Word count: ~3500 words
Estimated reading time: ~10 minutes
Last updated: August 25, 2025
Is this article for you?
✅ Power users puzzled by AI Agent’s astronomical token consumption.
✅ Tech enthusiasts and developers wanting to understand AI Agent’s underlying “thinking process.”
✅ Product managers or decision-makers planning to introduce AI Agents into business and needing cost assessment.
✅ Efficiency maximalists seeking effective strategies to reduce Agent usage costs.
Chapter Contents
- Introduction: My “Token Shock” moment
- Infrastructure: First step in managing costs
- Paradigm Shift: From “chatting” to “outsourcing a brain”
- Cognitive Loop: Token consumption’s four-act play
- Case Studies: How tokens get “burned”
- Conclusion: What exactly are we paying AI for?
1. Introduction: My “Token Shock” Moment
Hey, I’m Mr. Guo.
As a deep AI user and indie developer, I’ve always been sensitive to token consumption. But a recent experience using Claude Code CLI for a complex task still gave me genuine “token shock.” I just gave a seemingly simple instruction: “Analyze this GitHub repository, summarize its core architecture, and propose refactoring suggestions.” Half an hour later, the task was completed excellently, but when I checked the bill, this single task had “burned” over 50,000 tokens.
That number equals having the model write half of Harry Potter and the Philosopher’s Stone. This got me thinking: Why does seemingly simple interaction hide such shocking consumption? What exactly is happening behind the scenes? Today, I’ll deconstruct the secrets behind AI Agent “astronomical” token consumption from first principles.
2. Infrastructure: First Step in Managing Costs
Before deep-diving into cost structure, we must first address a more fundamental question: How do we make this expensive “investment” controllable and predictable? A platform with vague billing and unstable service only makes cost problems worse.
Precisely because AI Agent token consumption is massive, we need a professional platform providing clear billing and stable performance. This is why I recommend Yoretea Claude Code (code.yoretea.com) to all power users and teams.
-
Clear billing, controllable costs: It provides clear packages and usage statistics, making every investment crystal clear for cost accounting and ROI analysis.
-
Stable performance, avoiding waste: Dedicated line optimization ensures Agents won’t interrupt or retry during complex multi-step tasks due to network issues — itself a safeguard against token waste.
-
Convenient payment, focus on value: Simple payment methods free you from tedious overseas payment processes to focus on maximizing AI Agent application value.
When you view an Agent as an expensive “expert employee,” providing them a stable, efficient “office” becomes crucial.
Don’t forget my exclusive benefit helping you start your Agent journey more confidently:
Mr. Guo’s Exclusive 20% Off Code: GUOSHU
3. Paradigm Shift: From “Chatting” to “Outsourcing a Brain”
To understand token consumption’s essence, we must first undergo a mental paradigm shift.
Having an ordinary conversation with ChatGPT is like Q&A with a knowledgeable expert. You ask, they answer. This process’s token consumption is mainly the length of “question” and “answer” themselves.
Using an AI Agent is completely different. You’re not doing Q&A — you’re outsourcing a complete cognitive process. It’s like you’re no longer simply asking an expert a question, but throwing them a project brief saying: “Go, get it done, but you need to completely document all your thinking steps, every reference consulted, every decision process in written form, then report back to me.”
Key Takeaway
AI Agent’s high token cost is essentially the fee you pay for machine “thinking process transparency.” What we see isn’t just the final result, but every step of reasoning, planning, and tool-calling it performed to reach that result.
4. Cognitive Loop: Token Consumption’s Four-Act Play
To make this more concrete, I’ll break it down into the classic OODA cognitive loop: Observe, Orient, Decide, Act. Each step is a massive token consumption point.
Act 1: Observe — Drawing the World Map
The moment you issue an instruction, you’re not just sending your question — you must also tell the Agent what “world” it’s in. This includes passing all available tools’ “manuals” (Tool Schema) to it. These manuals are extremely detailed, describing each tool’s function, parameters, format, etc.
Token consumption point: Your instruction + detailed definition documents for all available tools.
Act 2: Orient — Internal Monologue & Strategic Planning
This is the most core and token-consuming part. The Agent conducts an “internal monologue.” It breaks your goal into a detailed step checklist, analyzes which tool each step needs, and plans the entire execution path. This process is typically recorded completely in XML or JSON format.
Token consumption point: Extremely detailed structured text (like XML) generated by the model describing thinking process and action plan.
Act 3: Decide & Act — Filing Applications & Reporting Results
For each planned step, the Agent generates a precise tool-calling instruction (like a JSON object). When the tool finishes executing, its return result (possibly another massive JSON data, or code, or webpage content) is completely fed back to the Agent as basis for its next thinking step.
Token consumption point: N cycles of [tool-calling instruction + tool return result]. This is multiplicative — easily causes token explosion.
Act 4: Reflect — Final Summary
After collecting all information, the Agent performs final comprehensive analysis of all intermediate steps and results, then generates the well-organized, human-readable final answer we see.
Token consumption point: Model’s final reasoning on all context and generating structured final report.
5. Case Studies: How Tokens Get “Burned”
Theory isn’t enough — let’s intuitively feel how tokens are consumed through real cases.
Case 1: Analyzing a Medium-Sized GitHub Repository
Suppose the task is analyzing a medium codebase with hundreds of files. Agent’s thinking process and token consumption might be:
| Cognitive Phase | Specific Action | Token Estimate |
|---|---|---|
| Observe | User instruction + Schema definitions for Git/file/code analysis tools | ~2,500 |
| Orient | Generate complex internal monologue, plan dozens of steps for traversal, reading, analysis, summary | ~5,000 |
| Act | Call ls -R to list massive file tree, return result | ~15,000 |
Loop call cat to read 10 core files’ content, return results | ~40,000 | |
| Call code analysis tool, return complex dependency graph JSON | ~8,000 | |
| Reflect | Integrate all information, write extremely detailed analysis and recommendation report | ~15,000 |
| Total | ~85,500 |
Case 2: From “One Sentence” to a Snake Game
This case goes further, showing how tokens “snowball” during multi-round iterative development. User just said “please create a snake game for me,” and Agent began a series of planning, coding, correction cycles.
| Cognitive Phase | Specific Action | Token Estimate |
|---|---|---|
| Initial Planning | User instruction + Tool Schema -> Generate 6-step TODO List | ~2,500 |
| Multi-Round Iterative Dev (Context Accumulation Effect) | In 4-5 cycles, Agent continuously: 1. Updates TODO status 2. Writes/modifies code (snake_game.html) 3. Receives execution results. Each round, it must resend all previous conversation history and complete generated code as context, causing token consumption to explode | ~120,000 |
| Final Delivery | Complete all TODO tasks, give final confirmation | ~5,000 |
| Total | ~127,500 |
This case vividly reveals Agent mode’s most terrifying cost trap: context snowball. To maintain task continuity, each interaction builds on the previous one, leading to nonlinear token consumption growth.
Case 3: Real Cost Bills — Not Just Claude Code
You might think this is unique to Claude Code? Quite the opposite. This is nearly a “physical law” shared by all advanced AI Agent systems. To verify, I recently used another Agent called Codex to make some minor modifications to my blog site — process took about an hour.
The result made me gasp. Input tokens, including cache generated for maintaining context memory, total soared to an astonishing 15+ million!
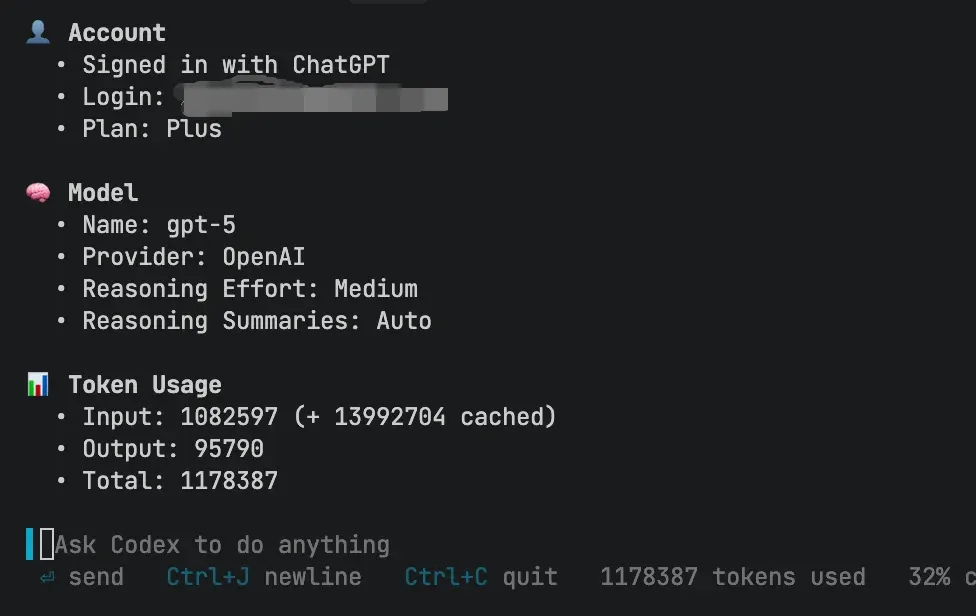
Astronomical tokens ultimately translate to real bills. I’ve also tried some seemingly cheap domestic alternatives, like Alibaba Cloud’s Qwen Coder, but quickly received overdue payment notices due to expensive “cache token” billing. Look at their pricing model — you’ll find that for Agent scenarios consuming millions of tokens, what truly determines cost is high-volume tier pricing and that inconspicuous “cached input price.”
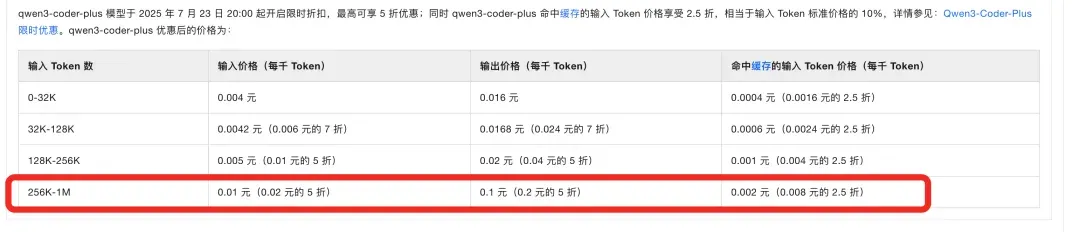
Quick calculation: my under-one-hour blog modification work, if run on this platform, could easily cost dozens of yuan. And that’s just one person’s, one hour’s, minor modification work! This clearly reveals a fact: Agent’s powerful capabilities come at the cost of massive computational resources and token consumption, regardless of which vendor’s service you use — this underlying logic cannot change.
I also feel true AI technology equality is still far off. Currently these AI tools’ usage prices are so expensive, meaning a portion of people will be excluded. And the enormous productivity gap this creates will further widen income disparity.
6. What Exactly Are We Paying AI For?
Understanding AI Agent’s token consumption mechanism, we should reach a clear conclusion: What we pay for isn’t just the “answer’s” cost, but the cost of purchasing machine’s “structured thinking process.”
What this “fee” buys is core value traditional AI couldn’t provide: autonomous planning, tool-calling, and ability to solve complex problems. This is a huge leap from “knowledge Q&A” to “task execution.”
Therefore, as drivers, our strategy should change accordingly:
-
Define goals precisely: Vague instructions make Agents do lots of ineffective exploration, burning massive tokens. The more precise the instruction, the shorter its thinking path, the lower the cost.
-
Choose appropriate tools: Don’t use a sledgehammer to crack a nut. Simple text generation tasks don’t need complex Agent mode.
-
Focus on ROI, not absolute cost: Think about how many hours of manual labor this Agent task saved you. If it uses 100,000 tokens (roughly a few to ten-plus dollars cost) to complete half a day or even a full day’s work, that investment’s ROI is astonishing.
Found Mr. Guo’s analysis insightful? Drop a 👍 and share with more AI-curious friends!
Follow my channel to explore AI, going global, and digital marketing’s infinite possibilities together.
🌌 We’re entering an era of paying for “machine thinking.” Learning to manage and harness this thinking will be the most important capability of the next decade.
