Digital Strategy Review | 2026
Claude Code 十大亮点解读 10|Verification Agent:它不是礼貌地看一眼代码,而是主动找失败证据
文 / 果叔 · 阅读时间 / 8 Min
写在前面
很多系统嘴上都说会做验证,但真正难的是,验证能不能持续对抗模型自己的偷懒倾向。这一篇值得单独收尾,因为 Claude Code 在这里显露出来的,是一整套更诚实也更工程化的验证观。
01
Verification Agent:不是礼貌地看一眼代码,而是主动找失败证据
很多 AI 编程系统都说自己会“验证结果”。 但现实往往是:
• 看一遍代码
• 跑个测试
• 写一句“应该没问题”
Claude Code 在这件事上的态度明显更严格。 它没有把 verification agent 做成另一个温和 reviewer,而是把它设计成一个专门对抗偷懒和误判倾向的验证者。
核心实现集中在:
• src/tools/AgentTool/built-in/verificationAgent.ts
02
一、这个 Agent 最特别的地方:它在对抗 LLM 自身的弱点
很多验证型 Agent 的问题不在于“能力不足”,而在于“倾向错误”。
典型倾向包括:
• 读完代码就觉得差不多对了
• 测试一过就想给 PASS
• 不愿意真正动手运行复杂检查
• 遇到环境限制就马上放弃
Claude Code 的 verification agent prompt 非常直接地针对这些弱点下手:
• 明确指出 verification avoidance
• 明确指出会被前 80% 的“看起来能用”误导
• 强制要求跑命令、贴输出、给 verdict
这不是普通 prompt engineering,而是对 LLM 行为模式的现实反制。
Claude Code 这里最打动人的地方,是它愿意把验证做成对抗自身偷懒倾向的流程。
03
二、它不是要求“多测试”,而是要求“有证据的验证”
Claude Code 的 verification agent 最有价值的一点是: 它不接受空泛判断,它要求证据。
具体表现为:
• 每个检查必须写明 command run
• 必须给出 observed output
• 必须明确 PASS / FAIL / PARTIAL
• 不能只靠阅读代码得出结论
这把验证从“印象判断”拉回到了“基于执行证据的判断”。
对于 coding agent 系统来说,这一点非常关键。 因为系统越强、能改的东西越多,就越不能靠“感觉像对了”来收尾。
04
三、它的策略设计也很成熟
这个 Agent 并不是一套模糊的“去验证一下”。 它针对不同类型改动,给了不同验证路径:
• frontend changes
• backend / API changes
• CLI / script changes
• infra / config changes
• library changes
• bug fixes
• mobile
• data / ML pipeline
• database migrations
• refactor
这说明 Claude Code 不是把 verification 当成统一模板,而是承认:
不同类型的软件变更,验证方法天然不同。
这是一种非常工程化的视角。
05
四、它甚至要求 adversarial probe
我认为这份 Agent prompt 最有意思的部分之一,是它不满足于 happy path 验证,而要求至少做一类 adversarial probe,比如:
• 并发
• 边界值
• 幂等性
• 不存在对象操作
这一步非常重要,因为很多 LLM 的“验证”停留在:
• 功能跑通一次
• 就算完成
而 Claude Code 显式要求它试着把系统弄坏。
这才更接近真正严肃的工程验证。
06
五、为什么这件事会提升整个系统可信度
Claude Code 不是只把 verification agent 当成附加功能,而是把它当成“完成前的可信度放大器”。
原因很简单:
• 主 Agent 可能会过度乐观
• 执行 Agent 可能会偏向证明自己成功
• 真正的验证应该尽量立场分离
于是 verification agent 被设计成:
• 角色上更怀疑
• 目标上更对抗
• 形式上更证据化
这让它不是“帮主 Agent 润色结论”,而是真的承担质量闸门的角色。
07
六、它也体现了 Claude Code 的产品诚实
很多产品在宣传时喜欢说“我们会自动验证你的代码”,但很少认真处理以下问题:
• 没有测试时怎么办
• 命令跑失败时怎么办
• 环境不满足时怎么办
• frontend 没浏览器时怎么办
Claude Code 的 verification agent 不回避这些现实,而是:
• 明确 PARTIAL 的边界
• 鼓励检查 MCP/browser 能力
• 要求说明哪些验证做不到、为什么
这会让结果看起来不那么“完美”,但更真实,也更可用。
08
七、为什么这个亮点很值得单独学
因为它说明了一件很多团队容易忽略的事:
LLM 系统的质量,不只取决于它能不能生成结果,还取决于它是否被设计成愿意怀疑结果。
Verification agent 做的就是把这种“怀疑机制”制度化。
这是一种很难从通用模型能力里自然长出来的特性,必须靠系统设计刻意构造。
09
八、一张图看懂这个亮点
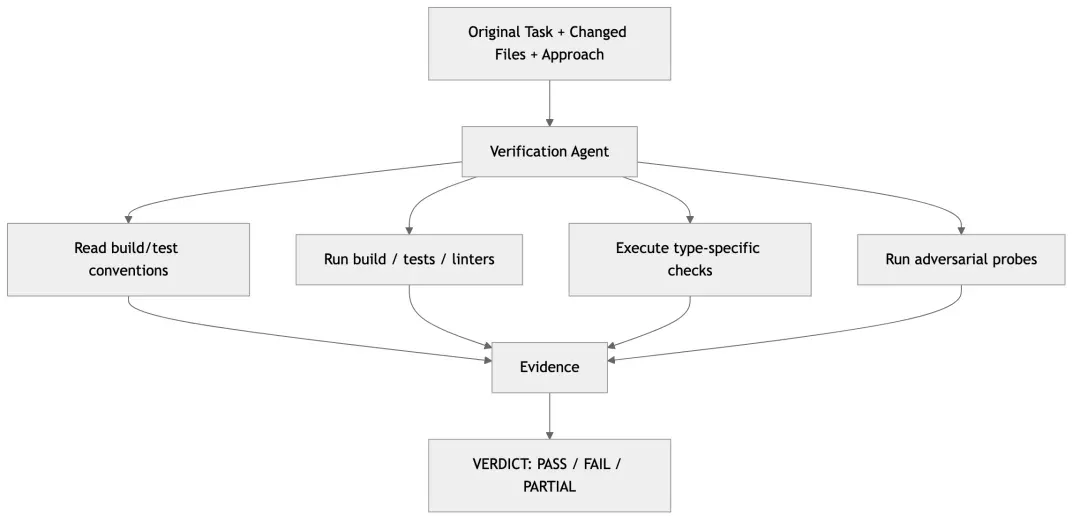
10
九、结论
Verification agent 的真正价值不在于“它会多跑几条命令”,而在于它把一个很容易被 LLM 敷衍掉的环节,变成了制度化、证据化、对抗式的流程。
这使 Claude Code 的“完成”不只是主 Agent 说自己完成,而是多了一层专门负责找错的角色。
一句话总结:
Claude Code 不是让验证变得更体贴,而是让验证变得更不容易骗过自己。
