Digital Strategy Review | 2026
Harness Engineering 深度解析:Claude Code 把哪些工程护栏真正做进了运行时
文 / 果叔 · 阅读时间 / 8 Min
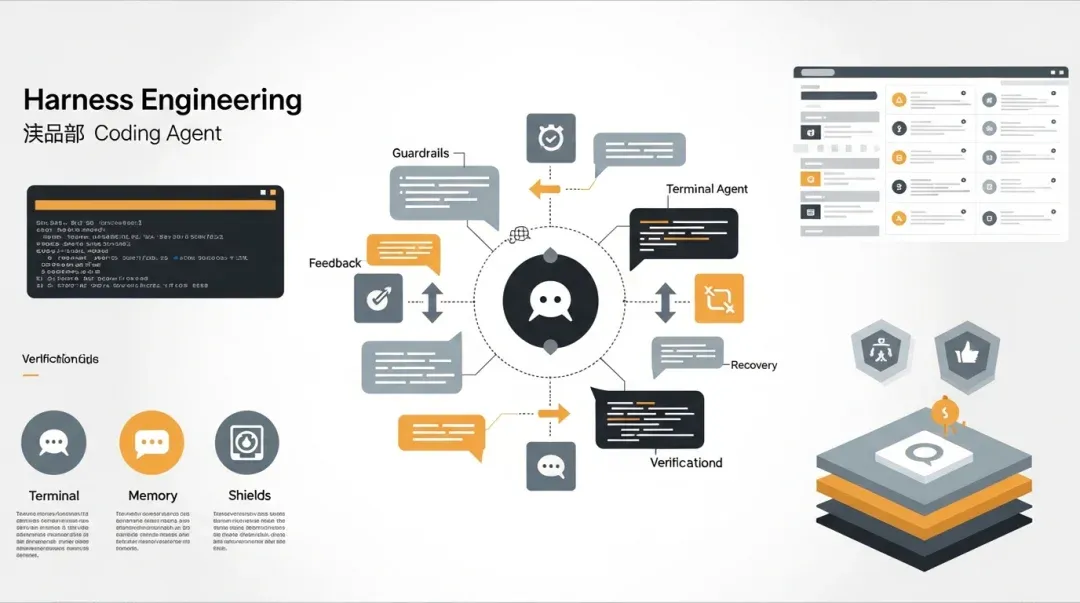
写在前面
这篇文章我更想从一个工程问题切进去,而不是从概念定义切进去:当大家都在讲 Harness Engineering 时,Claude Code 这套已经公开、而且明显经历过真实复杂任务打磨的系统,到底把哪些“护栏”做成了可运行的东西。
2026 年初,Harness Engineering 这个词突然成为 AI 工程圈的高频词,并不是因为大家发明了一个全新的技术类别,而是因为越来越多团队终于意识到一件事:
当模型已经足够强,真正决定 AI Agent 是否能长期可靠工作的,不再是模型会不会写代码,而是围绕模型搭出来的约束系统、反馈系统、执行系统与恢复系统。
换句话说,问题不再是“LLM 能不能做”,而是“系统怎么让 LLM 持续、可控、可恢复、低熵地做”。
你给出的那篇文章已经把 Harness Engineering 的行业脉络讲得很完整了: Mitchell Hashimoto 负责命名,OpenAI 给出 agent-first world 的工程报告,Anthropic 用长时间运行 Agent 与 C 编译器项目补充了大量第一手经验,Martin Fowler 把这些实践进一步抽象成可讨论的工程概念。
但如果我们把视角从“行业共识”切回“具体系统”,就会出现一个更有意思的问题:
Claude Code 作为一个真实存在、源码开放、而且明显已经走到多 Agent / 长任务 / 强工具调用阶段的系统,它到底在 Harness Engineering 上做了哪些实际优化?
这篇文章就只回答这个问题。
我不会重复定义 Harness Engineering 本身,而是把你文中提到的关键框架逐项映射到 Claude Code src 的实际实现上,重点回答:
为了让这篇文章更像工程分析而不是概念散文,我会反复落到源码上。主要参考的实现面包括:
我的核心结论先放前面:
Claude Code 并没有把 “Harness Engineering” 当作一个显式口号写在代码里,但它在实际上已经实现了一套相当成熟的 Harness Runtime。 它不是只靠 Prompt Engineering 在驱动 Agent,而是把上下文治理、角色分工、任务系统、权限中心、隔离执行、恢复逻辑、工具编排、通知与 UI 控制面,全部织成了一张运行时安全网。
如果一定要给一句更聚焦的判断,我会这样概括:
Claude Code 最强的地方,不是“它有很多 Agent”,而是“它已经把 Agent 放进了一个可治理、可观察、可恢复、可扩展的工程 Harness 里”。
01
一、先给一句判断:Claude Code 属于哪一类 Harness 风格
这一节先给一个总判断,方便后面读源码时不至于只见树木不见森林。如果把你文中提到的几类团队风格粗略分一下:
• Hashimoto / Ghostty:失败驱动的文档化护栏
• OpenAI:架构约束、工具与反馈回路的系统化工程
• Anthropic:跨会话连续性、持久化进度、长任务自稳态
• Stripe:强工具集成、隔离环境、并行自治到 PR
• Huntley / Ralph Wiggum Loop:强 backpressure + 快速自修复
那么 Claude Code 的气质最接近的是:
OpenAI 的“Agent Runtime + 机械化护栏” 加上 Anthropic 的“长任务连续性与跨会话恢复” 再加一点 Hashimoto 的“把历史失败折叠回系统约束”。
它和 Stripe 那种“企业级无人值守并行 PR 工厂”还不完全一样,因为 Claude Code 仍然非常强调前台 REPL 控制面、用户审批、任务可见性与交互式控制。 它也不完全像 Hashimoto 的 AGENTS.md-first,因为 Claude Code 明显不满足于文档反馈,而是把很多规则直接做进了 runtime。
所以更准确的说法应该是:
Claude Code 不是纯文档驱动 Harness,也不是纯 CI 驱动 Harness,它是一套运行时中心的 Harness。
这个判断非常关键。因为后面你会看到,它的很多优化并不是“多写点说明文档”,而是把规则内化成:
• 工具暴露边界
• Task 生命周期
• Agent 角色规范
• query loop 的自动 compact
• permission gate
• worktree / remote / teammate 执行后端
• REPL 内的统一控制面
这说明它已经把 Harness 从“说明层”推进到“系统层”了。
02
二、Harness Engineering 的第一共识:瓶颈在基础设施,不在模型智能
这是你那篇文章里最核心的行业共识之一。 Claude Code 的源码结构,本身就在强烈支持这个判断。
2.1 如果瓶颈在模型,代码库不会长成现在这样
如果一个团队真的相信“模型足够聪明,剩下都不是问题”,那它的产品代码通常会有这些特征:
• 入口很薄
• 工具注册很随意
• Agent 只是 prompt 模板
• 缺少复杂任务状态
• 没有完整恢复机制
• 没有成体系的 permission / task / view state
Claude Code 完全不是这样。
相反,它在这些地方投入了大量结构化工程工作:
• query.ts 的长回合主循环
• toolOrchestration.ts 的语义并发调度
• LocalAgentTask / RemoteAgentTask / InProcessTeammateTask
• AgentTool 的统一 delegation 入口与多后端路由
• AppState 对任务、权限、MCP、plugin、teammate、remote viewer 的统一建模
• REPL.tsx 作为统一控制面
这类投入说明作者非常清楚:
真正的难题,不是让模型“多说一句正确的话”,而是让系统在复杂执行中仍然保持稳定、可控、可恢复。
2.2 Claude Code 的工具系统本身就是一个反证
src/tools.ts 展示出一个非常重要的工程态度:
• 工具不是“随便暴露给模型的函数”
• 工具是动态裁剪的能力面
• 工具既受 feature gate,也受 permission context 与模式约束
这正说明 Claude Code 团队并不把“模型会不会选对工具”当成唯一问题。 他们更关心的是:
• 当前会话到底该暴露什么
• 角色不同是否该看到不同工具
• 运行模式不同是否要切换能力面
这就是典型的基础设施优先思维。
2.3 query loop 的复杂度也说明了这一点
query.ts 有大量与“非智能部分”相关的复杂处理:
• microcompact
• autocompact
• reactive compact
• max output tokens recovery
• stop hooks
• task budget
• synthetic tool_result
• tool result budget
这些东西都不是为了让模型“更聪明”,而是为了让模型在真实运行中“更不容易失控”。
这非常符合 Harness Engineering 的第一原则:
先承认模型会在系统边界上犯错,再围绕这些错误设计护栏与恢复机制。
因此,如果要用一句话对应行业共识,我会说:
Claude Code 的整套架构,就是“基础设施才是瓶颈”的源代码级证据。
03
三、第一大支柱:上下文架构,Claude Code 已经走得很深
你文章里把 Context Architecture 放在四大支柱的第一位,这是完全正确的。 Claude Code 在这件事上并不是停留在“支持上下文注入”,而是已经做到了分层、裁剪、压缩、角色化、动态装配。
3.1 Claude Code 的上下文不是一个大 prompt,而是组合出来的
在 main.tsx、query.ts、runAgent.ts、各类 Agent definition、memory 和 MCP 机制之间,Claude Code 的上下文来源大致可以拆成这些层:
01 会话级 system prompt
02 user context / system context
03 工具定义与工具面
04 Agent-specific prompt / role constraint
05 memory 注入
06 MCP tools / resources
07 hook 影响与 session state
08 transcript / messages
这意味着 Claude Code 从一开始就没有采用“所有东西堆在一个静态文档里”的做法。
它更像你文中说的三层上下文体系,只不过实现得更偏 runtime:
• Tier 1:常驻上下文 由系统 prompt、会话配置、核心 instructions 构成
• Tier 2:按角色 / 按能力加载 由 Agent definition、skills、mcpServers、memory scope 等构成
• Tier 3:按需查询或运行时出现 由具体文件读取、grep、MCP resource、历史 transcript、进度文件等构成
3.2 它非常认真地处理“上下文不是越多越好”
这一点和你文中提到的 Horthy “40% Smart Zone / 40% 以上 Dumb Zone”观察高度一致。
Claude Code 的代码虽然没有直接写“40% sweet spot”,但它在多个维度上都体现出同一判断:
• omitClaudeMd:某些只读 Agent 不默认继承庞大的项目指令,改为按需读取
• ToolSearch 与工具裁剪:不是所有会话都暴露全量工具
• compact / microcompact / reactiveCompact:不是等爆炸了才收拾,而是持续治理
• forkSubagent:尽量共享上下文前缀,避免重复堆积大段上下文
• Explore / Plan 这类专用角色:减少无关上下文污染
换句话说,Claude Code 的上下文架构不是“把所有可能有用的信息都送进模型”,而是:
先划边界,再根据当前任务与角色动态拼上下文。
这正是 Harness Engineering 对 Context Architecture 的成熟形态。
3.3 它把“压缩”当作主路径,而不是异常处理
query.ts 的 compact 体系特别值得强调,因为这是 Claude Code 在 Harness 上做得最深的一块之一。
这里至少有四种 related mechanism:
• microcompact
• auto compact
• reactive compact
• snip compact
这套设计的含义非常明确:
01 系统默认任务会变长
02 长任务默认会逼近上下文上限
03 所以上下文治理必须成为主循环内建能力
这和很多系统的区别非常大。 很多系统只在 prompt 太长时报错或粗暴裁剪,而 Claude Code 已经进入了“持续、渐进、有阶段语义的上下文维护”阶段。
3.4 它把上下文治理和角色分工联动起来
Claude Code 不是一边说“上下文要精简”,另一边又给每个 Agent 全量能力。 相反,它通过专门 Agent、专门工具面、专门 memory scope,让角色本身成为上下文治理的一部分。
这点和你文中“Agent Specialization 本身也是 Context Management 策略”的判断高度吻合。
所以如果只看第一大支柱,我的结论是:
Claude Code 已经不是“有上下文工程”,而是把上下文架构做成了 runtime 级能力。
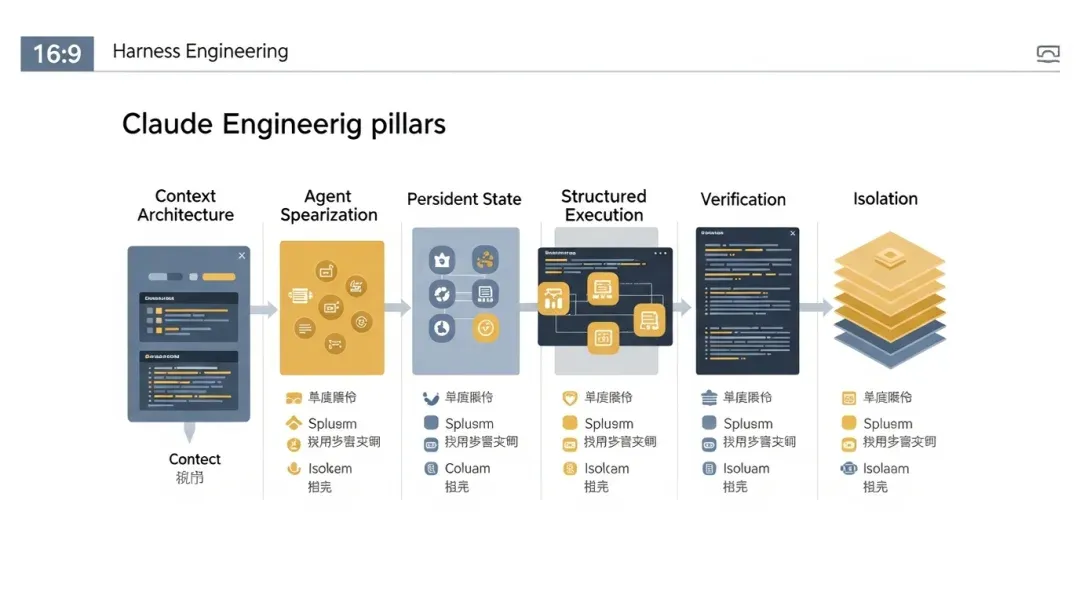
如果把 Claude Code 拆开看,最能说明问题的不是某个单点功能,而是几根工程支柱一起起作用。
04
四、第二大支柱:Agent 专业化,Claude Code 几乎是原生支持
你文章里第二大支柱是 Agent Specialization。 这一点在 Claude Code 里不仅存在,而且是非常核心的系统能力。
4.1 它的 Agent 不是 prompt 角色,而是运行时规格对象
在 loadAgentsDir.ts 里,一个 Agent definition 可声明:
• whenToUse
• tools
• disallowedTools
• skills
• mcpServers
• hooks
• model
• effort
• permissionMode
• background
• memory
• isolation
• maxTurns
这说明 Claude Code 的 Agent 专业化不是“给不同人格写不同系统提示词”,而是:
给不同角色分配不同的执行能力、工具边界、隔离策略与运行预算。
这和你文中的“研究 Agent / 规划 Agent / 执行 Agent / 审查 Agent / 调试 Agent / 清理 Agent”角色范式是高度一致的。
4.2 内置角色已经体现出很典型的专业化范式
最能说明这一点的是三个 built-in agent:
Explore Agent
• 只读
• 快速搜索
• 强调并发读工具
• 不给编辑工具
这几乎就是你文中的“研究 Agent”模板。
Plan Agent
• 只读
• 专注需求拆解、架构分析和 critical files
• 不允许直接执行写入
这就是“规划 Agent”模板。
Verification Agent
• 不允许在项目目录随意修改
• 强制做命令级验证
• 强制给出 PASS / FAIL / PARTIAL verdict
• 强调 adversarial probe
这完全对应“审查/验证 Agent”。
Claude Code 虽然没有完全照搬文章里的角色命名体系,但实际能力分层已经非常接近。
4.3 专业化还体现在工具面裁剪上
这是 Claude Code 和很多“多角色 prompt”系统差别最大的地方。
很多系统虽然给 Agent 起了不同名字,但所有角色都能看到全部工具。 Claude Code 明显不是这样:
• 角色不同,工具不同
• 角色不同,permission mode 也可不同
• 某些角色会刻意去掉编辑能力
• 某些角色默认更适合后台执行
这意味着角色差异已经从“思维风格”进入“操作权限”层。
4.4 专业化在 Claude Code 里还是平台级的,不只是内置角色
因为它支持:
• built-in agent
• user / project / policy / plugin agent
所以这不是写死在代码里的少数角色,而是一个可以扩展的专业化框架。
从 Harness Engineering 角度看,这非常关键。 因为一旦专业化只是内置的、不可扩展的,它就更像产品 feature; 只有当它成为平台能力时,才能真正承载长期演化。
因此在第二大支柱上,我会给 Claude Code 一个很高评价:
它不只是支持 Agent Specialization,而是把专业化 Agent 做成了运行时第一等对象。
05
五、第三大支柱:持久化记忆,Claude Code 走的是“任务/会话状态 + Agent Memory”双路线
你文中第三大支柱是 Persistent Memory,并特别强调:
• 进度要持久化到文件系统
• 会话切换后要能从工件恢复
• 结构化格式比自由文本更稳
Claude Code 在这件事上没有完全照着 Anthropic 的 init.sh + progress.txt + feature_list.json 模式实现,但已经拥有一套自己的、相当成熟的双层方案:
01 任务/会话状态的持久化
02 Agent 角色记忆的持久化
5.1 任务和会话状态持久化非常强
Claude Code 的 Task 体系、session storage、outputFile、transcript subdir、remote metadata、resume 逻辑,说明它对“跨会话连续性”的重视程度很高。
尤其是这些特征非常像你文中 Anthropic 长任务实践的目标:
• 子 Agent 有自己的 transcript
• 任务输出可以落盘
• 任务可以恢复
• 远程任务可以 restore
• viewing agent 可以 bootstrap 既有 transcript
这说明 Claude Code 并不假设“所有重要信息都留在当前上下文窗口里”。
它已经把大量关键状态外置到了:
• task output file
• session storage
• task metadata
• remote agent sidecar metadata
这种“文件系统即连续性载体”的思路,和 Harness Engineering 对持久化工件的要求高度一致。
5.2 Agent Memory 则是另一层:角色级长期记忆
agentMemory.ts 里支持:
• user
• project
• local
这让 Claude Code 的持久化体系不仅能存“任务状态”,还能存“角色经验”。
这两层结合起来非常有意思:
• 任务层负责“这次工作进展到哪”
• memory 层负责“这个角色长期知道什么”
这比单一的 progress.txt 更通用,也更适合 Claude Code 这种长期演化、多角色、多项目的系统。
5.3 它和 Anthropic 路线的相同点与不同点
相同点
• 都非常重视跨会话连续性
• 都承认上下文窗口不能承担全部记忆职责
• 都把文件系统工件看成一等恢复材料
不同点
• Anthropic 的案例更偏“项目推进文件驱动”
• Claude Code 更偏“runtime 状态 + transcript + task metadata 驱动”
从实战角度看,这两种路线没有谁绝对更高明,只是系统形态不同。 Anthropic 更像“长跑 Agent 项目工地管理”; Claude Code 更像“有完整控制面的通用 agent runtime”。
5.4 这里的不足也要诚实指出
如果严格按照你文章中的 Persistent Memory 理想形态来打分,Claude Code 仍有几个明显空白:
• 没有看到像 Anthropic 那样非常强的 feature list / done criteria 文件驱动
• 没有看到默认、统一、强约束的结构化 progress spec 成为主开发流
• 没有明确形成“初始化 Agent -> 编码 Agent”那样两阶段长跑套路
也就是说,Claude Code 在“任务恢复”和“角色记忆”上很强,但在“长期项目进度文件化工作流”上还没有完全体系化。
结论可以概括为:
Claude Code 已经具备持久化记忆的核心基础设施,但更像 runtime-state 持久化,而不是 Anthropic 式项目进度驱动 Harness 的完整形态。
06
六、第四大支柱:结构化执行,Claude Code 几乎是全线贯彻
你文中第四大支柱是 Structured Execution,即:
• 理解
• 规划
• 执行
• 验证
这在 Claude Code 中不是建议,而是已经被拆成了不同运行时角色与工具机制。
6.1 Plan Mode 和 Plan Agent 已经是显式制度化
Claude Code 明显有“先规划再执行”的意识,这体现在多个地方:
• EnterPlanModeTool
• ExitPlanModeTool
• Plan Agent
• 各类团队/teammate 中对 plan mode required 的支持
也就是说,系统并不只是告诉模型“请先想一想”,而是提供了一个显式的模式切换与角色分离机制。
这和你文中 Boris Tane 那句“先批准书面计划,再写代码”的原则非常接近。
6.2 Execute 和 Verify 是被拆开的
Claude Code 没有让主 Agent 一个人包办全部,而是显式有:
• execution-oriented agent
• verification agent
这种角色分离正是 Harness Engineering 里最关键的“把 thinking 和 doing 分开”的实现。
如果不做这件事,系统就很容易陷入:
• 自己写
• 自己判断自己写得不错
• 自己宣布完成
Verification Agent 的存在,本质上就是在对抗这种内生偏差。
6.3 query loop 本身也是结构化执行的底层支持
结构化执行不只是角色层面,还体现在主循环的控制语义里:
• assistant 生成 tool_use
• tool round 执行
• tool result 回灌
• stop hook
• compact boundary
• 继续下一轮
这条路径本质上就是一种结构化执行状态机。 它不是“一次想完再一次说完”,而是:
思考、行动、反馈、压缩、继续 的循环化结构。
6.4 团队态协作更强化了结构化执行
在 in-process teammate / swarm 路线里,这种结构化还更明显:
• leader 可以派发
• worker 有角色与权限边界
• plan mode 可要求先规划
• permission 中心统一
• 结果通过任务与通知回流
这已经超出“结构化 prompt”的范畴,进入“结构化组织流程”了。
所以第四大支柱上,Claude Code 的匹配度也非常高。
07
七、AGENTS.md 与活文档反馈循环:Claude Code 是支持的,但不是只靠这个
你文章里对 AGENTS.md 的描述非常精准: 它本质上是 Agent 的活文档,是历史失败案例的沉淀层。
Claude Code 和这套思路并不冲突,甚至在运行逻辑上是兼容且尊重它的,但它有一个很明显的特点:
它不是把 Harness 主要建立在 AGENTS.md 上,而是把 AGENTS.md 作为更大 runtime 的一部分。
7.1 Claude Code 明显尊重仓库级指令体系
从整个项目的运行方式和你这次任务里对 AGENTS.md 的读取规则就能看出,Claude Code 非常认真对待:
• 仓库级指令文件
• 目录级覆盖规则
• 作用域约束
也就是说,它完全承认“代码仓库内的文档工件是 agent 的事实源之一”。
7.2 但它没有停在“文档约束”
Claude Code 比单纯 AGENTS.md 模式更进一步的地方在于:
• 角色边界被编码进 Agent definition
• 执行边界被编码进 tool permission context
• 运行模式被编码进 Task 和 AgentTool 路由
• 长任务恢复被编码进 transcript / metadata / outputFile
这意味着:
AGENTS.md 在 Claude Code 里是重要的,但不是唯一护栏。 真正的设计思想更像:
文档告诉 Agent 要遵守什么,runtime 负责让这些约束可执行、可验证、可恢复。
这其实是比纯文档反馈循环更成熟的阶段。
7.3 从 Hashimoto 路线看,Claude Code 的优势是什么
Hashimoto 的核心经验是:
• Agent 犯错一次,就把它写进 AGENTS.md / 约束中,避免再犯
Claude Code 的源码给出的更进一步答案是:
• 能靠文档解决的,用文档
• 不能靠文档稳定解决的,升级成 runtime 约束
这也是 Harness Engineering 里最关键的进化方向之一。 因为纯文档约束长期一定会撞上边界:
• 模型看见了不代表一定执行
• 指令太多本身会污染上下文
• 某些约束本来就应该机械化
Claude Code 其实已经把这一步走出来了。
一个成熟的 coding agent 不是只会前进,它得知道何时收缩、验证、恢复,再继续推进。
08
八、架构约束与自动化执行:Claude Code 做到了一部分,但还不是 OpenAI 式“硬架构流水线”
你文中对 OpenAI 那种:
• 自定义 Linter
• 明确依赖方向
• 错误消息直接教 Agent 修
的实践,强调得很对。 问题是:Claude Code 做到了多少?
8.1 它已经具备“机械化执行约束”的思路
最明显体现在:
• 权限系统是机械化的
• 工具边界是机械化的
• plan mode / exit plan mode 是机械化的
• worktree / remote / fork / teammate 的执行边界是机械化的
也就是说,Claude Code 在“运行态约束”这一块已经很强。
8.2 它也有很多 lint / validation / schema 化思维
整个项目里存在大量:
• schema
• validation
• settings 校验
• command / keybinding / hook / agent frontmatter 的解析与校验
这说明团队的基本工程风格是偏“规则先编码”的。
8.3 但它公开暴露出来的部分,还没完全看到 OpenAI 那种“架构依赖方向 Linter 体系”
我目前从 src 中能明确看到的,是 Claude Code 在runtime harness 上很强; 但还没有像 OpenAI 报告那样,在文档层就展示出:
• 代码库层次依赖方向完全机械化执行
• 架构层错了会有专门 linter 教 agent 修
这并不意味着它没有相关实践,只是从这次阅读到的 src 主体看,最强的护栏明显还在 runtime 层而不是 repo architecture linter 层。
8.4 这其实和它的产品定位有关
OpenAI 那套实践更偏内部特定项目深度开发; Claude Code 更像通用 agent runtime 产品。
因此 Claude Code 更优先强化:
• 多场景通用的执行护栏
• 多 Agent 统一任务控制
• 通用权限模型
• 上下文压缩与恢复
而不是把某个仓库的架构依赖约束写死成产品默认能力。
所以在这一项上,我的结论是:
Claude Code 已经深度实现了运行时约束的机械化,但还没有在公开可见层面完全走到 OpenAI 那种“仓库架构约束即 harness 主体”的阶段。
09
九、可观测性集成:Claude Code 已经把“看见运行时”这件事做得很认真
你文中把 Observability 纳入 Harness 核心组件,这是非常对的。 因为没有可观测性,Agent 就只是在黑箱里乱撞。
Claude Code 在这件事上的实现非常有代表性。
9.1 它对任务的可观测性很强
LocalAgentTask 会跟踪:
• toolUseCount
• tokenCount
• lastActivity
• recentActivities
• summary
远程任务也有自己的状态与进度模型。 这说明系统不是只关心“结果是什么”,还关心“任务过程中在干什么”。
这和你文中 OpenAI 那种把运行时观测接到 Agent 上的思路高度一致。
9.2 它对 query loop 与工具执行的可观测性也很强
在代码里可以看到大量:
• analytics 事件
• tool duration
• query profiler
• tracing
• startup profiler
• internal logging
这些东西不是花里胡哨,而是为了让系统知道:
• 任务卡在哪
• 工具耗时在哪
• query 的瓶颈在哪
• agent 的行为链条是什么
这正是 Harness Engineering 的基础之一: 如果系统无法观测 agent 行为,就无法持续收敛护栏。
9.3 它甚至把可观测性和 UI 统一起来了
很多系统会做后台 tracing,但用户看不见。 Claude Code 则通过 REPL 把可观测性的一部分直接产品化:
• task list
• progress
• notifications
• viewing agent transcript
• permission queue
这是一种非常务实的产品化 observability: 既服务工程团队调试,也服务用户理解系统状态。
9.4 与 OpenAI 式“接浏览器、查日志、看指标”的差异
Claude Code 里也存在 browser / MCP / diagnostics / terminal capture 等能力,但从这次阅读到的核心结构看,它最成熟的观测面仍然是:
• 任务级观测
• 工具级观测
• query 级观测
• session 级 UI 可见性
也就是说,它已经有了“可观测性接入 Agent”的强基础,但是否在所有默认场景都像 OpenAI 报告那样把产品日志与业务指标深度接入,还要视具体使用环境而定。
不过从 Harness 角度,它已经明显超过“只会盲跑”的阶段。
10
十、熵管理与垃圾回收:Claude Code 已经内建了多层抗熵机制
你文中讲 OpenAI 的 “AI Slop 清理”、定期 garbage collection agent,那是 Harness Engineering 非常重要但也经常被忽略的一层。
Claude Code 虽然没有直接写出“每周五 20% 时间清 AI Slop”这种叙事,但它其实已经具备多种抗熵机制。
10.1 上下文熵:通过 compact 持续清理
最直接的一层熵就是对话和上下文的熵。 Claude Code 在这方面非常强:
• microcompact
• auto compact
• reactive compact
• snip
这些机制本质上都在做一件事:
防止上下文中的无效堆积把系统拖进 Dumb Zone。
10.2 代码执行熵:通过角色分工与验证角色控制
Verification Agent、Plan Agent、Explore Agent 的分工,本质上都在减少单一 Agent 胡乱扩展职责带来的熵。
一个没有专业化、没有验证角色的系统,很容易让“写一点 -> 以为写完 -> 再乱修一点”的熵迅速堆积。 Claude Code 通过结构化角色在一定程度上缓解了这一点。
10.3 任务熵:通过 Task 生命周期与通知压平复杂度
如果系统允许大量后台任务而没有统一任务模型,时间一长一定会出现:
• 哪个任务还活着不清楚
• 哪个结果已失效不清楚
• 哪个 transcript 还值得看不清楚
Claude Code 的 Task 体系本身就是一种抗熵设计。 因为它把执行对象收束成了统一状态机。
10.4 文档与能力熵:通过插件、agent、settings、hooks 的明确作用域管理
整个系统大量使用:
• source 区分
• permission source 区分
• plugin / built-in / user / policy 分层
这其实也是一种抗熵方式: 不是让所有定制信息混在一处,而是明确“能力来自哪里、覆盖顺序是什么、作用域是什么”。
10.5 但它和 OpenAI 的“后台清理 Agent”还不完全一样
Claude Code 已经有不少护栏和清理机制,但如果严格对比你文中 OpenAI 那种:
• 定期运行清理 Agent
• 专门扫文档过期
• 清理冗余低质量代码
Claude Code 在公开可见部分还没有完全把“熵管理 Agent”做成同样强的固定产品面。
它更像:
• 用 runtime 抗熵
• 用结构化角色减熵
• 用 compact 去掉上下文噪声
而不是显式地把“清理 Agent”树成主线 feature。
因此这项上,Claude Code 是“强抗熵底座,弱显式清道夫产品化”。
11
十一、工程师角色转变:Claude Code 已经把“设计环境”这件事编码进系统了
你文章里很重要的一点是:
• 工程师角色正从“直接写代码”转向“设计 Agent 工作环境 + 管理 Agent 工作流”
Claude Code 的存在本身就在支持这个转变。
11.1 它让“环境设计”变成一等工作
因为 Claude Code 的真实能力很大程度取决于:
• AGENTS.md / 仓库指令
• agent definitions
• tools 暴露方式
• permission rule
• MCP / plugins / hooks
• worktree / remote / plan mode 选择
这意味着工程师和团队要想把 Claude Code 用好,工作重心自然会转向:
• 设计能力边界
• 设计任务流
• 设计验证流
• 设计恢复与审批机制
这和你文中的“工程师从写代码转向设计环境”的判断高度一致。
11.2 它也强化了“规划比编码更值钱”
Plan Mode、Plan Agent、Verification Agent、Task 系统,这些东西都在告诉用户:
不要把所有智力消耗在“立刻动手写”,而是更多放在如何组织执行。
这实际上就是 Harness Engineering 的核心文化迁移。
11.3 Claude Code 的 REPL 更像管理台而不是打字框
这一点特别值得强调。 因为 REPL 很容易被误解成“聊天 UI”。 但当它开始承担:
• 任务列表
• agent transcript 切换
• permission 控制
• sandbox 审批
• teammate 导航
• notifications
它其实已经变成了一个“Agent 工作台”。
这非常符合工程师角色的转变:
• 不再只是“我来写”
• 而是“我来编排、审查、授权、恢复、查看”
换句话说,Claude Code 不只是在技术上支持 Harness Engineering,它在交互模型上也在训练工程师进入 Harness mindset。
12
十二、如果按你文中的六大共识打分,Claude Code 目前处在什么位置
下面我按你文章最后总结的六大共识,快速给 Claude Code 做一个映射判断。
共识 1:瓶颈在基础设施,不在模型智能
匹配度:极高
整个代码结构都在证明它相信这一点。
共识 2:文档必须是活的反馈循环
匹配度:中高
Claude Code 尊重仓库文档与 AGENTS 体系,但更进一步把很多约束升级成 runtime 规则。
共识 3:思考与执行必须分离
匹配度:高
Plan Mode、Plan Agent、Verification Agent、结构化执行循环都在支持这一点。
共识 4:上下文不是越多越好
匹配度:极高
compact、角色裁剪、工具裁剪、omitClaudeMd、fork cache 设计都说明了这一点。
共识 5:约束必须机械化执行
匹配度:高,但偏 runtime 约束
权限、工具、任务、模式都机械化了; 但 repo architecture linter 级别的机械化还没看到像 OpenAI 案例那样极致。
共识 6:工程师角色从写代码转向设计环境
匹配度:高
Claude Code 整个产品形态就是在放大这种新角色。
因此,如果从 Harness Engineering 成熟度模型来粗估,我会说:
Claude Code 已经明显超越 Level 2,接近 Level 3,并在若干维度上碰到了 Level 4 的边缘。 但它更像“交互式、高控制面的自治系统”,而不是 Stripe 那种极端无人值守 PR 工厂。
13
十三、Claude Code 相比 OpenAI / Anthropic / Stripe,最有自己的地方是什么
如果说 OpenAI 的特色是“架构约束机械化 + 零手写代码环境设计”, Anthropic 的特色是“长任务跨会话连续性”, Stripe 的特色是“企业级无人值守并行 PR”,
那么 Claude Code 最独特的地方是:
它把 Harness 做成了一个统一的、用户可交互的运行时控制面。
这个特点体现在三个方面:
13.1 不把 Harness 藏在后台
很多团队的 Harness 很强,但主要存在于:
• CI
• Devbox
• Linter
• pipeline
Claude Code 则把大量 Harness 直接暴露在前台产品里:
• task list
• permission dialog
• viewing agent
• plan mode
• background agent notifications
这使得 Harness 不只是工程团队内部基础设施,也是用户直接感知到的产品能力。
13.2 它是“多后端统一 Agent Runtime”
同一个 AgentTool 可以路由到:
• local
• background
• fork
• worktree
• remote
• teammate
这说明 Claude Code 的 Harness 不是为某一种 execution environment 单点设计,而是围绕“Agent Runtime”的统一抽象设计。
13.3 它特别重视“控制权始终在人类手里”
无论是 permission、plan mode、sandbox、foreground task,Claude Code 明显都更偏:
• 强交互
• 可中断
• 可查看
• 可恢复
而不是极端无人值守。
这让它更适合一个广谱产品,而不是只适合内部高成熟团队。
14
十四、Claude Code 仍然存在的三个明显空白
为了让这篇分析更完整,也必须诚实指出 Claude Code 相比你文中的 Harness 理想形态,仍有一些明显空白。
14.1 缺少更强的“项目进度文件驱动工作流”
Anthropic 的典型做法是:
• init.sh
• progress.txt
• feature_list.json
这些东西把长期项目状态显式外置,特别适合跨会话长跑。
Claude Code 虽然有 task state、transcript、agent memory,但还没有在默认工作流里把“结构化功能列表与进度文件”做成同等核心的一层。
14.2 缺少更强的 repo-level architecture enforcement 产品化
Claude Code 在 runtime 约束上很强,但还没完全看到 OpenAI 式那种:
• 明确层级依赖方向
• 自定义 linter 错误直接教 agent 修
• 架构约束进入默认工具链
这部分如果补上,会让它的 Harness 更像“从运行时延伸到仓库设计规则”。
14.3 对“长期可维护性 / AI slop 清理”的显式产品面还不够强
Claude Code 已经有 compact、specialization、verification 等抗熵机制。 但如果对标你文中的 OpenAI / “垃圾回收 Agent” 路线,它还没有把“代码库长期清理与质量回收”树成特别明确的一等产品 feature。
这可能是它未来很值得加强的一块。
15
十五、如果把 Claude Code 看成 Harness Engineering 产品,它最值得学的五件事
如果你不是想复刻 Claude Code 全部功能,而是想从中提炼 Harness 经验,我会总结出下面五件最值得借鉴的事情。
15.1 先把 Agent 变成 Task,再谈多 Agent
没有 Task 模型,所有多 Agent 最后都会退化成“再发一个子请求”。
15.2 把上下文治理做成主循环内建能力
不要等 prompt 爆炸后再补救。 compact / microcompact / reactive compact 这类机制要尽量成为主路径。
15.3 角色差异要体现在工具面和权限面,不只是 prompt 语气
否则 Agent specialization 只会停留在表演层。
15.4 权限必须中心化,否则多 Agent 系统很快失控
Leader-centered permission 这一点非常值得抄。
15.5 REPL / UI 控制面不是附属物,它是 Harness 的一部分
让用户能看见任务、切换 agent transcript、理解系统正在做什么,本身就是可靠性工程的一部分。
16
十六、一张总图:把 Claude Code 放进 Harness Engineering 视角里看

17
十七、最终结论
回到你那篇文章最后的那句判断:
瓶颈不在智能,而在基础设施。
Claude Code 的源码几乎就是这句话的一个大型注脚。
它最值得称赞的地方,不在于它拥有多少工具、多少 Agent、多少模式,而在于它已经在实际上做到了下面这些事:
01 上下文架构化 它不是简单塞上下文,而是在持续治理上下文。
01 角色运行时化 Agent 不只是 prompt,而是具备工具边界、记忆、权限、隔离策略的运行规格。
01 执行结构化 规划、执行、验证、恢复、通知不再混在一起。
01 任务一等化 Agent 被纳入 Task 系统,获得生命周期、可视性、恢复性。
01 控制中心化 多 Agent 可以分散执行,但最终控制权仍回到用户理解得了的主界面。
01 Harness 产品化 它不是只在后台做护栏,而是把护栏做成了用户可感知的控制面。
所以如果一定要回答“Claude Code 做了哪些实际的 Harness 优化”,最准确的答案不是列一个零散 checklist,而是下面这句话:
Claude Code 已经把 Harness Engineering 从“文档和约定”推进到了“运行时与产品结构”本身。
它不是只在告诉 Agent 应该怎么做,而是在努力构造一个环境:
• 让 Agent 更容易做对
• 更难做错
• 做错后能恢复
• 多个 Agent 同时工作时不失控
• 用户始终知道系统在干什么
如果 Harness Engineering 真的代表 AI Agent 时代的软件工程范式革命,那么 Claude Code 已经不是这场革命的旁观者,而是一个很具体、很扎实、很有代表性的落地样本。
当然,它还没有填平所有空白:
• 对长期项目结构化进度管理,仍可更强
• 对 repo-level 架构约束的机械化执行,仍有提升空间
• 对长期 AI slop 清理与维护性保障,还可以更产品化
但这并不影响整体判断。
因为真正重要的是,它已经跨过了那条分水岭:
从“让模型能写代码” 走到了 “设计让模型能长期可靠写代码的系统”。
这,正是 Harness Engineering 的核心。
18
附:一句话版总结
如果你只记一句话,请记这句:
Claude Code 最重要的优化,不是让 Agent 更自由,而是让 Agent 的自由被放进一套可治理、可观察、可恢复、可验证的工程 Harness 里。
