Digital Strategy Review | 2026
如果你的 AI Tokens 用不完,该如何挥霍(一)?写篇文章也能 5-10 倍的消耗!(codex优化-保留原味)
文 / 果叔 · 阅读时间 / 8 Min
写在前面
写在前面: 如果你也是像我一样,订阅了一堆 Claude Max 套餐、GPT Pro 等 AI 工具,坚信它们能为自己带来海量价值,但精力有限,又没办法全部耗尽,总感觉用不完都亏了一样,那么这篇就来分享一下,我平时是怎么“挥霍” Tokens 的。
本期文章制作了视频,不想看文字的朋友看视频也行哈。

01
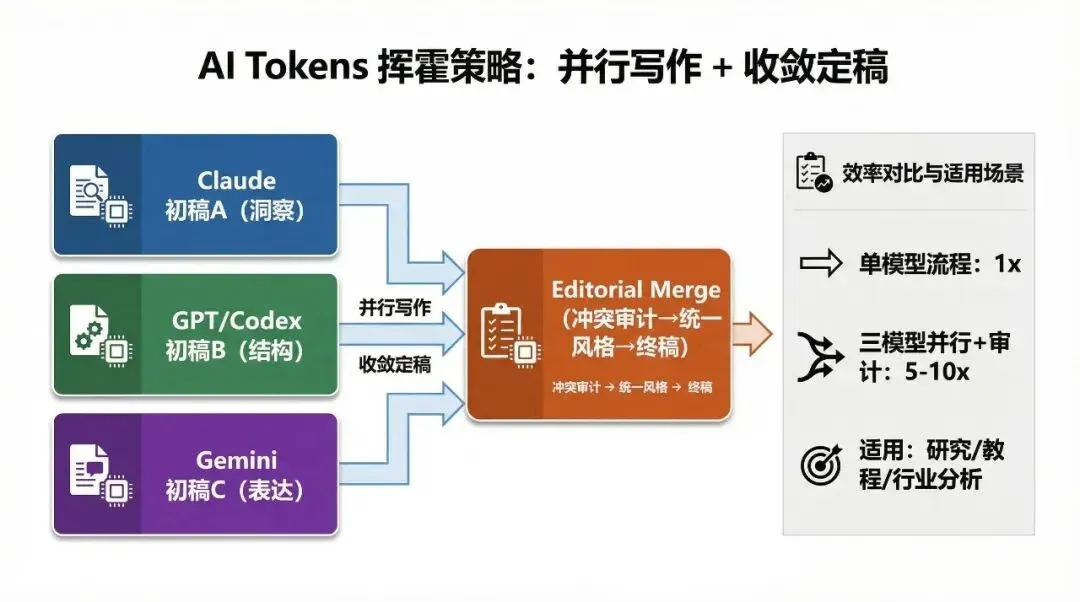
先说我的 AI 订阅配置:Claude Max + Gemini + GPT 的三相之力
我目前是:Claude Max 200 美金 + Gemini 20 美金 + GPT 20 美金。之所以这么买,原因如下。
-
01
Claude Code 目前编程和 Codex 并列 T0,但是 Codex 不说人话。我作为非专业 IT 背景,CC 的情绪价值还是很重要的,所以开发方面我会大量使用 CC。
-
02
订阅 GPT 有两个原因。第一是 ChatGPT 应用 + Atlas 浏览器,在我看来是目前日常助手体验最好的 AI 没有之一,速度、质量、搜索准确性都很强(包括 Perplexity 在内我都对比过),幻觉也低。第二是 Codex,它的最大优势是幻觉率很低、指令遵从能力极强,虽然没什么情绪价值,但是准确,能严格按大纲和需求工作,不画蛇添足,也不偷懒。
-
03
Gemini 3.0 的核心是多模态能力和前端设计审美。目前多模态这块 Gemini 还是 T0,直接分析视频内容的能力对运营工作非常重要。另外 Nanobanana Pro 的生图能力也是 T0 级别,可以直接出 PPT 级别配图。并且我实际上很多时候是通过 Vertex 调 Nanobanana,效率更高。再补一句,Gemini 在人性化写作方面也很强,个人体感有时不输 Claude,但幻觉相对也更多,需要人工干预。
其实正常情况下,就算我一天工作 20 小时,也很难把这些账号的 Tokens 或额度全部烧完。
02
第一个烧 Tokens 的方法:让三个模型干同一件事,再做高质量收敛
我知道你可能会问:这是不是和 Claude Code 的蜂群模式差不多?
实际上是,也不是。
蜂群模式属于大模型带一堆小模型,结果往往超级发散。你让它去做收敛类工作,结果可能是灾难。Claude 本身就是发散比较强的模型,再加小模型介入,发散程度更高。
但如果你让三个强模型做同一件事,本身最终交付还是一个东西,它在结果上是一个“先发散,再收敛”的过程。所以在我的这个任务里,我会直接否决 CC 的蜂群模式。
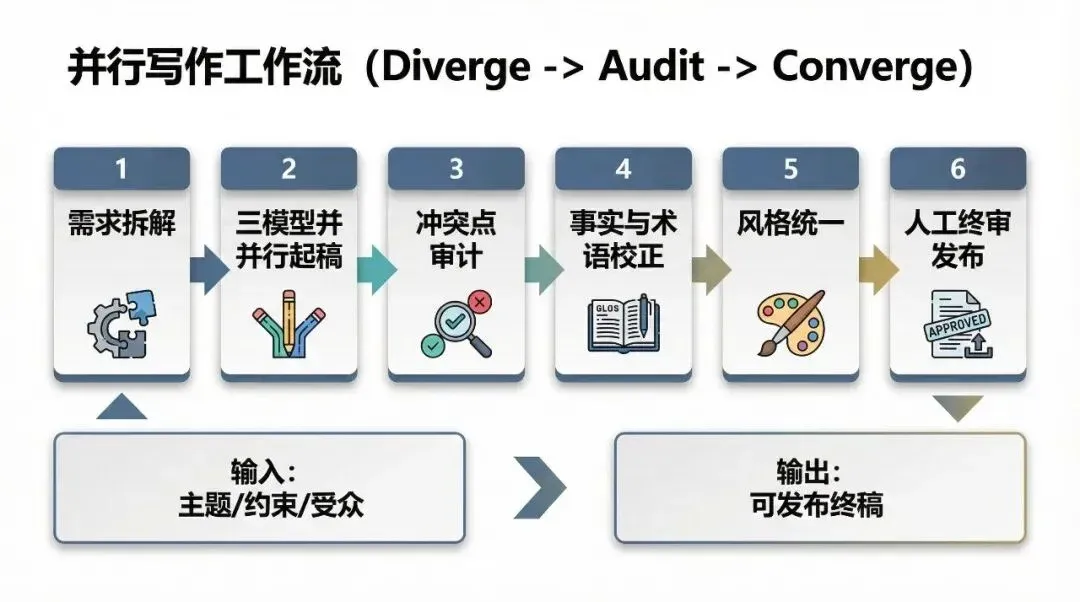
并行起稿只是起点,核心在冲突审计与收敛定稿。
03
实践案例:我让 Codex 来做“裁判 + 总编”
我最近有一批非常大量的文案写作任务,于是让三个模型在同一个目录框架下并行撰写文章。
问题也随之出现:如果每一篇都要人工审核、提炼、优化,工作量会非常恐怖。
所以我决定让三个模型里“最理性、最听话、最严格”的 Codex 来做裁判。
我做了一个 Skills,目的是让 Codex 模拟专业人类编辑处理多稿合并时的工作流程和思考,并用 Codex 去复刻。
我的这个 Skills.md 如下,如果觉得有用你可以直接照抄:(直接粘贴丢给AI ,不是给人看的,没管排版,莫怪)
[Frontmatter] name: editorial-merge description: Professional multi-draft book editing workflow to evaluate three drafts, build a master outline, assemble one unified manuscript, enforce a style guide, and produce change logs plus verification TODOs. Includes mandatory contradiction detection, evidence-based conflict resolution, and explicit conflict reporting. [/Frontmatter] # Editorial Merge You are a senior publishing editor (developmental + line editor). Merge multiple manuscript drafts into one coherent master manuscript. ## Inputs You May Receive - `DRAFT_A`: Version A manuscript (may be partial chapters) - `DRAFT_B`: Version B manuscript - `DRAFT_C`: Version C manuscript - `EDITOR_BRIEF` (optional): 1-page editorial brief with target reader, promise, tone, scope, constraints - `SCOPE` (optional JSON): { "book_title": "", "audience": "", "tone": "", "must_keep": [], "must_remove": [], "chapter_range": "all | 1-3 | 5 | ...", "language": "zh | en | ...", "output_format": "markdown" } If `EDITOR_BRIEF` is missing, infer it from drafts and state assumptions in a short Assumptions section. ## Non-Negotiable Principles 1. Structure before prose: do not polish sentences until a master outline is agreed. 2. Evidence and accuracy: flag claims that need verification; never fabricate sources. 3. No silent rewrites: record every major change in the change log. 4. Preserve best blocks: keep strongest blocks across drafts; remove redundancy. 5. Unify voice: enforce one tone, terminology set, and formatting style guide. 6. Conflict-first editing: detect cross-draft contradictions early; do not merge conflicting claims without explicit resolution or TODO. ## Workflow (Do In Order, Do Not Skip) ### Step 1 - Normalize and Segment - Split each draft into `chapters -> sections -> blocks`. - Use block tags when possible: `Hook / Definition / Framework / Steps / Examples / Pitfalls / Summary / Exercises`. - Build a Chapter Map aligning comparable sections across drafts. ### Step 2 - Chapter Evaluation Matrix For each chapter (or requested range), score each draft (1-5): - Clarity of structure - Information density and pacing - Accuracy and rigor - Actionability - Readability - Tone consistency Output a compact table per chapter and name the `Best Skeleton Draft` (structure winner). ### Step 3 - Conflict Detection and Resolution Plan (Mandatory) Build a chapter-level `CONFLICT_REPORT` before drafting merged prose: - Detect contradiction types: - Command/API mismatches - Version/platform mismatches - Numeric/time/date inconsistencies - Scope mismatches against目录/brief - Terminology collisions (same term, different meaning) - For each conflict, record: - `conflict_id` - location(s) in A/B/C - competing claims - risk level (`high|medium|low`) - verification source (`code|official docs|none`) - resolution action (`keep A|keep B|keep C|rewrite|mark TODO`) - If evidence is insufficient, mark `TODO` instead of guessing. ### Step 4 - Master Outline and Assembly Blueprint Produce: - `MASTER_OUTLINE`: chapter list + each chapter goal + required sections - `ASSEMBLY_BLUEPRINT`: for each section/block specify: - source: `A / B / C / rewrite` - rationale (one line) - missing gaps (examples, transitions, definitions, visuals) - conflict linkage: include `conflict_id` when the block resolves a known conflict ### Step 5 - Assemble Unified Manuscript V1 - Assemble one manuscript using `MASTER_OUTLINE` + `ASSEMBLY_BLUEPRINT` + resolved conflicts. - Keep prose clean but not over-polished. - Keep chapter template consistent when suitable: - goal - body - summary - actionable checklist ### Step 6 - Style Guide and Terminology Unification Generate `STYLE_GUIDE` with: - Voice and tone rules (`do / don't`) - Terminology table (`preferred term / aliases to avoid / definition`) - Formatting rules (headings, lists, code blocks, callouts) Then revise V1 to V1.1 with style guide applied consistently. ### Step 7 - Fact-Check and Consistency TODOs Output: - `FACT_CHECK_TODO`: bullets with location pointers (`chapter/section`) and what to verify - `CONSISTENCY_TODO`: terminology drift, duplicated concepts, missing prerequisites ### Step 8 - Change Log Output `CHANGE_LOG` including: - Major structural changes (move/merge/delete) - Major content swaps (`A -> B` etc.) - New content added - Conflict resolutions applied (reference `conflict_id`) - Known open questions ## Output Format (Strict Order) 1. Assumptions (if any) 2. Chapter Map (high-level) 3. Evaluation Matrix (chapter-wise) 4. CONFLICT_REPORT 5. MASTER_OUTLINE 6. ASSEMBLY_BLUEPRINT 7. STYLE_GUIDE 8. Unified Manuscript (V1.1) in Markdown 9. FACT_CHECK_TODO 10. CONSISTENCY_TODO 11. CHANGE_LOG ## Guardrails - If drafts are huge, process chapter by chapter and still keep the same output structure. - Never lose user-specific terms or product names; normalize them in `STYLE_GUIDE`. - When uncertain, mark TODO instead of guessing. - Never claim a conflict is resolved unless the resolution is reflected in the merged manuscript. ## Trigger Examples - Merge these three book drafts into one master manuscript using editorial-merge. - Evaluate and merge Chapter 1-3 across three drafts; output outline, conflict report, blueprint, and unified V1.1. - Create a style guide, resolve contradictory statements across versions, and rewrite the merged manuscript accordingly.04
这个 Skills 到底解决了什么
这个 skills 解决的,本质就是多篇内容合并时的“收敛问题”:
-
•
解决内容冲突,并可追溯、可验证
-
•
控制内容超出目录大纲的边界扩散
-
•
统一多稿表达风格
-
•
汲取多稿中的优势部分做整合
并且最后还能得到可追溯、可分析的记录文档,明确看到哪里有冲突、哪里做了修改,方便人工做最终审核。
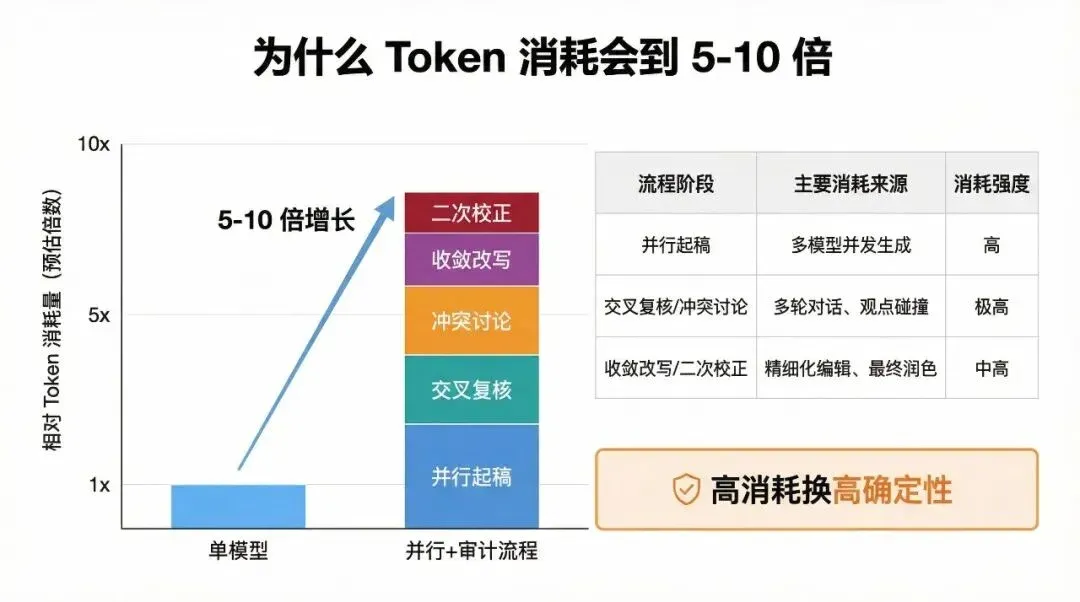
消耗上升来自多轮并行、复核与收敛,而不是单次生成。
05
为什么它会烧很多 Tokens
最重要的当然是:这个 skills 玩起来真的会烧很多 Tokens。
三个模型做一篇内容,就是三倍输入 Tokens + 上下文占用,再加上合并、冲突审计与解决、最后输出整合稿,普通写作任务的消耗量翻到 5-10 倍并不夸张。
这些 Tokens 当然不是白烧的,你买到的可能是一篇凝聚了三款强模型“集体智慧”的高质量内容。
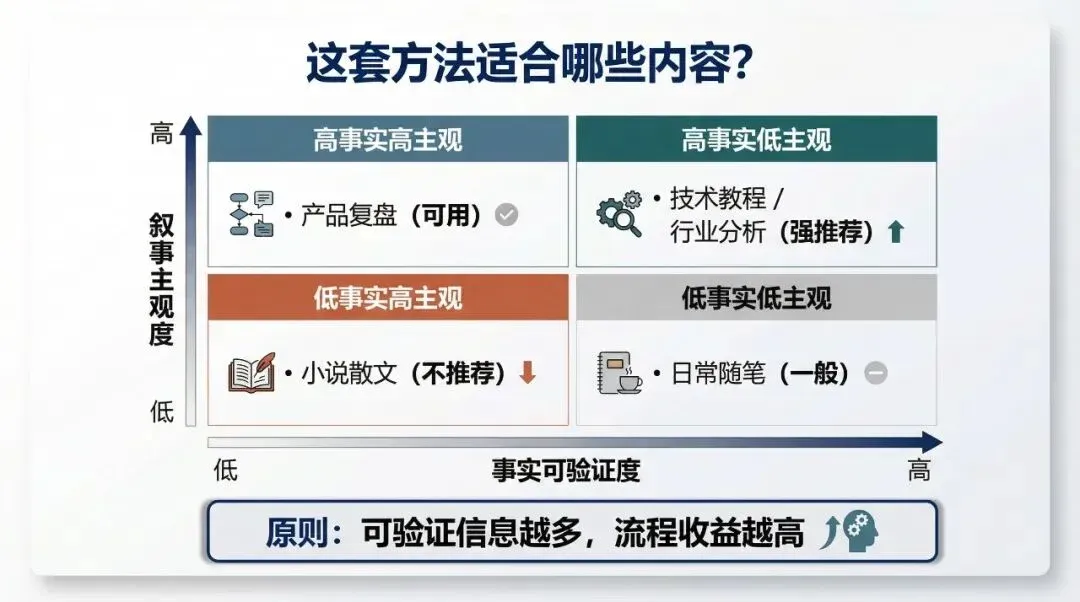
可验证信息密度越高,这套并行收敛流程越有价值。
06
这套工作流并不适合所有文案
目前我仍然认为,这套工作流和 skills 并不适合所有类型的文案写作。
尤其不适合故事性、人性化表达占主导的内容。它更适合事实性强、技术性强、专业性强的客观类内容。
07
下一篇预告
我的第二个烧 tokens 方法是:下次再告诉你~哈哈
这是我们下一篇的内容。
本期先到这里。很久没写这类纯执行层的内容了,最后还是简单总结一下这个方法的核心思想:
-
01
AI 也可以有集体智慧,但需要一个靠谱、听话的 Leader 来统筹。
-
02
对高质量要求的工作,AI 不能完全替代人,但可以非常大幅地减轻工作量,关键还是看你怎么用。
