Tech Strategy Review | Vol. 2025
Google Just Flipped the RAG Table:
Gemini File Search Deep Dive and Economics Breakdown
By Mr. Guo · Reading Time: 16 Min · Last Updated: 2025-11-25
A Quick Note
Over the past two years, RAG systems’ engineering and cognitive overhead has kept climbing. Gemini File Search takes a “managed non-parametric memory” approach, pushing ETL, indexing, and retrieval logic server-side, attempting to reduce entropy and maintenance complexity in one shot.
This article covers four dimensions — architectural paradigm, technical details, cost model, and competitive benchmarking — providing an executable understanding framework and trade-off recommendations from product and engineering perspectives.
Key Highlights
- 01
Paradigm Shift: From “building-block RAG” to Managed RAG.
- 02
Technical Moats: Native multimodal ingestion with controllable chunking and source metadata.
- 03
Economics: Index charged by volume, storage and query embeddings free, Context Caching.
- 04
Competitive Benchmark: Latency models and throughput cost-efficiency, OpenAI vs. Google.
01
Preface: RAG Architecture’s Entropy Increase
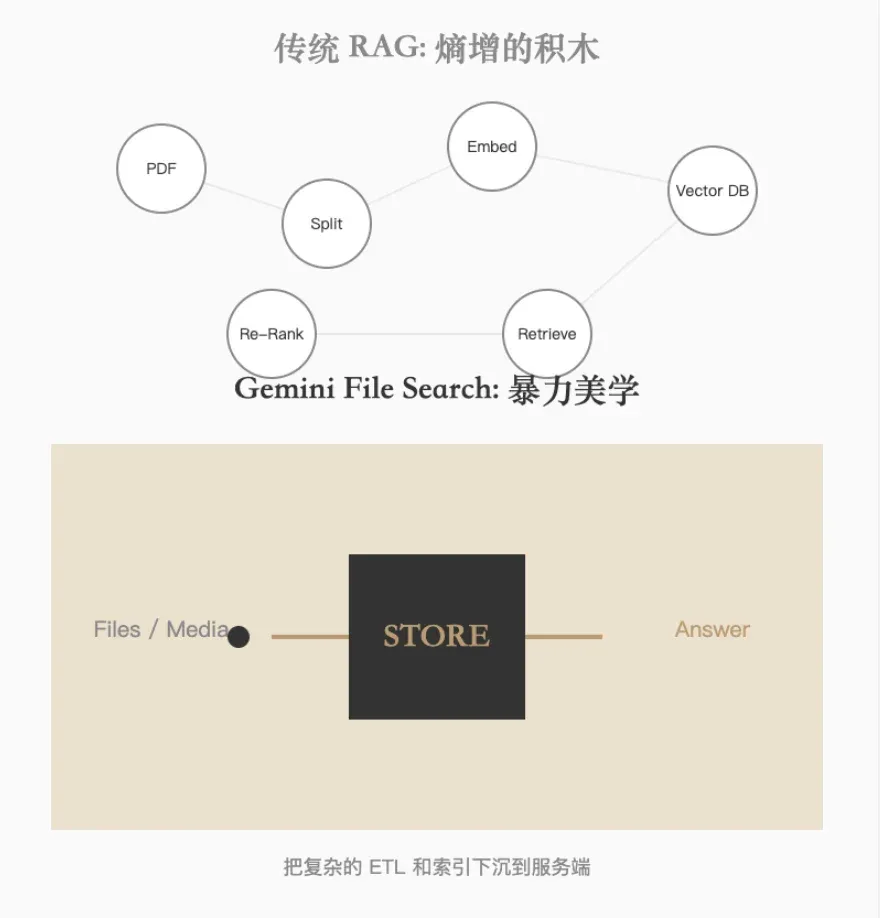
Hi, I’m Mr. Guo. We’re trapped in a Sisyphean loop: to make AI read private data, we need PDF splitting, window selection, embedding vectors, vector database maintenance, and similarity retrieval, finally stuffing results back into prompts. This isn’t just engineering overhead — it’s cognitive entropy increase. Gemini File Search tries to flip this table with “brute force elegance.”
As I wrote before: Is RAG Dead? Claude Core Developer Proposes Agentic Retrieval — personally, I really don’t like using RAG in practice, including various popular “local knowledge bases.”
This isn’t just extra engineering overhead — it’s cognitive entropy increase. The whole “mess around endlessly adjusting chunking logic” thing is not elegant or simple at all.
Now Gemini File Search tries to flip this table with “brute force elegance.”
02
Paradigm Shift: Google’s “Nuclear Option”
Traditional RAG development is building blocks, while Gemini File Search is more like a black box: throw files in, get answers out. This marks the leap from pure parametric memory to Managed Non-Parametric Memory (Managed RAG).
Google defined a new entity object — File Search Store — a persistent, compute-enabled knowledge container. It pushes vector indexing and retrieval logic down as model Tools, simplifying state management and improving query adaptability.
-
Simplified State Management: Store becomes single source of truth, avoiding local index desync.
-
Retrieval Pushdown: Model decides when to retrieve and rewrite queries, reducing client complexity.
03
Pipeline Deep Dive: Native Multimodal Technical Moats
Gemini File Search’s moat lies in native multimodal ingestion and geek-level chunking control. It supports direct video and audio indexing, retrieving in multimodal vector space, no longer dependent on text-only pipelines.
-
Native Video/Audio Indexing: Multimodal space retrieval, supports questions about non-text features like expressions and tone.
-
Chunking Control:
chunking_configsupportsmax_tokens_per_chunkandmax_overlap_tokensfor fine-grained settings. -
Source Metadata: Response includes
grounding_metadata, precisely annotating source pages and paragraphs — compliance audit-ready.
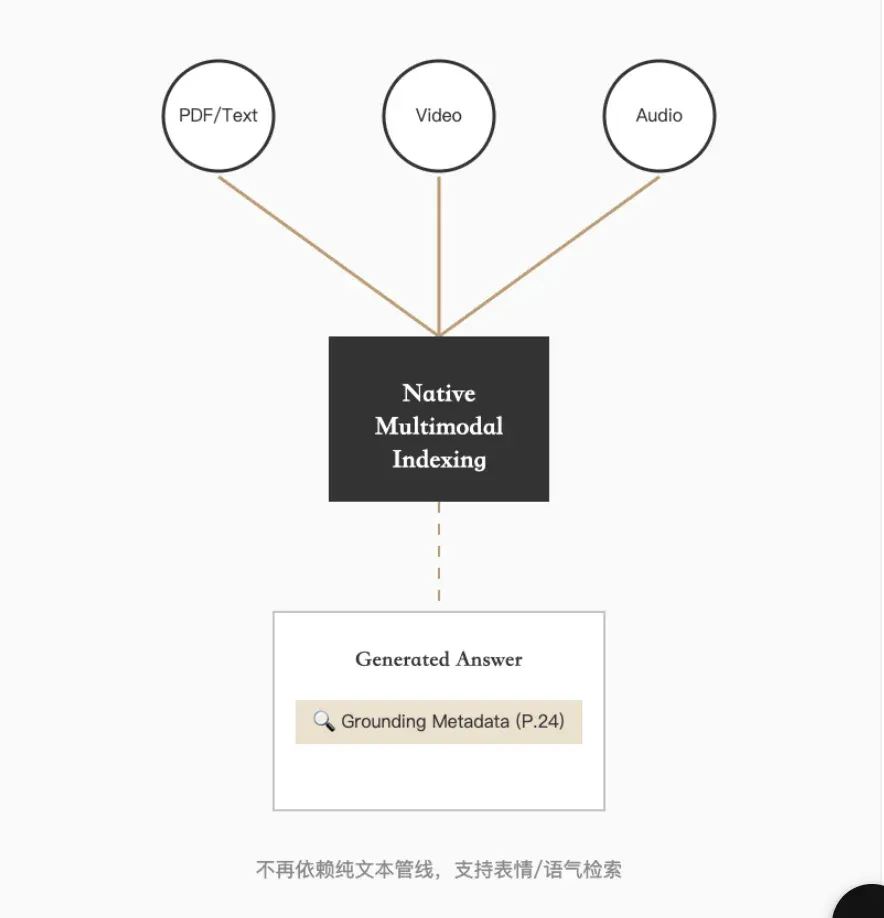
“This is what enterprise applications care about most: without sourcing, RAG is a toy.”
04
Economics Deep Dive: The Strategy Behind Free Storage
Cost Comparison
Traditional RAG costs include embeddings, vector storage, and inference input; Gemini zeros out storage and query-time embedding costs, charging only for indexing and inference input.
Traditional RAG
Embedding API charged per token; Vector database storage fees (monthly/pod) expensive; Query inference input fees.
Gemini File Search
Index Fee: $0.15 / 1M Tokens (one-time); Storage free; Query embeddings free; Only inference input fees.
Context Caching
High-frequency scenarios can pay for long-context caching, subsequent input costs drop significantly (up to ~90% reduction) — ideal for customer service bots and Agent scenarios.

05
Competitive Benchmark: Gemini vs. OpenAI
-
Latency & Interaction: OpenAI Assistants use async polling; Gemini generates synchronously, combined with Flash model for better first-token latency.
-
File Handling: OpenAI single file limit ~512MB; Gemini Files API single file up to 5GB — suitable for video and large datasets.
-
Reasoning & Throughput: Complex reasoning slightly favors OpenAI; big data throughput and cost-efficiency favor Google for enterprise needs.

Conclusion: The Commoditization of the Vector Layer
Gemini File Search’s arrival announces the commoditization of the “vector layer.” Low-level indexing details are progressively encapsulated into infrastructure, and application development barriers return to data quality and scenario understanding. When memory is extremely cheap and readily available, Reasoning’s value truly emerges.
Found this valuable? Drop a 👍 and share it with CTO friends pulling their hair out over RAG architecture.
