Word count: ~2100 words
Estimated reading time: ~15 minutes
Last updated: August 18, 2025
Key Takeaways
✅ Deep analysis of NVIDIA’s latest paper challenging the “bigger is better” industry assumption.
✅ Why Small Language Models (SLMs) are better suited for AI Agents in cost, efficiency, and architecture.
✅ Exploring the “heterogeneous hybrid” paradigm: LLM (CEO) + SLM (Specialists).
✅ A directly applicable “LLM-to-SLM” Agent transformation roadmap.
1. Preface: A “Copernican Revolution” in AI
Hey, I’m Mr. Guo. In the Agentic AI field, an “arms race” around model scale is in full swing. Industry giants seem to have accepted a creed: bigger models mean stronger capabilities, and smarter Agents. Yet amid this, NVIDIA published a highly disruptive position paper with a straightforward title — “Small Language Models are the Future of Agentic AI.”
This paper is like someone calmly pointing out heliocentrism in an era dominated by geocentrism. It forces us to reconsider a fundamental question: To complete highly specialized, repetitive Agent tasks, do we really need to deploy an all-knowing “generalist” model capable of writing poetry and discussing philosophy? Isn’t this a massive resource mismatch? Today, I’ll take you through this manifesto and explain why the future of Agents belongs to small, elegant SLMs.
Original paper link:
2. Core Arguments: Why SLMs Are “The Chosen Ones” for Agents
NVIDIA’s argument isn’t empty talk — it’s built on three solid pillars, progressively compelling.
Argument 1 (V1): Capabilities Have Arrived — SLMs Are No Longer Underdogs
Past thinking held that SLMs were limited in capability, but the paper cites numerous cases (Microsoft Phi-3, NVIDIA Nemotron-H, etc.) proving that well-designed modern SLMs can match or even surpass LLMs many times their size in core Agent capabilities like commonsense reasoning, tool calling, and code generation. In short, SLM capabilities have crossed from “usable” to “excellent.”
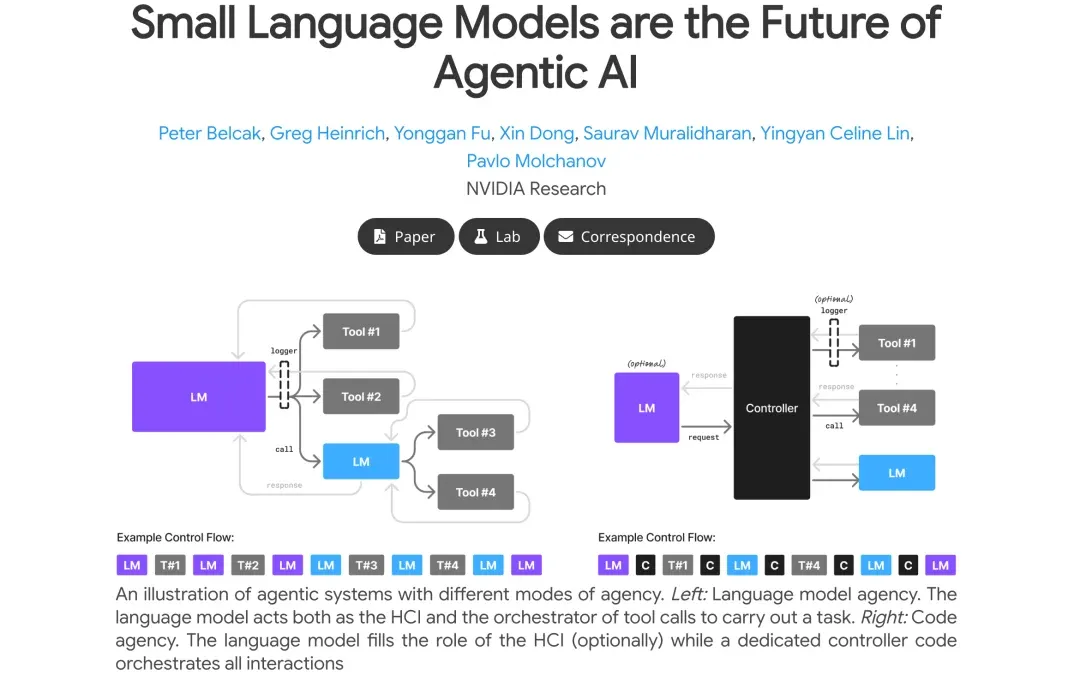
Argument 2 (V2): Natural Architectural Fit
The essence of an AI Agent is completing specific tasks through a series of tool calls and logical orchestration. This means most of its work is highly structured with strict format requirements. In such scenarios, an SLM that’s been specifically fine-tuned with highly predictable behavior is far more reliable and integrable than an LLM with broad behavioral patterns that occasionally “freestyles.” This perfectly validates the point from our earlier “Micro Agent” article: “demoting” AI to reliable, task-specific “intelligent nodes” is the path to production-grade applications.
Argument 3 (V3): Cost and Efficiency “Dimension Reduction Attack”
This is SLM’s most lethal advantage. The paper elaborates from multiple dimensions:
-
Inference Efficiency: Serving a 7B SLM costs 10-30x less in latency, energy, and compute than serving a 70B+ LLM. This means faster response times and lower operational costs.
-
Fine-tuning Agility: Adding new skills or fixing bugs in an SLM might only take a few GPU hours — iteration “overnight” is possible — while LLMs require weeks.
-
Edge Deployment: SLMs can easily deploy on consumer GPUs or even phones for offline inference, opening possibilities for data privacy and low-latency scenarios.
3. Future Vision: Building LLM (CEO) + SLM (Specialist) “Heterogeneous Hybrid Teams”
NVIDIA’s position isn’t to completely reject LLMs but to advocate a smarter, more efficient architecture — Heterogeneous Agentic Systems.
Think of this system as an efficient company:
-
LLM as CEO: Responsible for top-level strategic planning, understanding complex ambiguous user intent, conducting open-domain dialogue and decision-making. Only invoke this “expensive consultant” when tasks require powerful general reasoning.
-
SLMs as Specialist Employees: Each SLM is fine-tuned as a domain expert — “code generation specialist,” “API calling specialist,” “document summarization specialist,” etc. They efficiently handle 80% of routine, repetitive work at low cost.
This “Lego-style” composition — “scaling out” with multiple small, specialized SLMs rather than “scaling up” with one massive LLM — builds Agent systems that are both cost-effective and powerful.
4. Action Guide: How to Achieve “Cost Reduction and Efficiency Gains” for Your Agent
Most valuably, the paper doesn’t stop at theory — it provides a clear “LLM-to-SLM” conversion algorithm. Here’s my distillation into an actionable roadmap:
-
Data Collection and Instrumentation (Secure usage data collection): First, instrument your Agent’s LLM call interfaces (internal calls, not direct user interactions) to securely log input prompts, output results, and tool call content.
-
Data Cleaning and Anonymization (Data curation and filtering): Clean the collected data, removing all sensitive information (PII, PHI) to ensure data security.
-
Task Clustering and Identification (Task clustering): Use unsupervised clustering techniques to analyze collected call data and identify high-frequency, repetitive task patterns. For example: “generate SQL query,” “extract JSON from text,” “call weather API,” etc.
-
Select Appropriate SLM (SLM selection): For each identified task, select a suitable SLM candidate model. Consider its base capabilities, performance, license, and deployment requirements.
-
Fine-tune Specialist SLMs (Specialized SLM fine-tuning): Using corresponding task data, fine-tune the selected SLM (via LoRA or QLoRA) to make it an “expert” for that task.
-
Iteration and Optimization (Iteration and refinement): Replace original LLM call interfaces with fine-tuned specialist SLMs. Continuously collect new data, periodically re-fine-tune, forming a continuous improvement loop.
5. Conclusion: Return to Engineering Rationality in AI Philosophy
NVIDIA’s paper is essentially calling for a “return to engineering rationality” in the AI field. It reminds us that while chasing the stars (AGI), we must also stay grounded, seeking the optimal cost-benefit solutions for specific problems.
This article’s philosophy aligns perfectly with my earlier piece “Is the AI Agent Dead? Long Live the ‘Micro Agent’!” — making me more certain that in the near-term future, hybrid LLM + SLM “Micro Agents” will be the best solution for market application scenarios.
Shifting from LLM-centric to SLM-first isn’t technological regression but evolution. It means we’re moving from the “use what we have” extensive phase to the “match the right tool to each task” refined operations phase. This isn’t just about cost — it’s about efficiency, sustainability, and democratizing AI technology.
Found Mr. Guo’s analysis insightful? Drop a 👍 and share with more friends who need it!
Follow my channel to explore AI, going global, and digital marketing’s infinite possibilities together.
🌌 The optimal solution is often not the strongest, but the most suitable.
