之前相当长的一段时间,我们都说做好结构化数据 Schema、JSON-LD,对做好 AI SEO,也就是现在很多人讲的 GEO,至关重要。或者保守一点说,至少大家都认为这件事和 AI 搜索引荐是正相关的。
这个判断听起来很合理。毕竟 AI 本身好像就偏好结构化、规整、容易解析的内容。甚至很多人开始不惜把文章也改写成那种一板一眼的结构化格式,标题下面套定义,定义下面套列表,列表下面再来 FAQ。当然,这么做的人,应该也吃了一些苦果了。
我们很多时候都会低估 Google 搜索的智商,或者说低估大部分前沿 AI 模型的理解能力。在实践中,你并不是在针对一个 30B 的小模型做优化。你真正面对的,是 GPT、Claude、Gemini 这一类顶级大模型,以及它们背后一整套搜索、检索、排序、引用和质量评估系统。对这些系统来说,内容是不是结构化,当然有意义。但如果你把“结构化”理解成把信息压扁、切碎、塞进模板里,那问题就来了。越简单、越规整、越像给机器看的内容,很多时候反而越缺少信息深度、判断密度和真实语境。
接下来我要分析的这项 Ahrefs 研究,就在一定程度上说明了这个问题。它不是说 Schema 没用。它说的是,至少从这组数据看,给页面新增 JSON-LD Schema,并没有明显提升这些页面在 Google AI Overviews、Google AI Mode 和 ChatGPT 里的引用表现。以后如果还有人很笃定地告诉你,“做好 GEO 就是要先做好 Schema 结构化数据”,你可以先别急着反驳,你可以把这项研究甩给他看。
这项研究到底测了什么
Ahrefs 这篇研究发布于 2026 年 5 月 11 日,标题很直接,叫《We Tracked 1,885 Pages Adding Schema. AI Citations Barely Moved.》它测的不是 Schema 的全部 SEO 价值,而是一个更具体的问题:页面新增 JSON-LD Schema 之后,AI 搜索引用次数有没有明显增加?
注意,这里的关键词是“新增”。Ahrefs 先分析了大约 600 万个 URL,发现一个现象:被 AI 引用的页面,确实更常见 JSON-LD Schema。按照他们的说法,被 AI 引用的页面使用 JSON-LD 的概率,接近未被引用页面的 3 倍。这就是很多 GEO 文章最喜欢拿来讲的地方。你看,AI 引用页面更常有 Schema,所以 Schema 很重要。听起来是不是很顺?
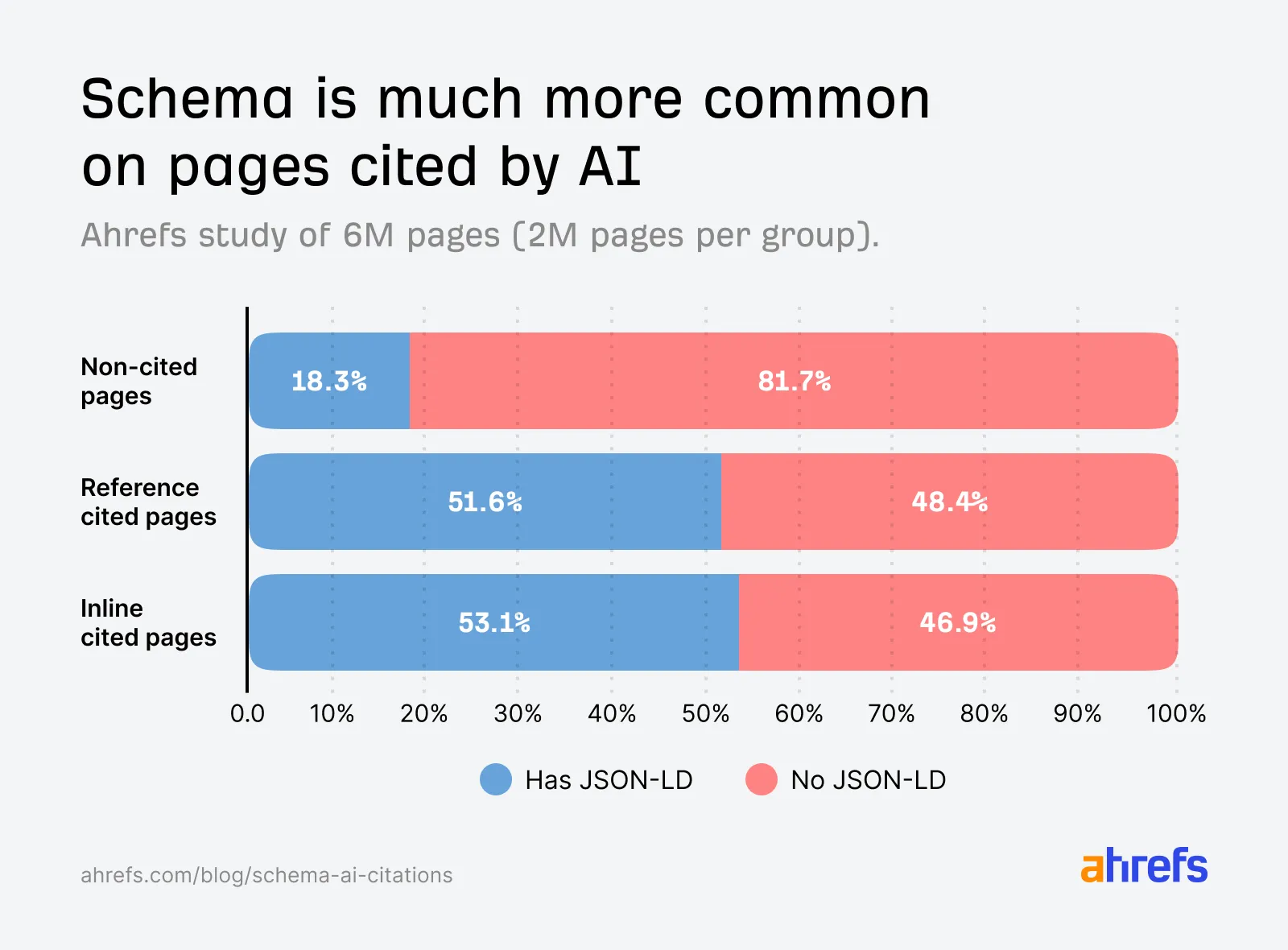
这张图就是最容易被人拿去做“Schema 很重要”论据的地方:非引用页面里,只有 18.3% 有 JSON-LD;被 AI 引用的 reference cited pages 里,这个比例到了 51.6%;inline cited pages 里更高,到了 53.1%。如果只看到这里,你很容易得出一个很直接的判断:AI 喜欢引用有 Schema 的页面。
但顺不代表对。
Ahrefs 自己也意识到,这个数据只能说明相关性,不能说明因果性。因为一个网站会认真做 Schema,往往也说明它在其他方面做得不差。比如技术 SEO 更规范,内容维护更勤,站点权威更强,外链更多,页面更新更稳定,品牌本身也更可信。也就是说,Schema 可能不是原因,它可能只是“好网站常见的一种表征”。就像你看到很多优秀学生都带笔记本,不能反过来说,只要买个笔记本成绩就会变好。笔记本可能有帮助,但它不等于学习能力本身。
为了继续往下验证,Ahrefs 做了第二步。他们从自己的爬虫历史里追踪页面 HTML,标记一个 URL 从“没有 <script type="application/ld+json">”变成“有 JSON-LD”的时间点,把这个时间点当作 treatment date。最后,他们找出了 1,885 个在 2025 年 8 月到 2026 年 3 月之间新增 JSON-LD Schema 的页面,然后给这些页面匹配了约 4,000 个对照页面。对照页面来自不同域名,之前的 AI 引用水平相近,但没有新增 JSON-LD。这一步就比单纯看相关性有价值多了,因为它更接近我们真正关心的问题:如果我现在给页面加 Schema,到底能不能拿到更多 AI 引荐?

上面这张图是 Ahrefs 原文给出的实验设计,核心信息其实很简单:一组页面新增 JSON-LD,一组相似页面不新增,然后观察它们在 Google AI Overviews、Google AI Mode 和 ChatGPT 里的引用变化。
研究结果很冷静,也有点不好看
Ahrefs 观察了三个平台:Google AI Overviews、Google AI Mode、ChatGPT。结果大概是这样:Google AI Overviews 里,新增 Schema 的页面相对对照组下降了 4.6%;Google AI Mode 里,上升了 2.4%;ChatGPT 里,上升了 2.2%。
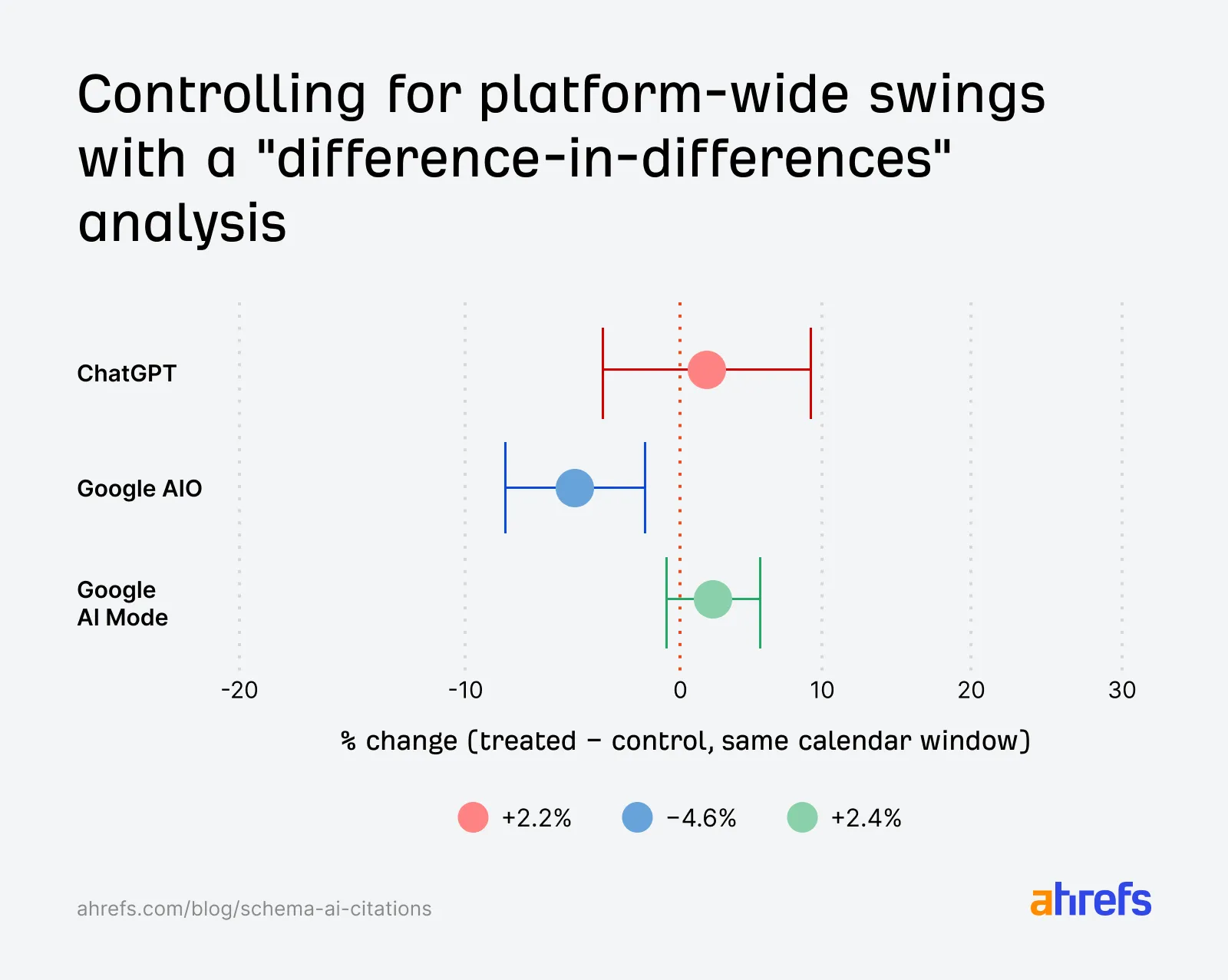
如果只看数字,你可能会说,那 AI Mode 和 ChatGPT 不是也涨了吗?问题在于,这两个涨幅在统计上接近噪声。也就是说,它们太小了,小到很难判断到底是 Schema 起了作用,还是平台整体波动、页面本身变化、抓取周期、内容更新、引用池变化造成的。
Google AI Overviews 的 -4.6% 倒是统计上更明显一些,Ahrefs 原文说,纯随机看到这么大差距的概率大约是 1/2500。但他们也没有把它粗暴解释成“加 Schema 会伤害 AI 引用”。这是这篇研究比较值得肯定的地方。它没有为了标题党把结论说满。Ahrefs 说得很谨慎:AI Overviews 的下降是真实观察到的,但绝对幅度不大,平均到页面上大约是每天少 12 次引用,而且无法单独归因给 Schema。因为这些页面和对照页面在新增 Schema 之前,本来就处在下降趋势里。也可能是 Google AI Overviews 在那个阶段调整了引用策略,也可能是部分内容变旧了,也可能是 Google 还没有及时重新抓取页面。
所以最稳妥的结论是:新增 JSON-LD Schema,没有在这些已经被 AI 引用的页面上带来明显正向提升。这句话很重要。它比“Schema 没用”更准确,也比“Schema 对 GEO 至关重要”更接近事实。
Ahrefs 不只看了一张结果图
这一点也要补上,否则很容易把研究讲薄。
Ahrefs 不是只做了一次简单的前后对比,然后看涨跌。他们一共用了四种检验方式,试图把平台本身的波动从 Schema 的影响里剥离出来。
第一种,是直接看 treated pages 和 control pages 在新增 Schema 前后的平均引用变化。这个视角最直观,但也最容易受平台整体趋势影响。比如某段时间 Google AI Mode 整体引用量都在上涨,如果你只看新增 Schema 的页面涨了,就很容易误以为是 Schema 带来的。
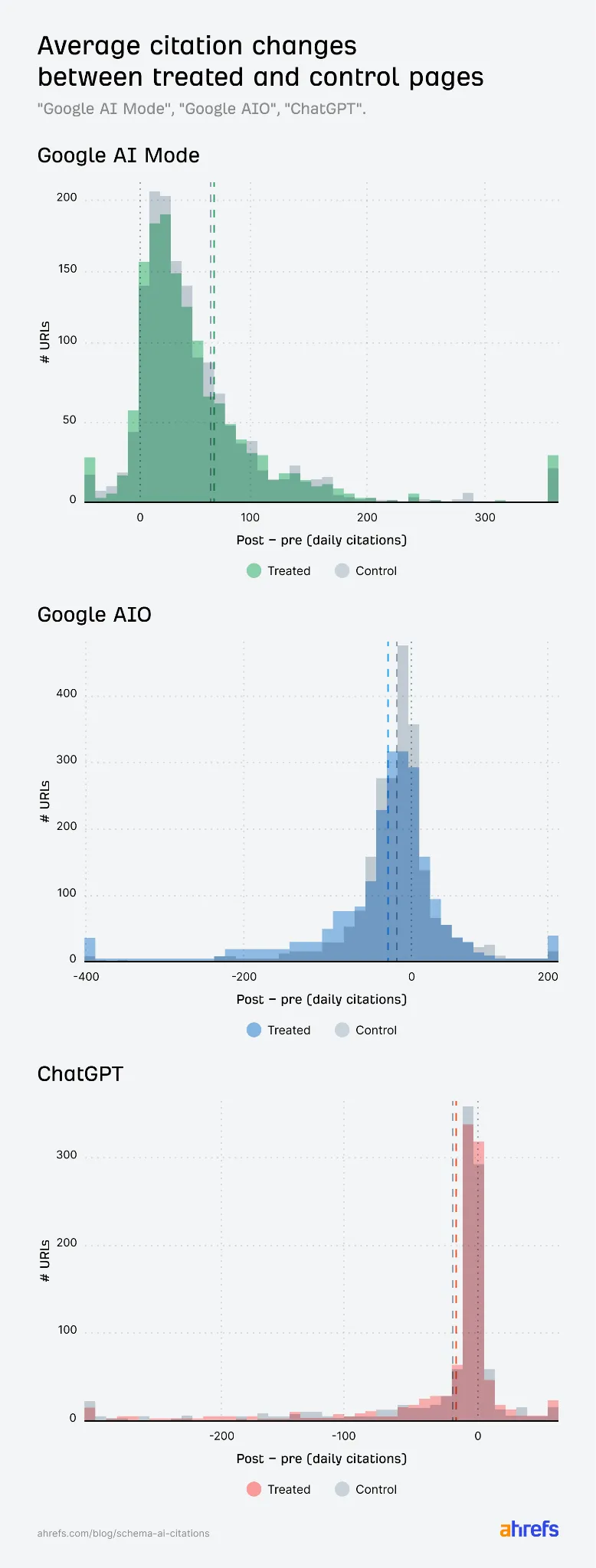
第二种,是他们最看重的 difference-in-differences,也就是差分中的差分。简单说,就是不要只问“加了 Schema 之后有没有涨”,而是问“加了 Schema 的页面,有没有比没加 Schema 的相似页面涨得更多”。这才更接近我们真正想知道的因果问题。
第三种,是 event study,也就是按周看走势,观察 treated pages 和 control pages 在新增 Schema 之前是不是已经开始分道扬镳。如果两组页面在新增 Schema 前就走势不同,那后面再把差异归因给 Schema,就很危险。
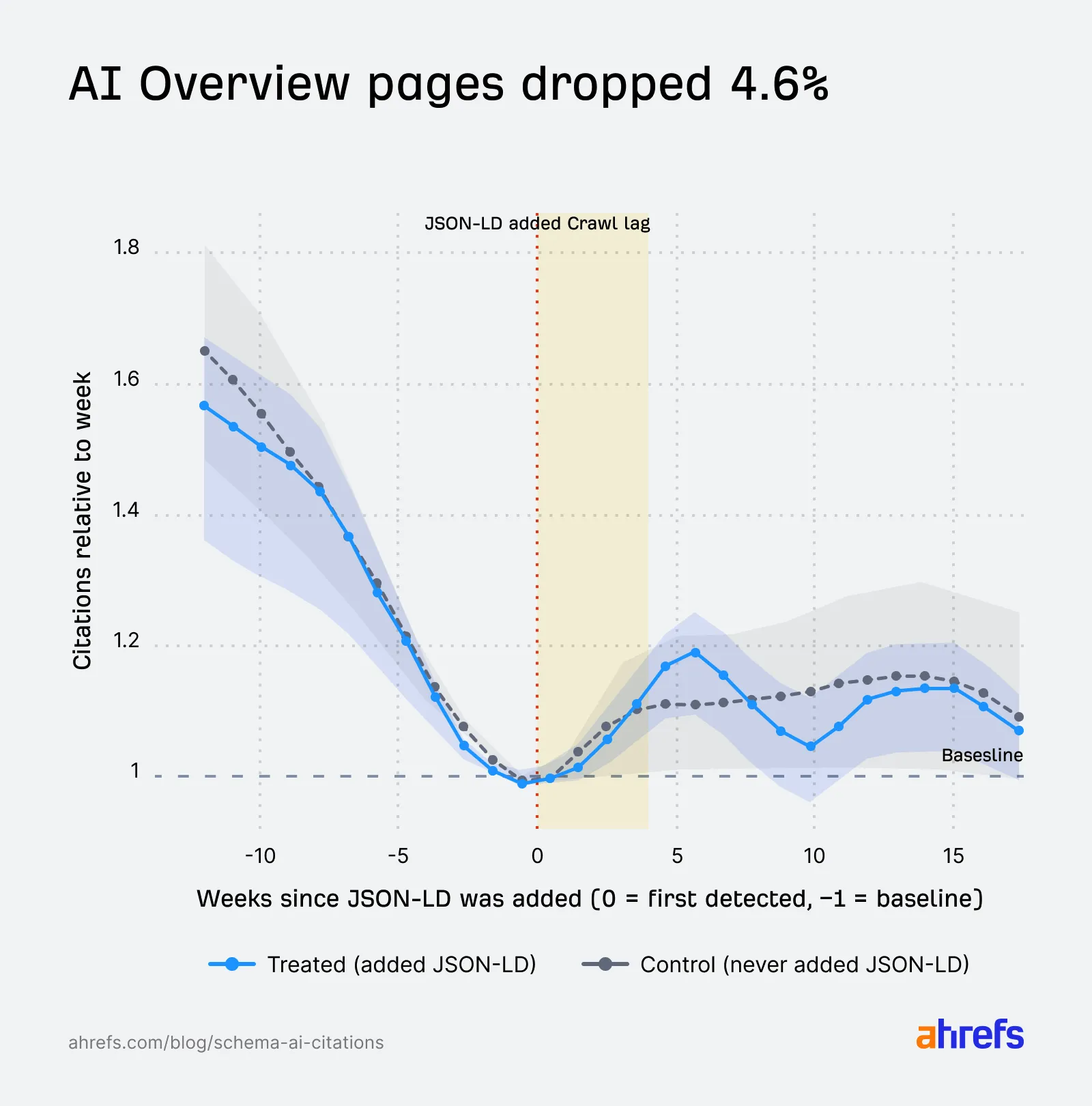
这张图对应 Google AI Overviews。你能看到,在新增 JSON-LD 之前,两组页面本来就在一起下降。新增之后,treated pages 的表现略低于对照组,但整个背景是 AIO 引用本身就在收缩。所以这就是为什么 Ahrefs 没有直接说“Schema 伤害了 AI Overviews 引用”。它只能说观察到了一个小幅下降,但原因还不能钉死。
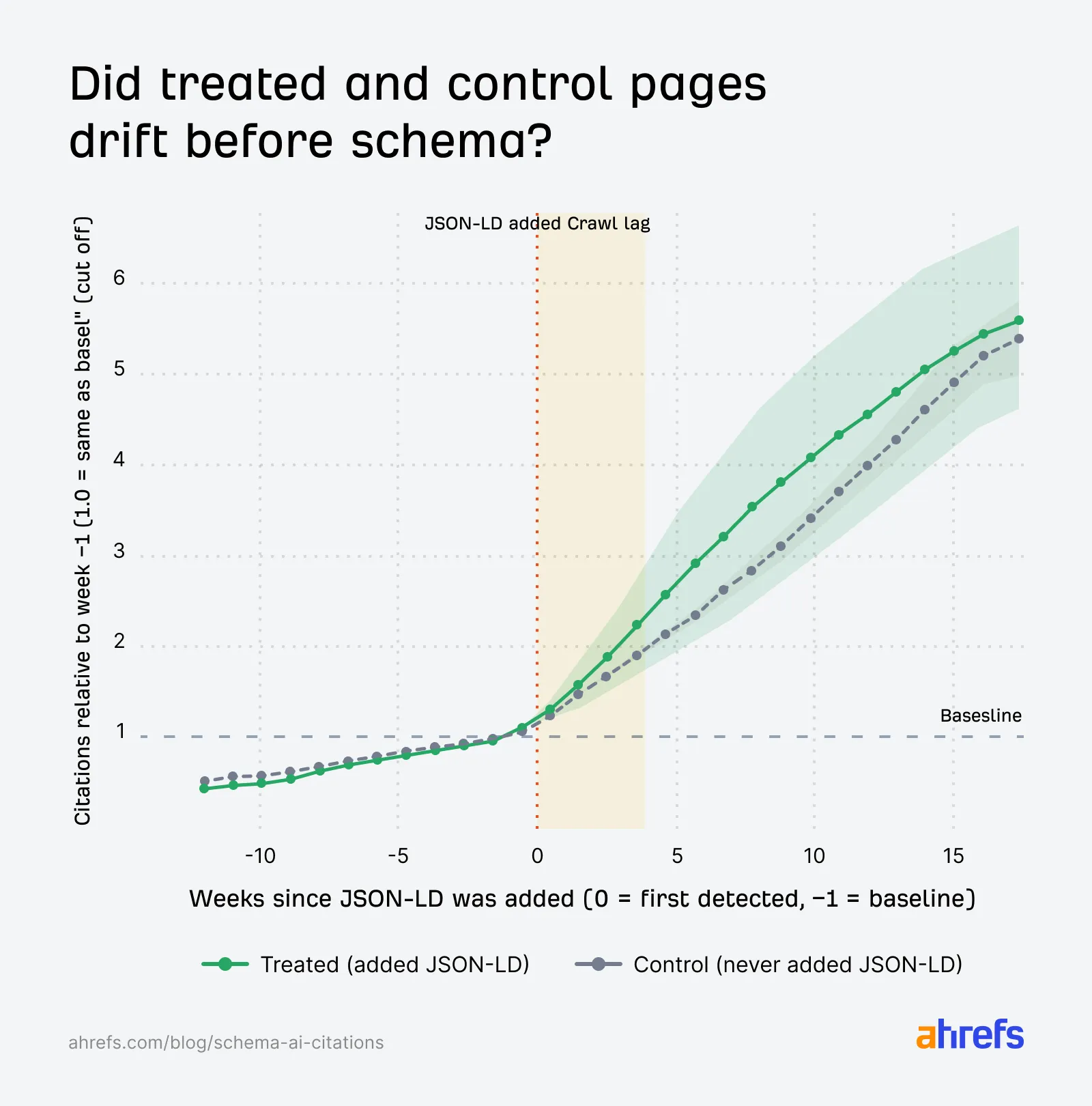
这张图用来检查 treated pages 和 control pages 在处理之前有没有明显漂移。你会发现,两组线在新增 JSON-LD 前后的方向基本是一起走的。换句话说,如果后面大家都涨,或者大家都跌,不能立刻归因给 Schema,因为它可能只是平台整体环境变了。
第四种检验,是 Ahrefs 又换了不同的 before / after 时间窗口,再跑一次 DiD,看结果是否稳定。如果换一个窗口结论就变了,那说明研究很脆弱。但从这张图看,不同窗口下的大方向基本一致:ChatGPT 和 Google AI Mode 的置信区间都跨过 0,Google AIO 依然偏负。
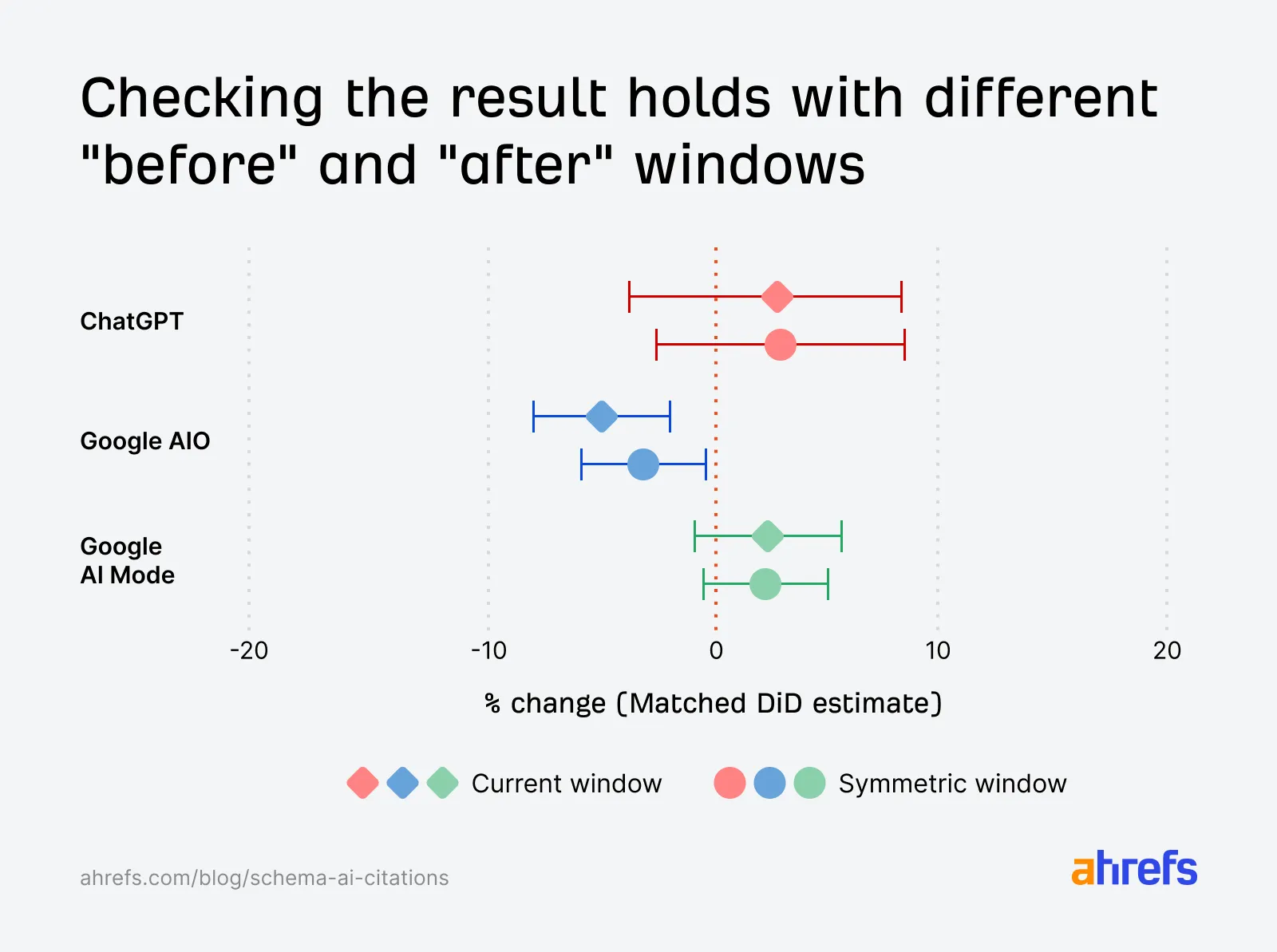
所以这项研究真正有价值的地方,不只是它给了一个“没明显提升”的结论,而是它把常见的几个误读都尽量堵住了。它没有只看新增 Schema 前后有没有变化,也没有只看某个平台某段时间有没有涨,而是反复问同一个问题:这件事有没有比对照组带来更多增量?答案目前看起来并不乐观。
这项研究的边界也要讲清楚
不过,研究边界也不能漏。
Ahrefs 这次研究的页面,并不是完全没有被 AI 看见的冷启动页面。原文里说得很清楚,数据集里的页面在 2025 年 2 月之前,每个页面都已经有 100 次以上 AI Overviews 引用。也就是说,它研究的是“已经在 AI 引用池里的页面,加 Schema 之后会不会更好”,而不是“一个完全没被 AI 发现的页面,加 Schema 能不能帮它被发现”。
这个区别很重要。
如果一个页面本来就没有被抓取、没有被索引、没有进入任何候选集,那 Schema 是否会在更早阶段帮助搜索系统理解页面,Ahrefs 这组数据不能直接回答。它能回答的,是另一个更现实的问题:如果你的页面已经能被 AI 引用,想靠新增 JSON-LD 把引用量再拉一截,证据并不支持这个期待。
原文还提了几个限制。第一,不同 Schema 类型被放在一起分析了,Article、FAQ、Product、HowTo、Organization 这些类型可能效果不一样。第二,观察窗口主要是新增后的 30 天,如果 Schema 存在更慢的滞后影响,这组数据未必完全看得出来。第三,页面新增 JSON-LD 的同时,可能也做了内容、链接或技术修复,研究虽然做了对照,但不可能把所有共变因素拆得一干二净。第四,这里主要看的是 HTML 里的 JSON-LD,不等于所有结构化数据实现方式都被完整测试过。
这些边界讲出来,不是为了削弱研究价值,而是为了避免另一个极端:从“Schema 没有明显提升 AI 引用”,一下跳到“Schema 完全没用”。这就又变成另一种标题党了。
相关性不是因果性,这是 SEO 里最容易被忽略的坑
SEO 行业很喜欢相关性。因为相关性容易做图,容易做报告,也容易卖方案。被 AI 引用的页面更常有 Schema,排名靠前的页面字数更多,高流量页面外链更多,转化好的落地页加载更快,这些观察都可能是真的,但每一条都不自动等于因果关系。
真正麻烦的地方在于,很多 SEO 变量不是孤立发生的。一个会认真做 Schema 的网站,往往也会认真做内容结构、内链、页面体验、作者信息、产品信息、品牌露出、外部传播和技术维护。一个会被 AI 引用的页面,也往往不是因为某一个标签写对了,而是因为它本来就更像一个可信答案来源。
所以当你看到“AI 引用页面更常有 Schema”,它可能有三种解释。第一,Schema 真的帮助 AI 理解页面,所以带来了更多引用。第二,Schema 没有直接带来引用,但它帮助搜索引擎更好理解实体、页面类型和知识关系,间接改善了页面在整个搜索系统里的表现。第三,Schema 只是好网站身上常见的一个技术特征,真正让页面被引用的是内容质量、权威性、链接、品牌和用户需求匹配。
Ahrefs 这项研究,并没有彻底否定第一种和第二种可能。但它至少告诉我们:如果你已经有一批被 AI 看见、被 AI 引用的页面,仅仅新增 JSON-LD,不太可能让引用量明显上涨。这对很多正在做 GEO 的团队来说,是一盆很必要的冷水。
为什么 AI 不一定吃你那套“结构化内容”
这里我想多说一句。很多人对 AI 搜索的想象,仍然停留在“机器读网页很笨,所以我要把内容喂得足够规整”。这个判断在某些场景里没错。比如商品价格、库存、评分、作者、发布时间、组织信息、面包屑导航,这些信息本来就适合结构化。你用 Schema 把它标出来,对搜索引擎、知识图谱、富结果、下游实体识别都有意义。
但文章、观点、经验、案例、判断,就不是这么回事了。尤其是 AI 搜索要引用一篇内容的时候,它不是只在找“这段话格式是否规整”。它更可能在判断这篇内容能不能回答问题,来源是否可信,语义是否完整,和其他来源是否能互相印证,有没有足够清楚的上下文,有没有被别的地方引用或讨论。
这就解释了为什么很多“写给 AI 看”的内容,最后反而不好看,也不好用。它把人味写没了,把上下文删掉了,把判断压成了列表,把真实经验改成了模板,把本来有价值的复杂信息变成了一堆方便复制的段落。你以为这样更适合 AI,但前沿模型未必需要你这么喂。甚至它可能一眼就能看出来,这是一篇为了迎合机器而生产的低密度内容。
说到底,AI 搜索不是一个只会读表格的小爬虫。它背后连接的是搜索索引、语义理解、实体关系、网页质量、引用网络和用户意图。你给它一个漂亮但空的 Schema,它不会突然觉得你变权威了。这也是这项研究对 GEO 最大的提醒:GEO 不应该被理解成“给机器贴标签”,它更应该被理解成让你的内容、产品、品牌和证据,在 AI 可以检索、理解、验证和引用的系统里,变得更可信。
Schema 仍然有价值,只是别把它当成 AI 引用开关
这里一定要讲清楚,否则文章很容易走到另一个极端。Schema 没有被证明能显著提升 AI 引用,不等于 Schema 没用了。这两个结论差得很远。
Schema 结构化数据仍然有很多现实价值。它可以帮助搜索引擎更清楚地理解页面类型,比如 Article、Product、Organization、Breadcrumb、FAQ、HowTo。它可以支持某些传统搜索里的富结果展示。它可能参与实体识别、知识图谱、语音助手、垂直搜索和下游数据处理。对于电商站、SaaS 官网、本地商家、内容站、产品页来说,Schema 依然是技术 SEO 里应该认真做的一部分。
但它应该被放回它原本的位置。它是辅助搜索系统理解页面的结构化标记,不是让 AI 搜索突然引用你的万能钥匙。尤其不要把它包装成“GEO 核心秘籍”。这句话可能会让一些人不舒服,但确实该讲。
现在很多 GEO 服务和课程,喜欢把一堆本来属于基础 SEO、内容策略和技术规范的东西,重新包装成一个新概念。Schema、FAQ、llms.txt、robots、sitemap、实体词、问答格式,全都塞进一个“AI 搜索优化清单”里。这些东西有没有用?有些当然有用。但如果不讲优先级,不讲证据强弱,不讲适用场景,不讲效果边界,只是告诉你“做了就能提升 AI 引荐”,那就开始危险了。因为它会让团队把有限的精力,花在最容易执行、但未必最有增量的地方。
真正影响 AI 引用的,可能还是那些更笨、更慢的东西
如果 Schema 不是那个神奇开关,那我们到底该做什么?答案可能没那么性感。
第一,内容本身要有可引用价值。不是泛泛而谈,不是把公开资料重新整理一遍,不是把十篇文章揉成一篇更长的文章,而是要有清楚的定义、判断、数据、案例、对比、操作经验和边界条件。AI 为什么要引用你?因为你提供了一个它在别处不容易找到,或者比别处更清楚、更可信的答案。
第二,页面里的关键信息要对人可见。不要把真正重要的信息只藏在 JSON-LD 里。产品能力、价格范围、适用场景、作者背景、公司信息、案例结果、更新时间,这些东西最好在正文里也清楚出现。searchVIU 做过一个相关实验,测试 ChatGPT、Claude、Perplexity、Gemini 和 Google AI Mode 在实时抓取页面时,会不会使用隐藏的 JSON-LD、Microdata、RDFa。结果显示,它们主要提取可见 HTML 内容,隐藏结构化数据并没有被直接读取。这个实验规模不算大,不能当成最终结论,但它至少提醒我们一件事:对 AI 来说,可见内容仍然非常关键。
第三,站点要有主题权威。你不能今天写一个 AI 搜索,明天写一个宠物玩具,后天写一个减肥茶,然后指望 AI 把你当成某个领域的可靠来源。人会困惑,搜索引擎会困惑,AI 也会困惑。如果你想在某个主题下被引用,就要围绕这个主题持续生产有深度、有互相支撑关系的内容。不是堆关键词,而是形成一个稳定的主题空间。
第四,要有外部信号。品牌提及、自然外链、行业引用、社区讨论、媒体报道、用户评价,这些东西很难伪造,也很难快速补齐。但正因为难,它们才可能成为更强的信任信号。AI 搜索不是只看你自己怎么说自己。它还会看整个网络里有没有别人也在谈你、引用你、验证你。
第五,内容要保持新鲜。AI 搜索引用的是答案,不是档案。一个三年前写得不错、但现在没有更新的页面,在很多快速变化的话题里,很容易被更新、更具体、更有现实信息的页面替代。所以 GEO 不是一次性工程,它更像内容资产的长期维护。这事听起来很土,但很多时候,真正有效的事情就是这么土。
对出海团队和独立站来说,这项研究意味着什么
如果你做的是英文独立站、SaaS 官网、工具站、内容站,或者正在做 AI 搜索可见性,我觉得这项研究至少带来三个现实提醒。
第一个提醒:不要把技术清单当成增长策略。Schema 要做,sitemap 要做,robots 要检查,页面速度要优化,索引状态要看。但这些更像地基。地基不稳肯定不行,可地基打好了,也不代表房子会自动有人住。如果你的内容没有真实信息增量,产品页面没有说清楚解决什么问题,案例没有可信细节,品牌在外部没有任何存在感,只靠技术 SEO 是撑不起来 AI 引用的。
第二个提醒:GEO 的核心不是“讨好 AI”,而是降低 AI 引用你的风险。这个说法可能更准确。AI 引用一个页面,本质上也在承担风险。它把你的内容作为答案来源,如果你的页面含糊、过时、没有出处、没有作者、没有上下文,它凭什么信你?所以我们要做的不是把页面写得更像机器稿,而是把页面写得更像一个可信来源。信息清楚,来源明确,观点有支撑,边界说得明白,更新状态可见。这些东西对人有用,对 AI 也有用。
第三个提醒:不要被新名词带着跑。SEO 时代有很多人卖神奇外链、神奇关键词、神奇站群。GEO 时代,也一定会有人卖神奇 Schema、神奇 prompt、神奇 llms.txt、神奇 AI 引用公式。我不是说这些东西都没价值。我只是说,越是听起来像“开关”的东西,越要小心。真正的增长,很少来自一个开关。尤其是在搜索和内容分发这件事上,更多时候是几十个基础动作长期叠加,最后形成一个系统性的可信度。这个过程不好卖,但它更接近真实世界。
所以,Schema 还要不要做?
要做,但不要神化。
如果你的网站还没有基础 Schema,尤其是产品页、组织页、文章页、面包屑、作者信息、本地业务信息这些,当然应该补。这属于基础技术 SEO。但如果你问的是:“我现在为了提升 AI 搜索引用,要不要优先投入大量资源去给所有页面做复杂 Schema?”我的答案会谨慎很多。
你至少应该先问几个问题。这些页面本身有没有被 AI 引用过?内容有没有明显信息增量?页面里的关键信息是不是对用户可见?有没有作者、来源、更新时间、案例、数据和外部验证?这些页面在传统搜索里有没有基础排名和展示?你有没有对照组,能判断做完 Schema 之后的变化到底来自 Schema,还是来自平台整体波动?
Ahrefs 在原文最后也给了一个很实在的建议:不要只听别人说 Schema 有没有用,最好在自己的网站上做一个小型对照实验。比如挑 5 到 10 个准备新增 JSON-LD 的页面,再挑 5 到 10 个引用水平接近、但暂时不改 Schema 的页面,先记录它们在 AI Overviews、AI Mode、ChatGPT 里的基准引用数据。
然后,在测试页面上新增 Schema,记录准确日期,尽量不要在同一窗口里同时大改正文、内链、标题和页面结构。过 30 天,或者更长一点,再看测试组有没有比对照组涨得更多。
这个方法听起来麻烦,但它比“看一篇文章,然后全站开干”靠谱得多。因为你的网站、你的页面类型、你的行业、你的 AI 引用基础,可能都和 Ahrefs 样本不一样。尤其是出海站、SaaS 站、工具站、电商产品页,最好不要把别人的平均结论直接当成自己的执行命令。
如果这些问题都没有答案,那就别急着把 Schema 当主线。先把内容做厚,把主题做深,把品牌做实,把数据打通,把页面维护起来。然后,Schema 作为辅助结构去补。这个顺序更稳。
最后说回 GEO
我一直觉得,GEO 这个词现在最大的问题,不是它没有价值,而是它太容易被讲玄。一讲 AI 搜索,就好像搜索逻辑彻底变了。一讲 AI 引用,就好像传统 SEO 全部失效了。一讲结构化数据,就好像网页只要给机器重新包装一下,就能被 AI 抬进答案框。
但从这项 Ahrefs 研究看,事情没有那么简单。AI 搜索当然带来了新变化。引用逻辑、答案形态、用户路径、流量分配、品牌曝光,都会变。但它并没有把内容质量、权威信号、品牌可信度、页面维护、外部引用这些老问题抹掉。恰恰相反,它可能把这些老问题放大了。
因为 AI 搜索不是只给用户一个链接。它是在替用户组织答案。一旦它要组织答案,它就更需要判断谁可信,谁具体,谁过时,谁只是看起来结构清楚但其实没有什么信息。
所以,这项研究真正给我们的启发,不是“以后别做 Schema 了”,而是别再把 Schema 当成 GEO 的核心答案。Schema 可以是工具,但内容资产、品牌信任、主题权威和可验证证据,才是更难、更慢、也更值得长期投入的东西。
说人话就是:别只想着把网页写给机器看,先把它写成一个真正值得被引用的来源。这件事不新,也不玄,但它可能才是 AI 搜索时代最不该被忘掉的基本功。
