Digital Strategy Review | 2026
Claude Code 十大亮点解读 03|Fork Subagent 与 Prompt Cache:少见的“成本级创新”
文 / 果叔 · 阅读时间 / 8 Min
写在前面
很多多 Agent 设计只盯着功能能不能跑通,很少有人继续追问:一旦高频 fork,成本会不会先把系统拖垮。这一篇想讲清楚的,就是 Claude Code 如何把 delegation 做成一条能长期承受的工程路径。
01
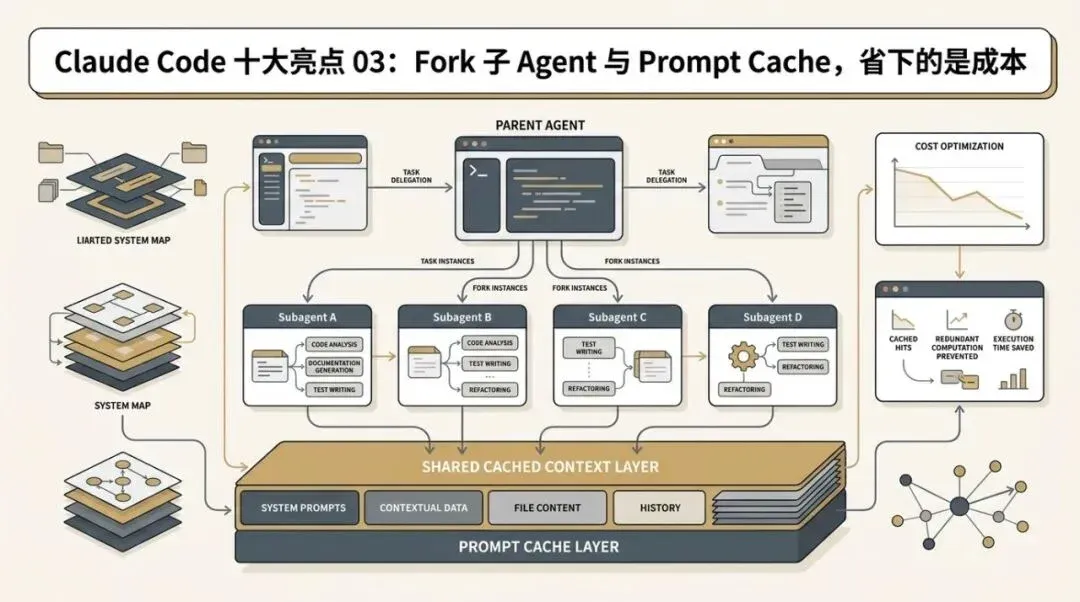
Fork Subagent 与 Prompt Cache:这是少见的“成本级创新”
很多团队在做多 Agent 时,关注点往往停留在:
• 能不能 fork
• 能不能继承上下文
• 能不能后台跑
Claude Code 走得更远。 它不仅考虑 fork 子 Agent 能不能工作,还认真考虑:fork 之后的 token 成本会不会炸。
这就是 src/tools/AgentTool/forkSubagent.ts 最精彩的地方。
02
一、普通的 fork 做法为什么不够
最朴素的 fork 实现一般是:
01 复制父上下文
02 给子 Agent 补一句任务说明
03 发出新的模型请求
这在功能上当然能成立,但会有一个很现实的问题:
每个 fork child 都会带着一大段几乎相同的 prompt 前缀,重复烧 token。
如果系统经常 fork,多子 Agent 并发时成本会迅速上升。
这类问题在 demo 阶段不明显,但一旦进入高频真实使用,很快就会成为平台级负担。
Claude Code 显然注意到了这一点。
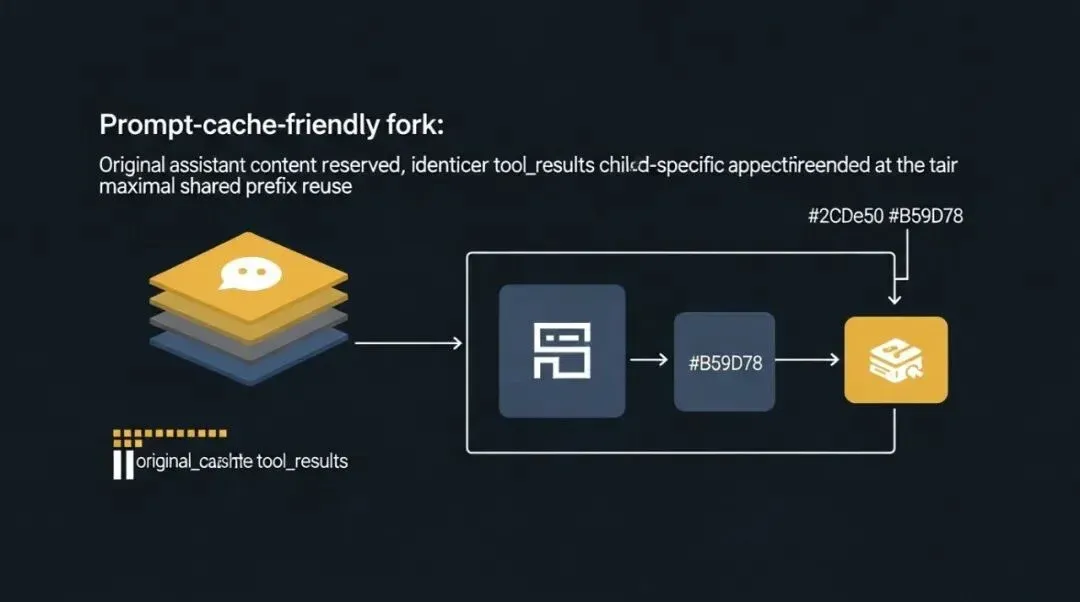
Claude Code 真正厉害的地方,是把 delegation 设计成了缓存友好的输入构造。
03
二、Claude Code 的目标不是“能 fork”,而是“高复用地 fork”
forkSubagent.ts 里最关键的设计目标可以概括为一句话:
让 fork child 的请求前缀尽量字节级一致,从而最大化 prompt cache 命中。
这是个非常高级的目标。 它说明作者不只是站在产品功能层看 fork,而是在站在推理基础设施成本层看 fork。
04
三、它具体怎么做
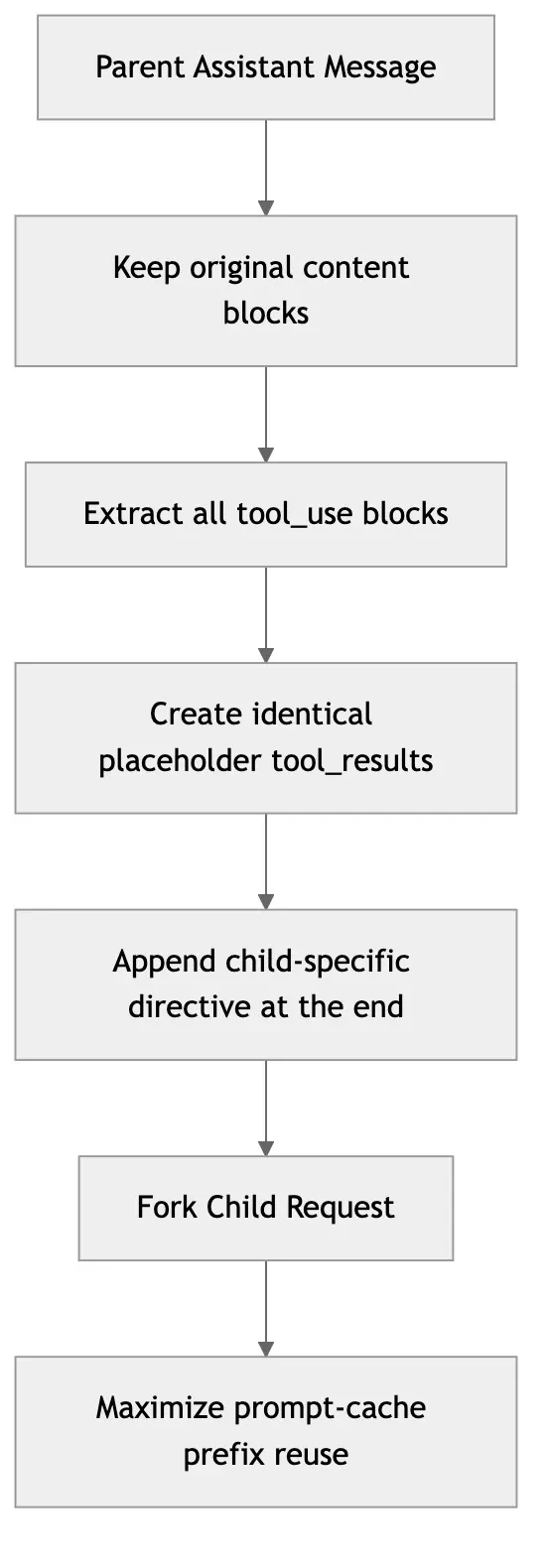
1. 不重建父上下文,而是尽量复用原始 assistant message
Fork child 会保留父 assistant message 的完整内容,包括:
• thinking
• text
• tool_use blocks
这意味着系统尽量不去“重新组织”已有上下文,而是复用已存在的结构。
2. 给所有 tool_use 生成统一 placeholder tool_result
这是整个设计里最关键的一笔。
它不是给每个 fork child 生成不同的 tool_result,而是使用统一 placeholder,比如“Fork started — processing in background”。
这样做的作用是:
• 所有子 Agent 在大段前缀上保持一致
• 真正变化的内容尽量被压到最后
3. 把真正变化的 directive 留在末尾
每个 fork child 的任务当然不同,但 Claude Code 尽量只让差异出现在最后的 directive 文本。
这种“前缀稳定、尾部变化”的构造方式,非常利于 prompt cache 复用。
4. 复用父会话已经渲染好的 system prompt bytes
这点尤其讲究。
系统没有简单地对子 Agent 再调用一遍 getSystemPrompt(),因为那样可能受运行时条件、feature gate、GrowthBook 热状态影响,导致生成字节发生偏差。
Claude Code 反而会尽量线程化传递父会话已经渲染好的 prompt bytes。
这是很少见的严谨程度。
05
四、为什么这件事这么重要
1. 它让多 Agent 更可规模化
很多系统的多 Agent 在能力上可用,但在成本上不可持续。 尤其当每个子 Agent 都背着一大段接近重复的上下文时,成本会直线上升。
Claude Code 的 fork 设计,等于是在多 Agent 上做了“批量推理优化”。
2. 它让 fork 成为默认可用策略而不是昂贵特权
如果 fork 很贵,系统就会倾向于减少 delegation。 如果 fork 可以共享大量 prompt cache,那么运行时就更敢把 delegation 当成常规武器。
3. 它体现了工程团队对 LLM 成本结构的深度理解
这个亮点最能说明 Claude Code 不是“会写 prompt 的产品”,而是一个真正理解推理基础设施的系统。
06
五、这和普通“共享上下文”有什么根本不同
很多人听到这个设计,第一反应可能是:“不就是共享上下文吗?”
不是。
普通共享上下文只是:
• 子 Agent 也能看到父上下文
Claude Code 在做的是:
• 子 Agent 的输入构造方式被精心设计过,以便缓存层尽量把它们看作相同前缀
前者是功能性共享。 后者是成本工程。
07
六、为什么这种设计不容易做
因为你要同时满足很多条件:
• 子 Agent 仍然要正确理解任务
• 父上下文不能被破坏
• 工具调用关系要合法
• 不同 child 之间要足够相似
• 还要避免递归 fork
Claude Code 在 forkSubagent.ts 里甚至还专门加了保护,比如检测 fork child,防止继续递归 fork。
这说明它不是“想到一个聪明技巧”,而是把这条路径做成了长期可用功能。
08
七、一张图看懂这个亮点
09
八、结论
Fork subagent 这项设计最值得称赞的地方,不是它让子 Agent 更聪明,而是它让子 Agent 更“便宜”。
在 Agent 系统真正落地时,这类成本级创新往往比功能级创新更稀缺。 因为前者需要团队同时理解:
• 模型上下文结构
• 提示缓存行为
• 系统提示稳定性
• 多 Agent 调度模式
Claude Code 在这里的答案非常漂亮:
不是只让 Agent 会分身,而是让 Agent 的分身尽量共享大脑前缀。
