Digital Strategy Review | 2026
AI 安全审查中:AI 是否可能在意外中伤人? | 果叔AI日报
文 / 果叔 · 阅读时间 / 8 Min

写在前面
过去两年我们聊 AI 安全,主战场往往在“未来会不会失控”“模型会不会对齐”。但这周冒出来一个更刺眼的问题:如果 AI 已经被放进真实世界的高风险决策链路里,那么伤害可能不是未来时,而是现在时。
引爆点来自一场被多方报道的悲剧:伊朗南部米纳卜(Minab)一所小学遭到袭击,大量女学生死亡。随后,Gary Marcus 在文章中引用 Tyler Austin Harper 的推文,提出一个尖锐追问:这类误击,是否可能与 AI 辅助瞄准/决策系统有关?
我先把结论写在前面:事件本身是真实而沉重的,AI 是否参与目前缺乏公开证据。 但这条新闻仍然值得上头版,因为它把 AI 安全讨论推向了一个更“工程化”的方向:当系统可能造成不可逆伤害时,你有没有能力追溯、解释、问责,甚至在事故发生前把风险关在闸门里。
01
今日头版重点新闻
要点速览
01 AI 安全审查中:AI 是否可能在意外中伤人?(新兴)近期伊朗一所小学遭袭造成大量女学生死亡,引发了“高风险场景里 AI 是否已参与致命决策”的公共追问。Gary Marcus 认为两者关联尚未被证实,但这类问题本身意味着 AI 安全讨论正在进入“现实世界伤害与问责”层面:如果 AI 真的在链路里,你能不能证明它做了什么、谁按下了确认、哪些机制本该阻止它。
事实层:我们能确认什么
目前公开信息可以交叉确认的只有两点:
• 悲剧事件确有发生:联合国教科文组织(UNESCO)与多家媒体报道,伊朗南部米纳卜一所女子小学遭轰炸,造成至少 152 名女学生死亡。 可信来源(可交叉):UNESCO 声明、国际媒体报道。
• 事故背景信息仍在发酵:具体责任归属、打击链路、情报来源、操作流程等关键细节并未形成完整公开披露。
争议层:AI 参与的部分为什么要谨慎
Gary Marcus 的原话核心不是“我确认 AI 造成了伤亡”,而是“我们应该开始严肃对待这种可能性,并要求可审计的证据链”。他引用 Tyler Austin Harper 的推文,把问题抛给公众:如果误击来自 AI 辅助瞄准系统,我们是否有能力调查出来?
这句话的杀伤力在于:它把争论焦点从“AI 能不能做”转移到“社会有没有能力追责”。在很多高风险系统里,真正的黑箱不是模型参数,而是整条链路的组织结构和记录机制。
为什么它值得当日头版
因为这是一个“安全议题的换挡提示灯”:
• 以前我们把 AI 安全当成模型问题(幻觉、越狱、对齐)。
• 现在它正在变成系统问题(采集什么数据、谁批准、阈值怎么设、日志有没有、事后能否复盘、法律如何问责)。
当讨论走到这一层,AI 安全就不再是研究员的哲学辩论,而是每一个做高风险自动化系统的人都躲不开的工程责任。
02
头版解读:为什么这件事更重要
如果把“AI 可能参与误击”当成一个假设,我们真正要研究的不是“模型有没有道德”,而是“系统有没有刹车”。
我把它拆成三层,你会更清楚这条新闻的时间价值在哪里。
1) 技术层:AI 在链路里到底扮演什么角色
很多人听到“AI 参与军事决策”,脑子里立刻跳到“全自动杀手机器人”。现实里更常见的是“辅助系统”:
• 目标识别与分类(图像/雷达/多源融合后的目标建议)
• 风险评估与优先级排序(给出置信度、威胁等级、推荐行动)
• 决策界面与提示(把复杂信息压缩成一句话,推着人做选择)
这类系统的问题在于:就算最后是人点的“确认”,AI 依然能在时间压力下改变人的判断。这不是科幻,而是人机交互的老问题:当系统看起来很“专业”,人会更容易把责任外包给它。
2) 组织层:所谓“人类在环”,经常只是免责用语
很多制度文件会强调“保留人类判断”。但真实世界的决策现场,往往是另一套逻辑:
• 时间窗口极短,操作员没有条件做第二套独立验证
• 绩效与激励偏向“快”“准”“少失误”,而不是“慢下来”
• 链路被拆分成多个岗位,责任被稀释到无法追溯
所以“人类在环”不是一个开关,而是一整套工程设计题:你要给人多少时间、多少信息、多少反对权,以及当 AI 不确定时系统如何自动减速。
3) 问责层:没有日志的系统,天然无法治理
这条新闻真正让人不安的点是:如果 AI 确实在链路里,我们能不能查出来?
要查出来,需要一套“可审计的决策证据链”,至少包括:
• 数据侧:当时输入是什么(传感器、情报、标注来源、置信区间)
• 模型侧:用的是哪一版模型、阈值如何、是否触发了异常策略
• 人机侧:界面给了操作员什么提示,操作员做了哪些点击/改写/确认
• 系统侧:谁授权、谁批准、谁拥有最终开火权,审批链路有没有绕过
这里有个很现实的参照:美国国防部在 DoD Directive 3000.09(Autonomy in Weapon Systems)中强调“让指挥官与操作员对武力使用保持适当的人类判断”,并把“降低失败导致非预期交战的概率与后果”写进政策目标。你会发现,文件里谈的几乎都是“系统工程”和“责任链条”,而不是模型参数。 这就是我说的换挡:AI 安全正在被迫进入可审计、可追责、可复盘的工程范式。
同样的方向也出现在国际人道与武器治理讨论中。ICRC 长期倡导对自主武器系统建立规则与限制,核心也是一句话:越是可能造成不可逆伤害的系统,越需要清晰的人类控制与问责机制。
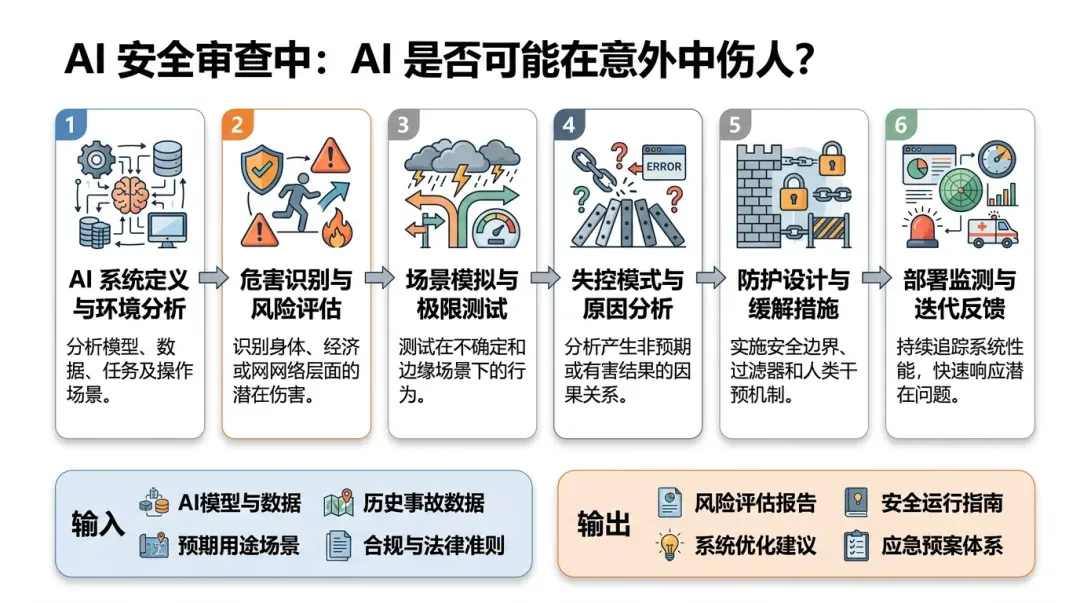
流程图用于解释方法论执行路径。
03
果叔观点
我更关心的不是“这次事件是不是 AI 导致”,而是下一次类似事件出现时,我们有没有能力把问题说清楚。
如果你在做任何高风险自动化系统,不管是国防、医疗、金融还是工业控制,我建议你立刻做三件事。它们看起来“慢”,但本质是给系统装刹车。
1) 把“事故可调查性”当成第一等需求
很多团队的日志体系是为了排查 bug、优化性能。但高风险系统的日志必须满足另一种目标:事故发生后,外部审计能复盘事实。
你至少要做到:
• 关键输入可追溯(来源、时间、完整性校验)
• 模型版本与参数可追溯(训练数据版本、阈值、策略)
• 人机交互可追溯(提示、操作、确认、撤销)
没有这些,你就别谈“负责任的 AI”,因为你连责任发生在哪里都无法定位。
2) 给“不确定”设计明确的减速机制
AI 最大的风险不是“它永远错”,而是“它偶尔很对,让人习惯相信它”。
工程上更有效的做法是:当系统不确定时,强制触发减速与升级:
• 置信度低或证据冲突时,必须二次确认(双人审批、双源验证)
• 触发异常时,系统默认进入更保守的策略,而不是继续推进
• 给操作员真实的反对权:反对会被记录且可追责,支持也一样
3) 把“人类在环”写成可执行的制度,而不是一句口号
真正可执行的“人类在环”至少回答四个问题:
• 谁是最终责任人(不是岗位名称,而是具体职责)
• 人在什么节点介入(介入点越后,越接近走流程)
• 人有多大权力否决(能否真正阻止系统推进)
• 事后怎么复盘与追责(流程是否独立、是否可公开)
如果你的系统无法回答这四个问题,那么它的“安全承诺”大概率只是公关文案。
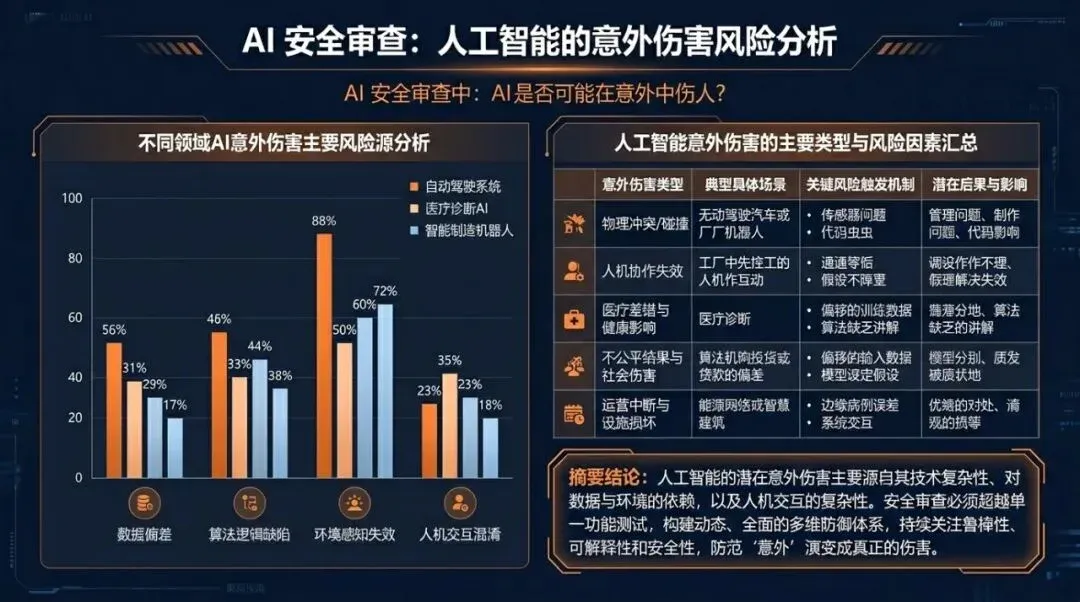
用数据图解释关键对比和结论。
04
其他重点新闻速览
1) “专家新手”与“独行侠”在 LLM 早期会更常见
Jeff Geerling 提出一个很现实的观察:LLM 让更多人能“做成东西”,但也让缺乏经验的决策被放大,尤其是在缺少审查机制的个人项目与小团队里。 值得关注点:AI 工具会让技术治理从“代码质量”扩展到“决策质量”,组织需要新的审查与防线设计。
来源:https://www.jeffgeerling.com/blog/2026/expert-beginners-and-lone-wolves-dominate-llm-era/
2) Claude 提供“导入记忆”能力,AI 记忆开始可迁移
Simon Willison 记录了 claude.com/import-memory:用户可以导出过去对话中系统存储的“记忆/上下文”,并迁移到其他服务。 值得关注点:这会把“记忆”从黑箱能力变成产品能力,接下来会出现格式标准、隐私合规与跨平台迁移的新竞争。
来源:https://simonwillison.net/2026/Mar/1/claude-import-memory/
3) Antirez 发布面向 LLM/代理的 Redis 使用文档
Redis 作者 Antirez 上线了专门面向 LLM 与 coding agent 的 Redis patterns 文档,强调生产环境模式与可复用实现。 值得关注点:AI 应用的“记忆/会话/缓存”会越来越像基础设施问题,Redis 这种成熟组件可能成为默认底座。
来源:http://antirez.com/news/161
4) DHS 数据泄露事件引发对敏感数据保护的再讨论
Micah Lee 的文章围绕 DHS 相关入侵事件展开,讨论了攻击动机与系统暴露面。 值得关注点:当 AI 产品大量接入企业数据,安全边界会被提示词、插件、自动化工作流重新切割,传统安全体系需要补上“AI 入口”的治理。
来源:https://micahflee.com/why-hack-the-dhs-i-can-think-of-a-couple-pretti-good-reasons/
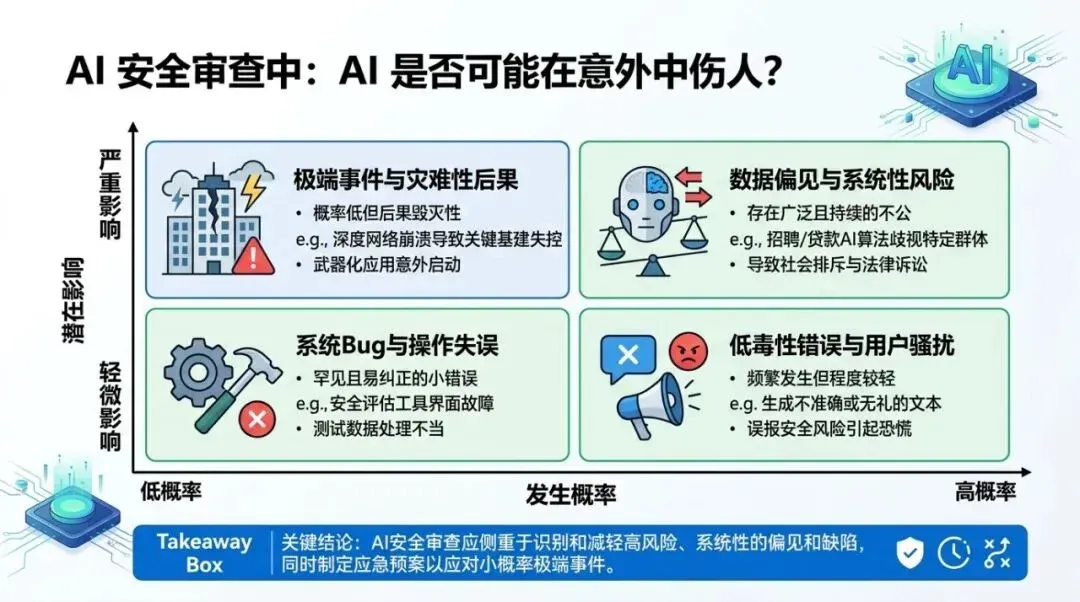
矩阵图用于说明适用边界和策略选择。
05
趋势与机会
1) AI 安全会从“模型对齐”走向“系统可审计”
未来一段时间,最有价值的安全能力可能不是更强的拒答,而是更强的证据链:输入、输出、阈值、版本、责任人,一切可复盘。做不到这一点的系统,将很难在高风险场景里获得长期信任。
2) “AI 事故响应”会变成新的工程岗位与产品形态
就像云原生催生了 SRE,AI 大规模进入业务后,也会催生 AI Incident Response:监控提示词风险、识别异常输出、追踪数据血缘、复盘决策链路。对应的工具链会是一个新市场。
3) 规则会比技术更快落地,先准备的人会少走弯路
当舆论开始问“AI 是否已造成现实伤害”,监管与行业规则会加速。提前把日志、审计、复盘、授权链路做扎实的团队,未来面对合规与合作门槛会轻很多。

