Digital Strategy Review | 2026
OpenAI Releases GPT-5.4 mini and nano: The Price War Begins to Rewrite the AI API Market | Uncle Fruit AI Daily
By Uncle Fruit · Reading Time / 8 Min
Editor’s Note
If you are still trying to understand model competition using the old playbook, you are likely falling behind.
In the past, we measured competition in the large model market by three things: who is the most powerful, who is best at making demos, and who integrates new capabilities into products first. By March 19, 2026, the focus of the discussion has clearly shifted: whoever can provide “sufficient power” at a low enough price is more likely to truly capture developer workflows.
This is why I am giving the front page to GPT-5.4 mini and nano today. When OpenAI officially released these two new models on March 17, 2026, the information provided wasn’t just “smaller and faster,” but a more comprehensive set of signals: mini approaches large models in various coding and tool-use benchmarks while running faster; nano pushes the price down to $0.20 per million input tokens; and more importantly, OpenAI has directly integrated mini into the actual workflows of Codex and ChatGPT.
In other words, the key to this news isn’t “OpenAI released new models again,” but rather: small models are transitioning from “cheap backups” to genuine, first-line production models, and they are now being defined as the default execution layer in AI workflows.

01
Today’s Top Headlines
Quick Summary
01 OpenAI released GPT-5.4 mini and nano on March 17, 2026. The company defines them as the “most powerful small models to date,” emphasizing coding, tool use, multimodal understanding, and high-throughput scenarios.
02 The positioning of mini is very clear: it is not just a low-spec version, but a workflow model approaching GPT-5.4. OpenAI’s official post states that mini nears GPT-5.4 in multiple coding and tool benchmarks, with speeds more than twice that of the previous mini.
03 The pricing for nano is even more aggressive: $0.20 per million input tokens and $1.25 for output. This price point is approaching a level where you can start feeding tasks into the model that you previously thought weren’t “worthy” of a large model.
04 Changes at the workflow level are more important than the models themselves: OpenAI didn’t just list mini/nano on the API price sheet; they integrated them into Codex’s subagent scenarios. This effectively tells developers: in the future, large models handle planning, while simple and parallel subtasks are handled by cheaper small models.
The Facts: What We Can Confirm Today
According to OpenAI’s official release page, both GPT-5.4 mini and nano went live on March 17, 2026. OpenAI describes them as “fast and efficient models optimized for coding and subagents.” mini is available via API, Codex, and ChatGPT; nano is currently available only via API.
Official pricing:
• GPT-5.4 mini: $0.75 per million input tokens, $4.50 per million output tokens
• GPT-5.4 nano: $0.20 per million input tokens, $1.25 per million output tokens
The company also provided several key benchmarks. At high reasoning effort, mini reached 54.4% on SWE-Bench Pro, while nano reached 52.4% (compared to 45.7% for the previous GPT-5 mini). On Toolathlon, mini scored 42.9% and nano 35.5%, compared to 26.9% for the old mini. These numbers mean one thing: they aren’t “cheap but significantly weaker” models; they are strong enough to be taken seriously as primary models in many real-world development workflows.
Simon Willison’s analysis adds another dimension: the visceral impact of the price shift. He compared the new price sheet with Claude and Gemini, noting that gpt-5.4-nano’s input price is even lower than Gemini 3.1 Flash-Lite. In his own image description test, describing 76,000 photos at this cost would total approximately $52.44.
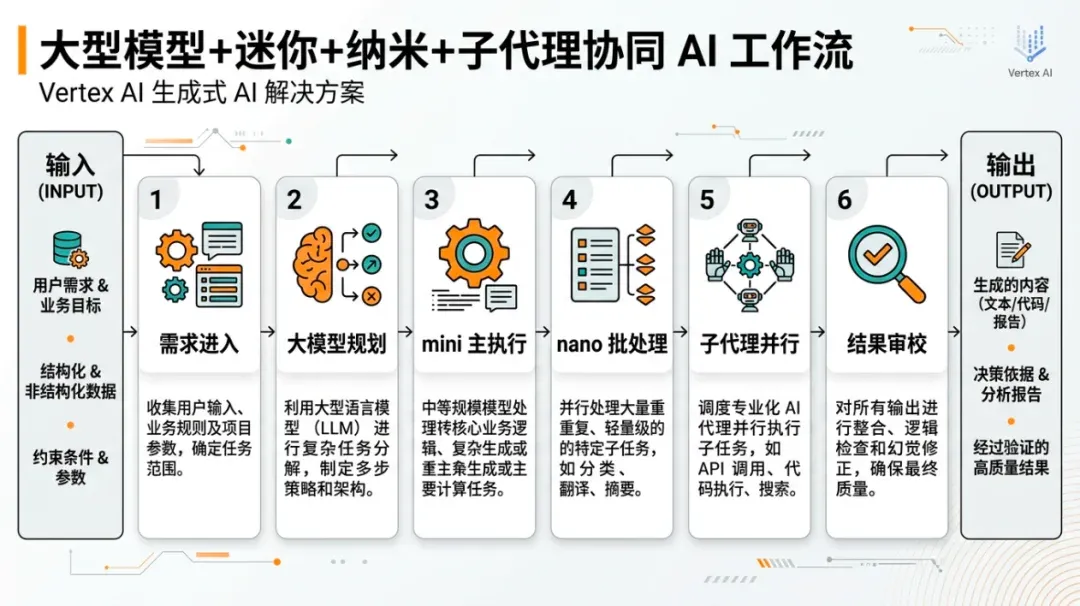
Another important but often overlooked point is that OpenAI has explicitly bound mini to the Codex subagent scenario: large models handle planning, coordination, and final judgment, while mini subagents handle searching codebases, reading large files, and processing supporting materials. This means the value of mini isn’t just that it’s “cheap”—it has been designed as the default large-scale execution layer in the entire agent workflow.
Source (OpenAI Official): https://openai.com/index/introducing-gpt-5-4-mini-and-nano/
Supplementary Source (Simon Willison): https://simonwillison.net/2026/Mar/17/mini-and-nano/
Supplementary Source (OpenAI Codex Documentation): https://developers.openai.com/codex/subagents
Why It Deserves the Front Page
Because this news doesn’t just rewrite “model leaderboards”—it rewrites the default way developers buy, select, and allocate models.
In the past, many teams asked: “Do I want the strongest model or the cheaper one?” The more common question will now be: “In my workflow, which steps require the strongest model, which should be defaulted to mini, and which extremely low-complexity tasks can be batched to nano?”
Once the decision-making logic shifts this way, the market structure will follow: mid-range models will come under pressure, old workflows will become obsolete, and teams that master “mixed model orchestration” will gain a significant advantage.
02
Deep Dive: Why This Matters More
1) The Price War Has Upgraded from “Discounts” to “System Architecture Rewrites”
Many people’s first reaction to this news is “OpenAI lowered prices again.” But I believe viewing it solely as a price war underestimates its disruptive power.
The change today isn’t just about a single price figure; it’s the convergence of three things: 01 Significant performance gains in small models. 02 Continued downward pressure on small model pricing. 03 Small models being explicitly written into product-grade agent workflows.
The result of these three factors is that teams will lean toward “layered scheduling” at the system architecture level.
Previously, people often used a “one-size-fits-all” approach: one strong model from start to finish—costly but simple. More reasonable systems will increasingly look like this:
• Large models handle planning, ambiguity, and final review.
• mini handles the majority of execution tasks.
• nano handles classification, extraction, batch processing, and supporting subtasks.
This means model price sheets are no longer just procurement info; they are part of architectural decision-making.
2) mini Truly Threatens the Relevance of “Mid-Range Models”
If a model is much cheaper but significantly worse in performance, it’s just a filler. If a model is much cheaper but its performance approaches that of large models in common tasks, it begins to squeeze not the high-end, but the mid-range.
This is exactly where GPT-5.4 mini is most dangerous.
OpenAI’s positioning is clever: they don’t claim it’s fully equivalent to GPT-5.4, but emphasize that in high-frequency workflows like coding, tool use, and multimodal understanding, it is strong enough and faster. For many teams, that is enough. In real production, the most common problem is never “can it solve the hardest problem,” but “can it finish 80% of tasks cheaply, stably, and quickly.”
Once mini establishes itself in this range, mid-range models will struggle. If they aren’t cheap enough, they’ll be eaten by mini; if their capabilities aren’t outstanding, they can’t compete with large models. My assessment: the hardest hit in 2026 won’t be the most expensive or cheapest models, but the “middle-tier” that is neither strong enough nor cheap enough.
3) nano Makes “Tasks We Previously Couldn’t Be Bothered to Automate” Worth Doing
Many workflows didn’t use models in the past not because of technical limitations, but because it wasn’t economically viable.
For example: • Large-scale text classification. • Log cleaning and structured extraction. • Document metadata completion. • Image description and screenshot understanding. • Pre-filtering tasks in toolchains. • Supporting subtasks in agent workflows.
The problem with these tasks is usually not difficulty, but volume. If you use a large model, the bill will scare you; if you use a weak model, errors will drag down the entire chain. The significance of nano is that it brings tasks that are “high volume, not extremely demanding, but requiring model intelligence” into a cost bracket where you can safely integrate them into your system.
Simon Willison’s example of “describing 76,000 photos for about $52” is telling: this isn’t a joke demo, but a shift in psychological pricing thresholds. Developers will start to ask: “Since it’s already this cheap, why not just let the model do this step?“
4) OpenAI is Using mini/nano to Strengthen Its Tool Ecosystem
If you only look at the models, you might think this is just a minor capacity expansion. If you look at the release page alongside the Codex documentation, you’ll see OpenAI is doing something else: using cheaper small models to strengthen the internal loop of its developer ecosystem.
The official copy is clear: in Codex, large models handle the global view, while a large number of simple subtasks can be delegated to mini subagents. This design effectively productizes “using cheap models for detailed work.”
Why does this matter? Because once developers naturally accept this layered model-calling approach in Codex, API, and ChatGPT, OpenAI’s advantage becomes: 01 You are accustomed to its workflow. 02 You have accepted its scheduling logic. 03 You have built your product’s cost structure around its price bands.
This significantly increases ecosystem stickiness.
5) For Entrepreneurs, the Opportunity Isn’t “Using Cheaper Models,” but “Recalculating Product Boundaries”
I think the most important takeaway for entrepreneurs isn’t just saving money, but that product boundaries will be redrawn.
Previously, if a feature was too expensive to call a model, teams would choose not to build it or would build it in a limited way. Now that mini/nano have lowered those costs, you can rethink:
• Are there AI-assisted features you didn’t build because of cost?
• Are there modules that can be upgraded from single-step answers to multi-step agents?
• Are there processes that previously required human oversight that can now be pre-screened by a model?
• Are there capabilities previously reserved for high-paying users that can now be opened to a larger audience?
This isn’t about “cutting costs,” but “redefining what is worth doing.”
Flowchart illustrating the methodology execution path.
03
Uncle Fruit’s Perspective
My core assessment of this news: OpenAI didn’t just release two small models; they released a new default working methodology.
In the near future, the teams with the real advantage won’t be the ones who “used GPT-5.4 mini first,” but the ones who learned to use models in layers and restructured their product costs accordingly.
1) Stop Designing AI Products with “Single-Model Thinking”
Increasingly, mature systems will be multi-layered model structures:
• A large model for directional judgment.
• A mini model for primary execution.
• A nano model for high-volume support tasks.
If you are still designing products based on “one request, one model,” you will soon lose out on cost, response speed, and scalability.
2) Identify the 20% Most Expensive Calls First
For most teams that have already launched AI capabilities, my advice is not to chase the new, but to go back and look at the bills.
Identify: • The steps with the highest call volume but low actual complexity. • The steps frequently handled by large models that don’t actually require top-tier reasoning. • Processes that can be broken into “main tasks + subtasks.”
These three areas are the best candidates for prioritizing mini/nano. Many teams don’t need to solve AI costs by “reducing call frequency”; they can achieve significant savings just by “matching the right task to the right model.”
3) This Wave Will Continue to Benefit Agents, Coding, and Automation
The three scenarios that benefit most directly from mini/nano are:
• Coding agents.
• Automation workflows.
• Multimodal batch pipelines.
These scenarios share a common trait: high task volume, granular steps, many parallel subtasks, and sensitivity to unit call costs. In other words, the more an AI system resembles an “industrial process,” the more it will reap the benefits of this price and performance reshuffle.
04
Other Key News
1) Google DeepMind Releases AGI Cognitive Measurement Framework and Launches Kaggle Hackathon
On March 17, 2026, Google DeepMind proposed a cognitive framework for measuring AGI progress and launched a Kaggle hackathon, inviting the research community to build evaluation methods around 10 key cognitive abilities. They also provided a three-stage evaluation protocol and a $200,000 prize pool. Significance: The AI industry is starting to compete more seriously over “how to measure AGI” rather than just “who claims to be closer to AGI.”
2) Google Expands Personal Intelligence to Free Users in AI Mode, Gemini, and Chrome
On March 17, 2026, Google announced that Personal Intelligence is expanding to AI Mode in Search, the Gemini app, and Gemini in Chrome, rolling out to free-tier users. It allows the system to provide more customized answers by combining personal context from Gmail, Google Photos, etc. Significance: Google is pushing “understanding you better” from experimental features to a wider user base. AI assistant competition is increasingly becoming about “who uses your personal context better.”
3) Mistral Small 4 Attempts to Combine Reasoning, Multimodality, and Agentic Coding
Mistral launched Mistral Small 4 on March 16, 2026. According to official sources, it integrates Magistral’s reasoning, Pixtral’s multimodality, and Devstral’s agentic coding into a single model. Simon Willison notes it is a 119B parameter, Apache 2 licensed model. Significance: This represents a different path than OpenAI: instead of slicing finer price bands, it attempts to unify multiple capabilities into a single open-weight model.
4) Python 3.15 JIT Achieves ~11%-12% Performance Boost on macOS AArch64
Ken Jin’s update on Python 3.15 JIT shows an 11%-12% performance improvement on macOS AArch64 and 5%-6% on x86_64 Linux. Significance: The value for AI developers isn’t just “Python is faster,” but that continuous improvements in the underlying runtime will gradually improve the efficiency of inference toolchains, data pipelines, and agent execution layers.
5) Django Community Discusses Ethical Boundaries of LLM-Generated Contributions
Referencing Tim Schilling’s article, Simon Willison excerpted a representative view: if contributors don’t understand the ticket, solution, or PR feedback themselves, LLM usage is harming the Django community. Significance: This isn’t “open source vs. AI,” but a growing discussion on: AI assistance is acceptable, but you cannot outsource the “human understanding of the problem.”
6) Subagent Patterns Gain Momentum as Default Architecture for Coding Agents
Simon Willison’s subagent guide explains the pattern clearly: the main agent dispatches subagents with fresh context windows to perform code exploration, parallel tasks, and specialized checks, then aggregates the results. OpenAI’s Codex documentation has also formalized subagents as a standard workflow capability. Significance: 2026 agent competition is no longer just about “how smart a single model is,” but who can decompose, parallelize, and converge complex tasks more efficiently.
05
Trends and Opportunities
1) The Most Valuable Skill of the Future is “Model Orchestration,” Not “Single-Model Worship”
Models are increasingly like computing resources of different specifications. Whoever can decompose, assign, and orchestrate tasks correctly will find better solutions regarding cost, latency, and results.
2) Small Models Will Continue to Eat Work Previously Reserved for Large Models
mini/nano have pushed the boundary forward. Moving forward, many tasks that previously required mid-range or even large models will be taken over by cheaper, faster small models, leaving only the most difficult parts for the large models.
3) Agent Workflows Will Shift from “Can It Be Done” to “Is It Worth Doing”
As the unit costs for subagents, parallel tasks, and batch multimodal understanding continue to fall, teams will be increasingly willing to integrate agentic workflows into their core product processes. Future discussions about agents won’t just ask “can it do it,” but more frequently “is it worth it, and can it scale?”

