Emergency Tech Review | Vol. 2025
GPT-5.2 Pro Quick Test:
Is 30-Minute Reasoning Worth the $100+ Price Tag?
By Mr. Guo · Reading Time: 6 Min
A Quick Note
Last night was probably the most sleepless night for the global AI community. To counter Google Gemini 3’s strong emergence, OpenAI didn’t even warm up — they just dropped a “Code Red” level update: GPT-5.2.
Facing new model launches, I generally don’t look at benchmark scores. How strong a model really is depends on whether it actually helps your specific work. So I decided to run a quick test.
01: Frontend Devs’ “Darkest Hour”
Just days ago I was marveling at Gemini 3 Pro’s first-class frontend and aesthetic capabilities. Now, days later, GPT is shocking me again.
I just tested a UI design with complex graphic layers. GPT-5.2 not only reproduced the layout but accurately identified the design intent’s “Visual Hierarchy.”
GPT-5.2 Real-World Comparison
Testing method wasn’t complex. I first used Nanobanana Pro to generate a random dashboard image like below — Nanobanana’s UI image capability is old news by now.
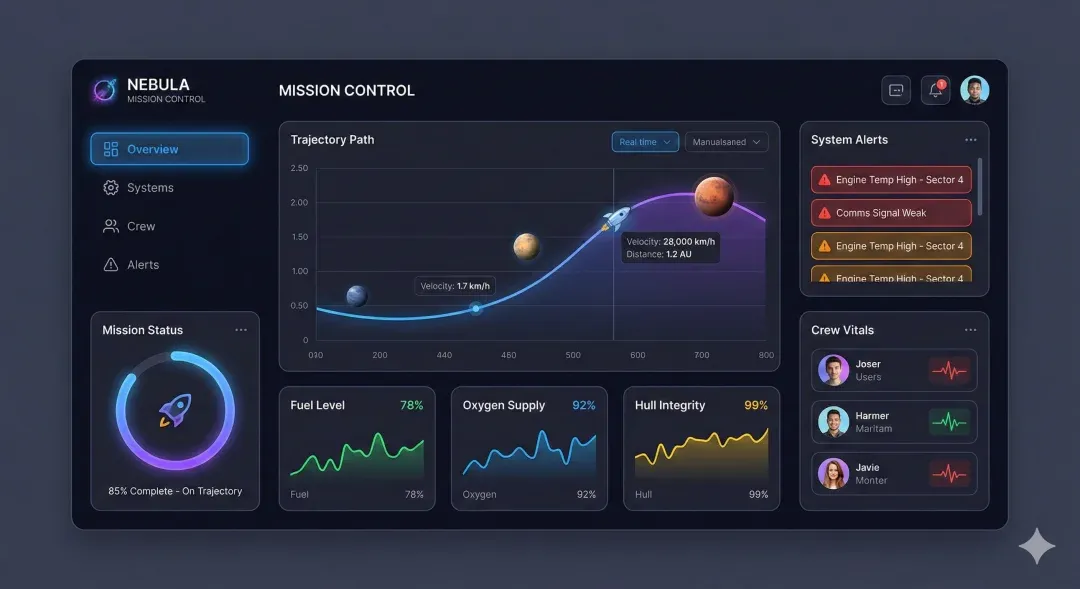
The key is what came next. The code GPT5 Pro generated for reproduction genuinely shocked me:
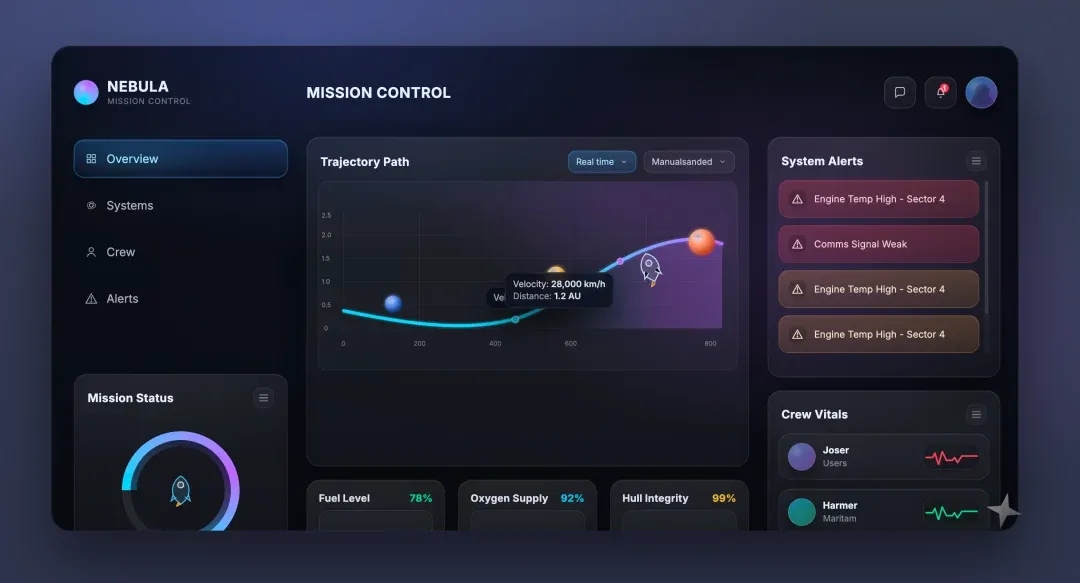
Interestingly, it even included the Gemini watermark that was on the Nanobanana image. Truly outrageous!
Of course, achieving this pixel-perfect reproduction comes at a cost.
I used the GPT5.2 Pro model exclusive to the $200/month GPT Pro plan. This model’s reasoning time is truly staggering:
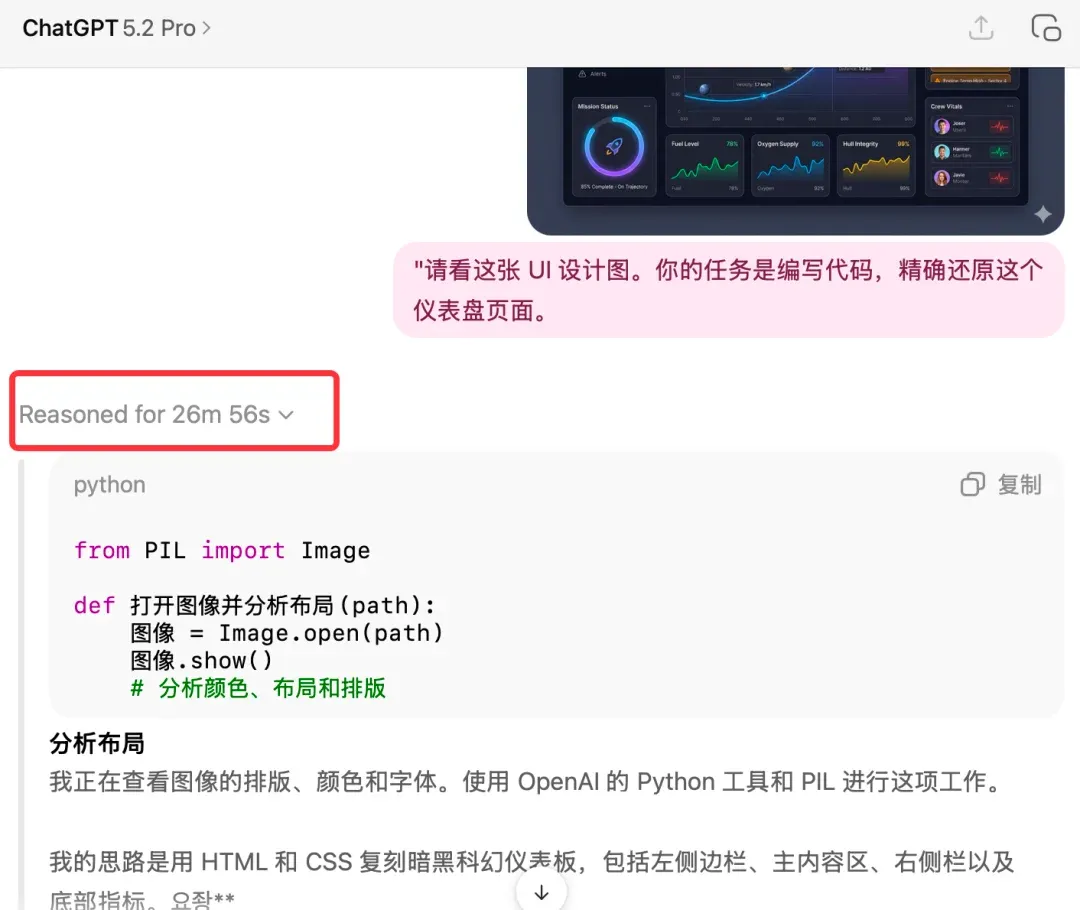
It took nearly 30 minutes to complete this task’s reasoning!
For comparison, I chose the equally strong Gemini 3.0 Pro — same prompt, same reference image, output as pure HTML without external libraries:
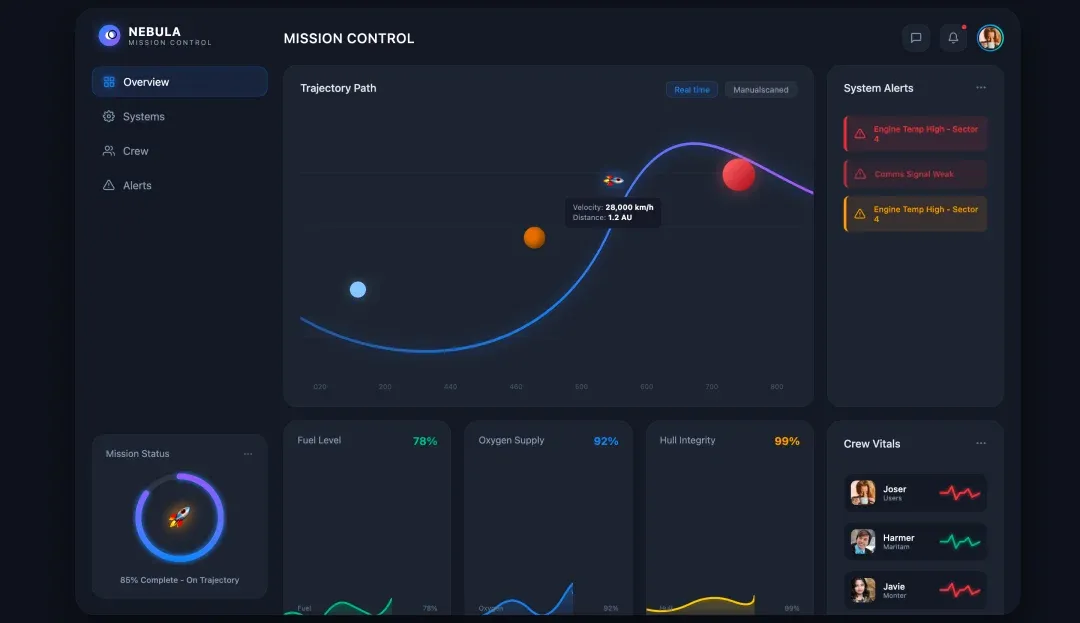
Relatively speaking, also very strong. But this time I must admit — GPT5.2 Pro slightly edges out on aesthetics!
02: It’s Not Cheap, But It’s Worth It
OpenAI may have been pressured by Google Gemini 3, but their pricing confidence is almost arrogant. GPT-5.2’s output price shot up to $14 / 1M tokens. What does this mean? Not to mention the even more outrageous GPT5.2 Pro at $168 / 1M tokens!
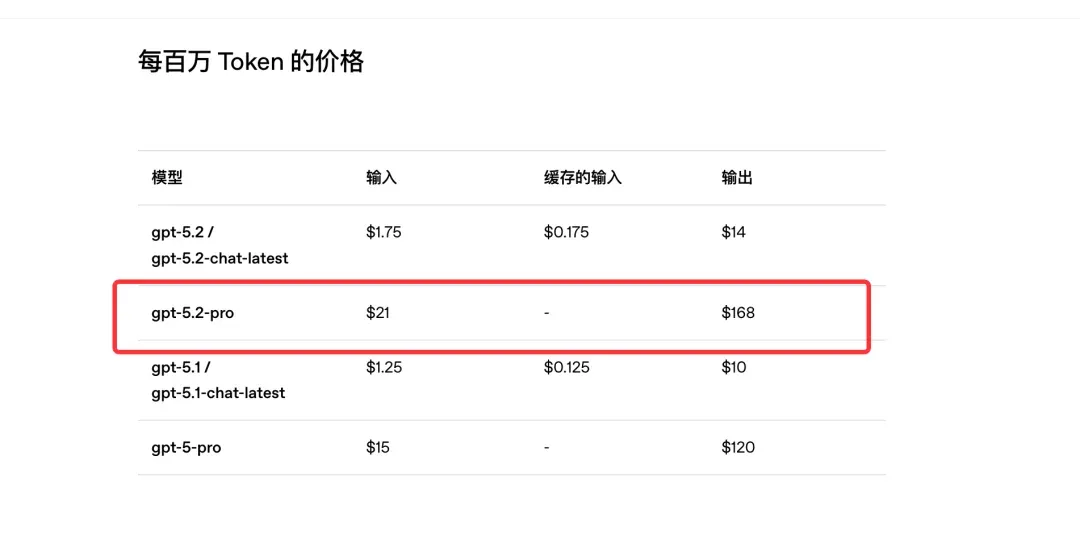
But! Its efficiency is genuinely, extremely low! I’m also a Codex user — its slowness is truly unbearable. Feels at least 3x slower than Claude Opus 4.5.
Though code quality is genuinely good, efficiency is genuinely low. Sometimes for small tweaks, you just can’t use it.
03: Don’t Blindly Trust “The Strongest Model” — Choose What Fits You Best
Overall, GPT5.2’s strength this time is unquestionable. But GPT’s speed is currently really hard to accept. Though coding capability-wise, GPT 5.2’s Codex version surely won’t be weaker than Opus 4.5 — but Claude Opus 4.5 currently offers the best comprehensive coding experience because you can’t ignore factors like speed. For writing, Gemini 3 remains king. GPT5.2 for me feels like: I know it’s strong, but I don’t know where to best use it. Not cost-effective, not efficient, high quality — but then what?
Mr. Guo
Tech / Strategy / Future
“Don’t try to compete with AI on speed — compete with it on the ability to define problems.”
If you were also a “night watch” tonight, welcome to share your test results in the comments.
