Digital Strategy Review | 2026
SerpApi Fights Back Against Google’s DMCA Lawsuit: The Escalating Battle Over SERP Scraping Rights | Mr. Guo’s SEO Daily
By Mr. Guo · Reading Time / 10 Min
Foreword
If you view SEO as merely “tweaking titles, stuffing keywords, and chasing rankings,” today’s news will be a wake-up call: what truly defines the boundaries of the industry is often not the algorithm details, but the rules themselves—especially the question of “who can legally and reliably access SERP data.”
For over a decade, SERP scraping, rank tracking, competitor analysis, and sentiment monitoring have all relied on a default premise: search results are publicly visible, and third parties can, within certain boundaries, access and analyze them via automation. But now, the DMCA lawsuit between Google and SerpApi has brought this premise to court.
The outcome of this case could directly impact whether your monitoring tools remain functional, whether your explanations for ranking fluctuations remain grounded in evidence, and whether the future compliance costs for the “SEO tool industry” will skyrocket.
As a user of SerpApi myself, I rely heavily on this service for my SEO agents to fetch and analyze SERPs. Furthermore, as far as I know, many automated tools for international trade development also depend on it.
01
Today’s Headline News
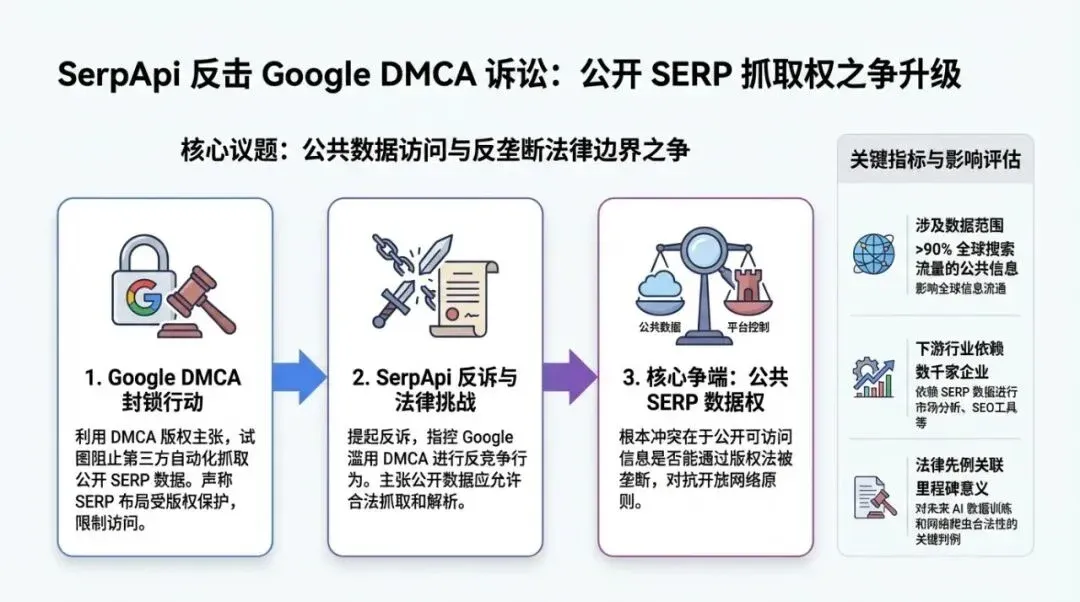
On February 20, 2026, SerpApi filed a motion with the court to dismiss the federal DMCA lawsuit brought by Google. The core arguments are:
-
• Google is not the copyright holder of the information displayed on its SERP pages.
Therefore, it lacks the legal standing to claim damages based on the DMCA.
-
•
SerpApi maintains that it accesses “publicly available webpages that any ordinary browser can access,” and has not engaged in “circumvention” in the sense defined by the DMCA.
-
•
SerpApi also cites the framework from Lexmark v. Static Control (2014) regarding standing/zone of interests, arguing that the damages claimed by Google (infrastructure costs, loss of ad revenue, etc.) are not the interests the DMCA was intended to protect.
According to reports, the relevant hearing date is set for May 19, 2026. For the SEO industry, this is not just a dispute between two companies, but a boundary test of “whether platforms can use copyright law to control access to public search results.”
Cross-referenced sources (at least two independent industry media outlets):
-
•
Search Engine Journal: https://www.searchenginejournal.com/serpapi-challenges-googles-right-to-sue-over-serp-scraping/568084/
-
•
Search Engine Land: https://searchengineland.com/serpapi-motion-dismiss-google-scraping-lawsuit-469889
-
•
The Verge (a more consumer-oriented perspective): https://www.theverge.com/news/602811/serpapi-google-lawsuit-scraping-search-results
02
Headline Analysis: Why This Matters More
This lawsuit deserves to be the headline not because it is close to “daily optimization,” but because it could change the foundation we rely on: the accessibility and sustainability of SERP data.
1) The “Invisible Public Infrastructure” of the SEO Tool Industry May Be Repriced
Rank tracking, SERP feature tracking (Featured Snippets, AI Overviews, video/local packs, etc.), competitor benchmarking, and brand positioning—the common input for all these actions is stable, scalable SERP data.
If a platform can use the DMCA’s “anti-circumvention” logic to restrict automated access to public pages, the risk for third parties will escalate from “technical confrontation (anti-scraping)” to “legal uncertainty.” This means:
-
•
Tool providers may need to invest more heavily in compliance and legal affairs, with increased costs passed on to subscription prices.
-
•
Data sources may shift from “self-scraped” to “licensed/aggregated,” increasing industry concentration.
-
•
Small and medium-sized teams will become more dependent on official data interfaces provided by platforms (Search Console, Merchant Center, etc.), which may not meet all needs in terms of granularity and timeliness.
In short: When SERP data is no longer “available by default,” many SEO capabilities will be forced back into a slower, more expensive, and less certain state.
2) This is Also Platform Strategy in the AI Era: Controlling “Observability” Means Controlling the Ecological Niche
Today’s Google is not just a search company; it is transforming search into a more powerful “answer system” and “transaction system.” As search result pages increasingly carry more AI-generated content and closed-loop interactions (completing information acquisition/purchases without clicking out), the platform cares less about anti-scraping itself and more about controlling external observability for ecosystem participants.
For the platform, once SERP data is scraped at scale:
-
•
Third parties can train “models that understand SERPs better” faster and replicate product experiences more quickly;
-
•
The commercial structure of ads vs. organic results becomes easier to quantify and compare;
-
•
The barrier to entry for competitive intelligence is lowered.
Therefore, what we are seeing is not an isolated conflict, but a long-term trend: platforms will gradually turn “data visibility” from a technical issue into a rule-based issue.
3) For Webmasters/Brands, the Most Realistic Change is: Don’t Mistake a “Single Monitoring Channel” for the Truth
Regardless of the lawsuit’s outcome, the industry is already forced to face a fact: monitoring systems that rely on a single channel, a single tool, or a single scraping method will become increasingly fragile in the future.
What you need is “multi-dimensional” observability:
-
•
Real clicks and impressions from Search Console (even with delays).
-
•
User behavior from on-site logs and analytics (dwell time, conversion, path).
-
•
Comparisons across multiple search engines/markets (Google/Bing/regional searches).
-
•
Monitoring of being “cited/recommended” by AI results (AIO, ChatGPT, Perplexity, etc.).
When SERPs become harder to scrape, you need to strengthen your “first-party data” and “multi-source cross-referencing.”
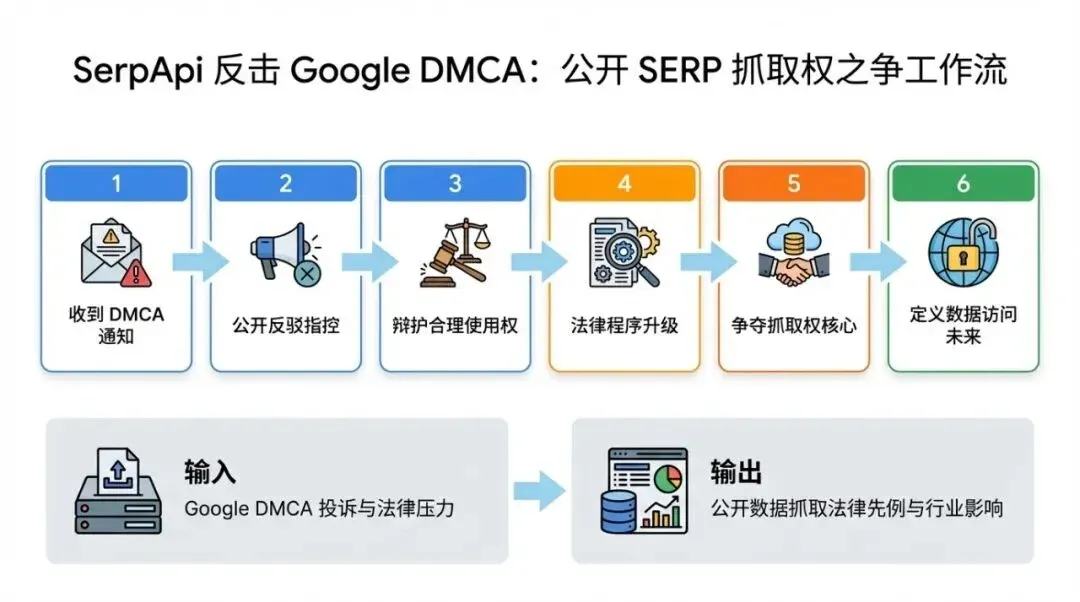
Flowchart used to explain the methodological execution path.
03
Mr. Guo’s Perspective
I suggest treating this lawsuit as a “stress test” to verify whether your team’s SEO system is overly dependent on externally scraped data.
Here are three actionable steps (you can do these today, without waiting for the verdict):
Action 1: Shift Key Metrics from “Rankings” to “Business Interpretability”
-
•
Define 2-3 metrics for each core page that explain business performance: search clicks, effective arrivals, conversions, lead quality, etc.
-
•
Rankings can be observed, but should not be treated as the sole causal explanation; especially with fluctuations in AI Overviews and Discover traffic, the relationship between rankings and clicks is increasingly unstable.
Action 2: Design Tools and Data Sources to “Avoid Single Points of Failure”
-
•
Maintain at least two data sources (or two sets of methodologies) for similar monitoring tasks: avoid a total blackout if one tool or scraping method fails.
-
•
Clarify SLAs with tool providers: alerts for data anomalies, compensation mechanisms, and historical data backfilling strategies.
Action 3: Proactively Engineer for “AI Visibility” and “Content Citability”
SEO is shifting from “getting pages indexed” to “getting content cited and selected by answer systems.” I suggest treating GEO/AEO as an engineering problem:
-
•
Build structured entities and attributes for core topics (Schema, FAQ, product/service lists).
-
•
Make content easier for machines to parse and reuse: definitions, comparisons, steps, tables, and verifiable data points.
-
•
Establish “citation monitoring”: track whether your brand/page appears in AI results, and on which queries.
The sooner you build these into a system, the less you will fear changes in external rules.

Data chart used to explain key comparisons and conclusions.
04
Other Headline News at a Glance
Google Discover February 2026 Update: Visibility Becomes More Concentrated, Local and X Content Rises
Early third-party tracking data shows that the number of unique domains in US Discover results has decreased, but the range of topics covered is expanding; meanwhile, the share of local content and X.com posts has increased in some views. Such changes directly impact media and content sites that rely on Discover.
-
•
GEO (Generative Engine Optimization) Moves from Concept to Methodology: Optimization Goal Shifts from “Ranking” to “Being Cited”
Multiple industry outlets are systematically organizing GEO as an independent discipline, emphasizing readability for AI crawlers, structured data, brand credibility, and content formats that are “answerable.”
-
•
https://www.searchenginejournal.com/geo-generative-engine-optimization/568078/
Google Search Console Page Indexing Report Shows Missing Historical Data
Multiple reports indicate that the GSC page indexing report is missing data prior to December 15, which appears to be a reporting/display glitch by Google rather than an issue with the sites themselves. In such cases, it is recommended to focus on trends and avoid misjudgments based on single-point screenshots.
-
•
-
•
https://www.seroundtable.com/google-search-console-page-indexing-report-missing-data-40976.html
Google Business Profiles See AI-Generated Service Lists and Stronger Fake Review Governance
Local panels are being “semi-automatically” populated by AI: service lists, descriptions, and governance actions are becoming more frequent. For local businesses, the importance of information consistency and review compliance continues to rise.
-
•
https://www.seroundtable.com/google-business-profiles-ai-generated-services-40970
-
•
Semrush Launches Content Rewriting Tool for ChatGPT / AI Overviews
SEO tool providers are beginning to market “AI-citability” as a feature; content production will increasingly emphasize structure, verifiability, and coverage, rather than just keyword density.
-
•
https://www.semrush.com/blog/optimize-content-for-llms-with-semrush/
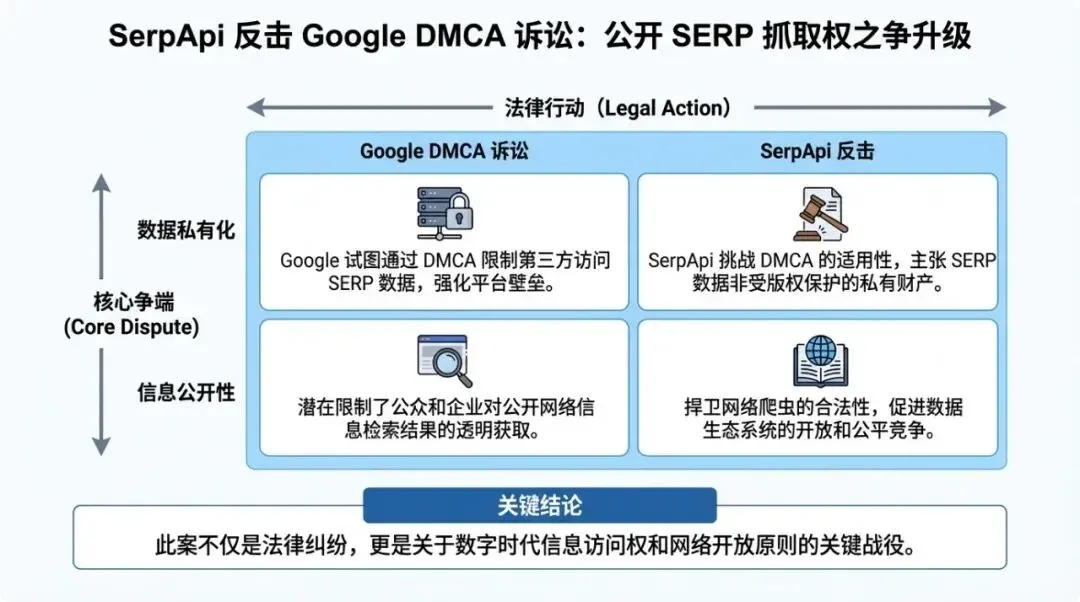
Matrix chart used to illustrate applicability boundaries and strategy selection.
05
Trends and Opportunities
-
SEO’s focus is shifting from “ranking engineering” to “visibility engineering”: you need to monitor not just the 10 blue links, but AI Overviews, Discover, video/local, and citations in answer systems.
-
Data compliance and observability are becoming a moat: as scraping becomes harder and rules become more numerous, teams with stable data channels and first-party data will operate more steadily.
-
Content strategy will increasingly resemble product design: to be selected by AI, you need clearer definitions, comparisons, steps, evidence chains, and entity structures; this will force content teams to collaborate more closely with product/R&D.
-
E-commerce and transactions will be rewritten by “AI gateways”: as platforms push for more closed-loop shopping experiences (from information acquisition to transaction), the opportunity for brands lies in structuring product/service information and making reputation and credibility “machine-readable.”

