AI has not invented a new trust system from nothing. It compresses, reorders, and rewrites the old information world, then presents it inside answers.
Whoever becomes stable evidence inside that reordered system will have a better chance in the next round of content competition.
As for how to turn industry keywords, competitor pages, and prompt sets into a continuous monitoring system, that is another topic.
For now, this article stops here: GEO work should not focus only on pleasing models. The steadier direction is to make content credible, relevant, citable, and absorbable as evidence.
That basic work cannot be bypassed.
