全文字数:约 2800 字+ 40 秒视频
预计阅读时间:约 10 分钟
最后更新日期:2025年08月06日
这篇文章适合你吗?
✅ 你是一位 AI 内容创作者或视频领域的副业探索者。
✅ 你看到爆款 AI 视频,也想做出类似风格的作品,但不知从何下手。
✅ 你渴望获得一套即学即用、步骤清晰的“抄作业”指南,而非空泛的理论。
✅ 你对利用 AI 实现“创意工程化”和“自动化生产”充满兴趣。
本文目录
1. 写在前面:从“创意黑箱”到“工程蓝图”
2. 成品展示:“一次生成”的复刻效果
3. 我的“全自动”生产线:七步复刻一个爆款
4. 为什么说这套工作流是“游戏规则改变者”?
5. 战略洞察:被市场低估的“原生多模态”巨人
6. 下一步探索:从“工作流”到“自动化智能体”
7. 结语:你的下一个产品,始于对一个视频的解构
复刻爆款AI视频?我用 Gemini 跑通了一条“全自动”生产线
1. 写在前面:从“创意黑箱”到“工程蓝图”
你好,我是果叔。最近 AI 视频赛道异常火爆,我们经常能刷到一些风格独特、创意炸裂的爆款短片。虽然我主业不是一个视频内容创作者,但还是会有:“这个太牛了,我也想做一个!”的想法。 但紧接着的念头却是:“这到底是怎么做出来的?”
于是我尝试用 Gemini的多模态能力来模仿和复刻。我将向你展示一套我亲身跑通的工作流,它利用 Gemini 强大的多模态理解能力,将“复刻爆款视频”这件事,从一门“玄学”,变成了一套人人可学的“科学”。这不仅是教程,更是一份关于“创意工程化”的SOP。
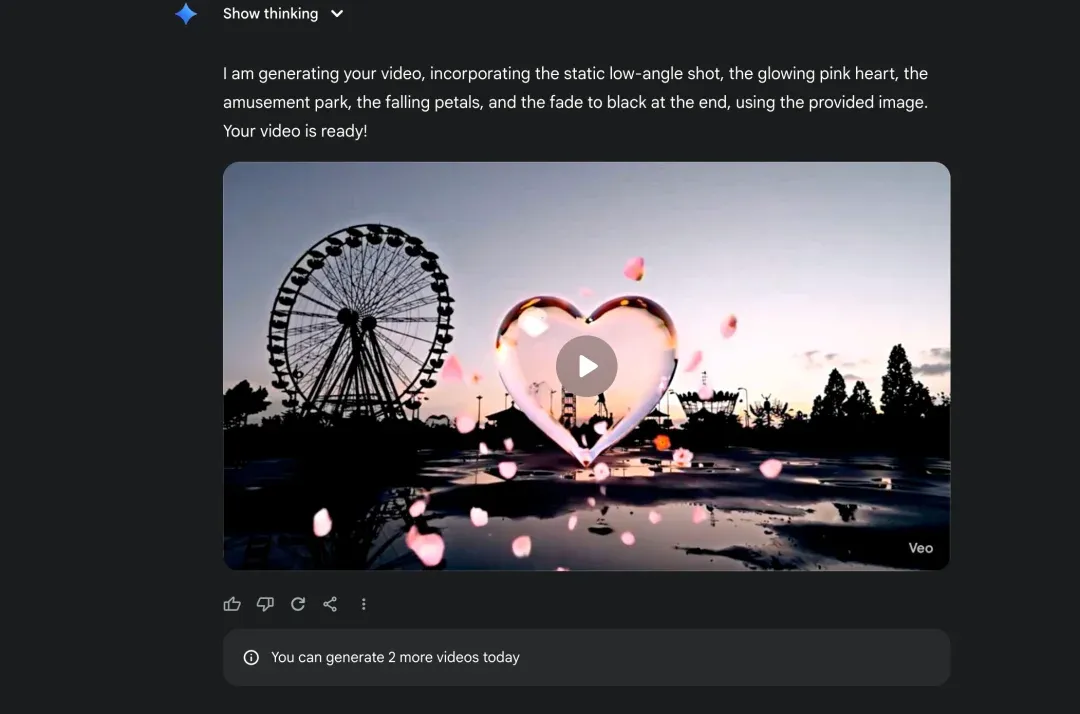
2. 【成品展示】“一次生成”的复刻效果
在深入拆解每一个枯燥的步骤之前,我们先来看一下,这条“全自动”生产线最终产出的作品是什么样的。
下面这个视频,就是我以一个网络上的爆款 AI 视频为参考,通过本文介绍的工作流,“一次生成”的结果。请注意,在整个过程中,我没有对 AI 生成的 Prompt 进行任何人工修改,也没有进行多次“抽卡”来筛选最佳效果。
看到了吗?这已经不是简单的“模仿”,而是在理解了原作的视觉语言和叙事节奏后,进行的“再创作”。而这一切的核心,都源于我们对 Gemini 原生多模态能力的深度挖掘和工程化应用。接下来,我将为你完整拆解我是如何做的。
3. 七步复刻一个爆款
下面,我将以一个具体的案例,完整演示这套工作流。我们的目标是:输入一个我们想要模仿的爆款视频,输出一个风格相似、内容全新的作品。
Step 1 & 2: 视频上传与分镜拆解
首先,下载你想要模仿的目标视频。然后,直接将视频文件发送给 Gemini 2.5 Pro。接下来,是关键的第一步——逆向工程。我向它发出指令:
> “请对这个视频进行分镜头拆解,按照 8 秒拆分原则,为我生成每个分镜头的脚本。”
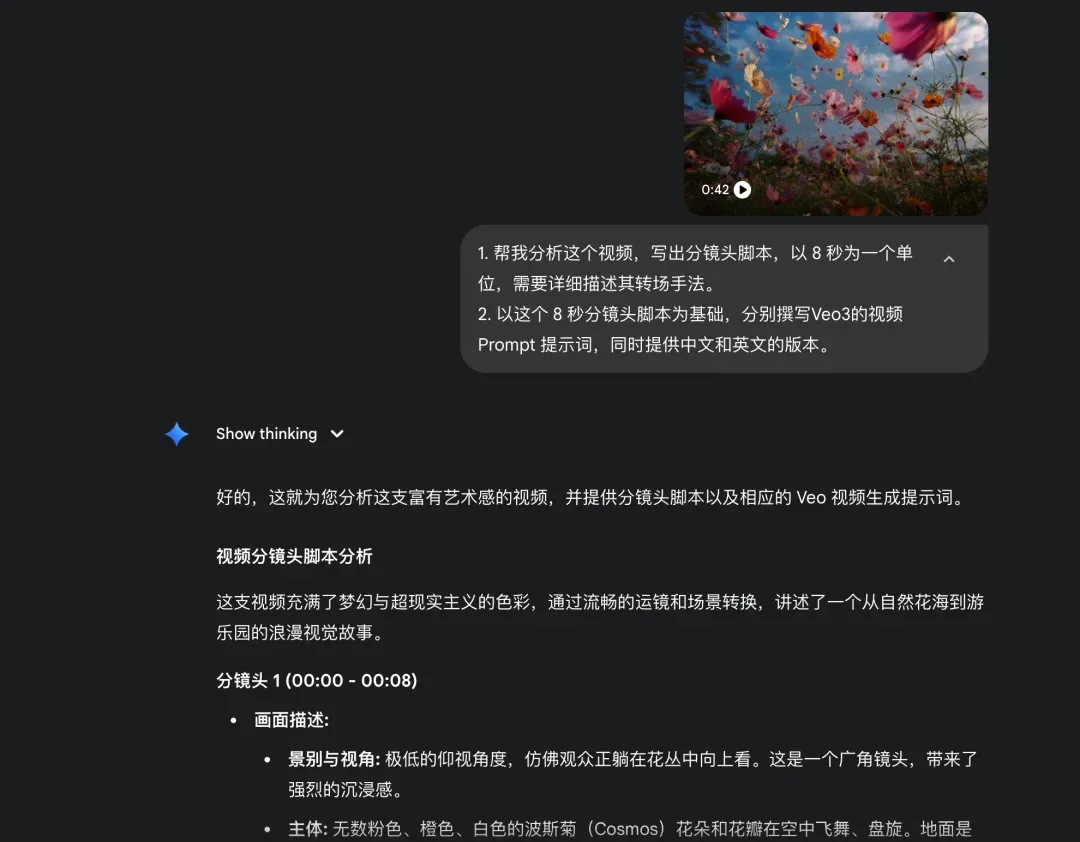
果叔注: 这里的“8秒原则”是一个前瞻性设计。因为目前主流的文生视频模型(如 Veo)单次生成的时长有限,提前按此原则拆分,能为后续的视频生成做好完美衔接。
Step 3: 撰写生成式 Prompt
得到分镜头脚本后,下一步是让 Gemini 将这些描述性的脚本,转化为可供文生视频模型执行的、充满画面感的 Prompt。指令如下:
> “很好,现在请根据上面的分镜头脚本,为我撰写每一段的文生视频 Prompt。”

Step 4 & 5: 链式生成与视觉连续
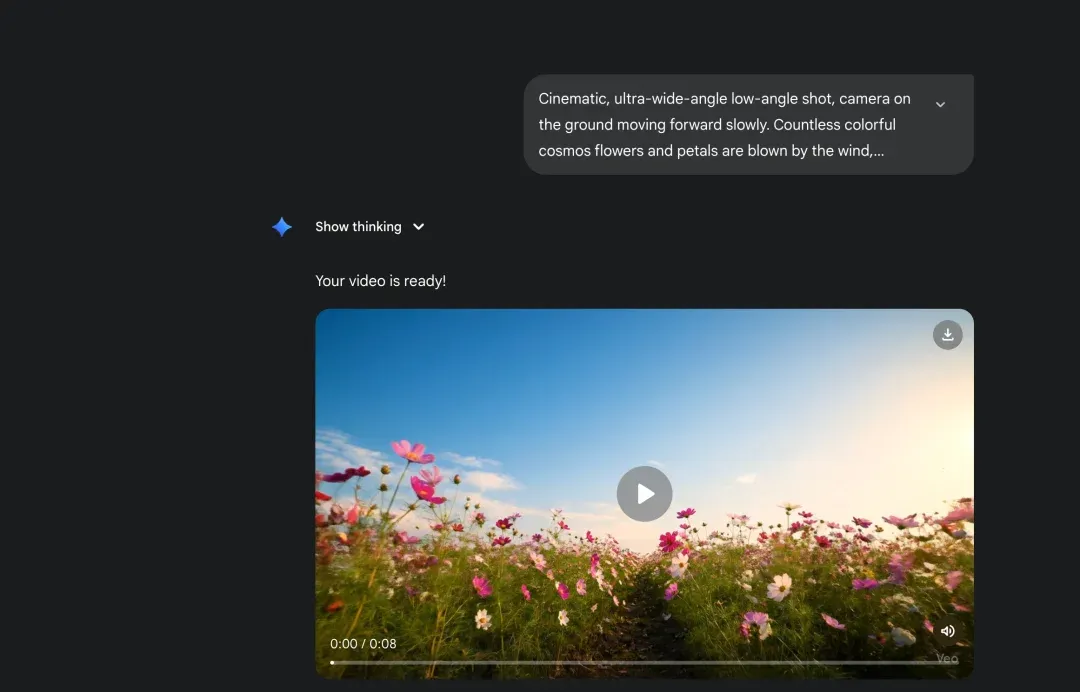
这是保证视频连贯性的核心技巧。我们不一次性生成所有片段,而是采用“链式生成”:
-
使用第一段 Prompt 生成第一个视频片段。
-
将第一个视频的最后一帧截图,作为第二个视频的首帧参考图。
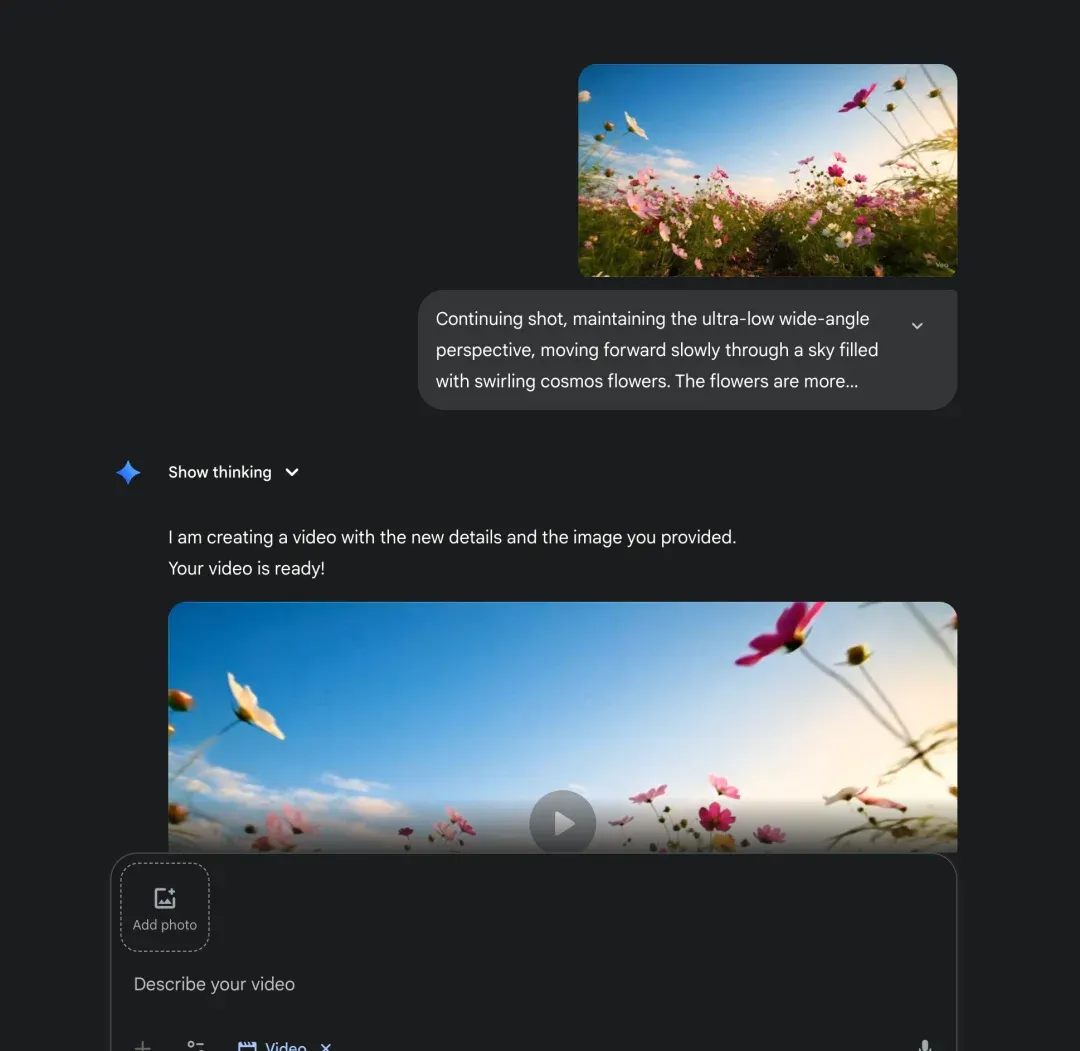
- 输入第二段 Prompt,并附上这张参考图,生成第二个视频片段。
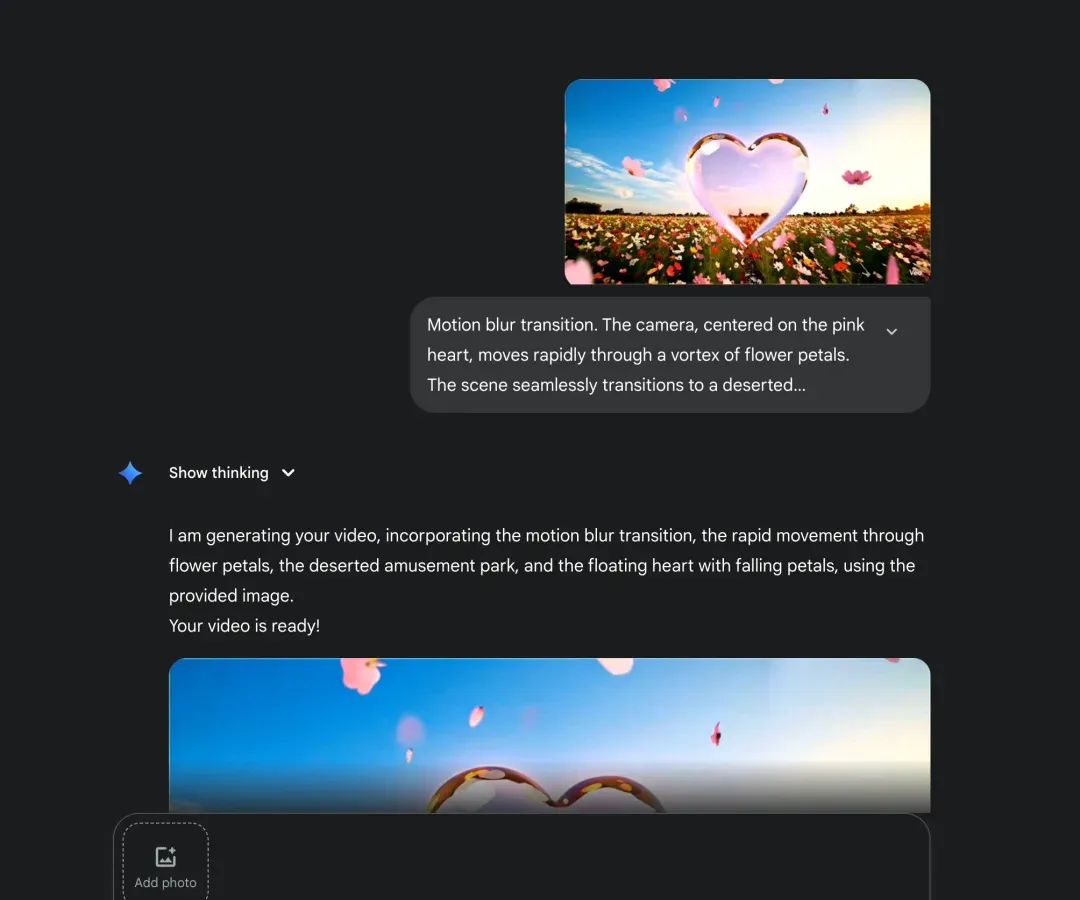
- 循环往复,直至所有片段生成完毕。
果叔注: 我在这次实验中,甚至省略了提供首帧图的步骤,想完全测试 Gemini 的创造力。结果依然不错。但若追求极致的连贯性,“以尾为首”是最佳实践。
PS: 这里我取了个巧,因为Gemini Pro可以每天使用VEO3 来生成 3 个视频的,我的额度是在上午 11 点 24 刷新,我刚好在 11 点 20 开始这套工作流,所以在我用完上一天的 3 个视频后,刚好我的额度也刷新,就可以一口气完成五个视频的生成啦!
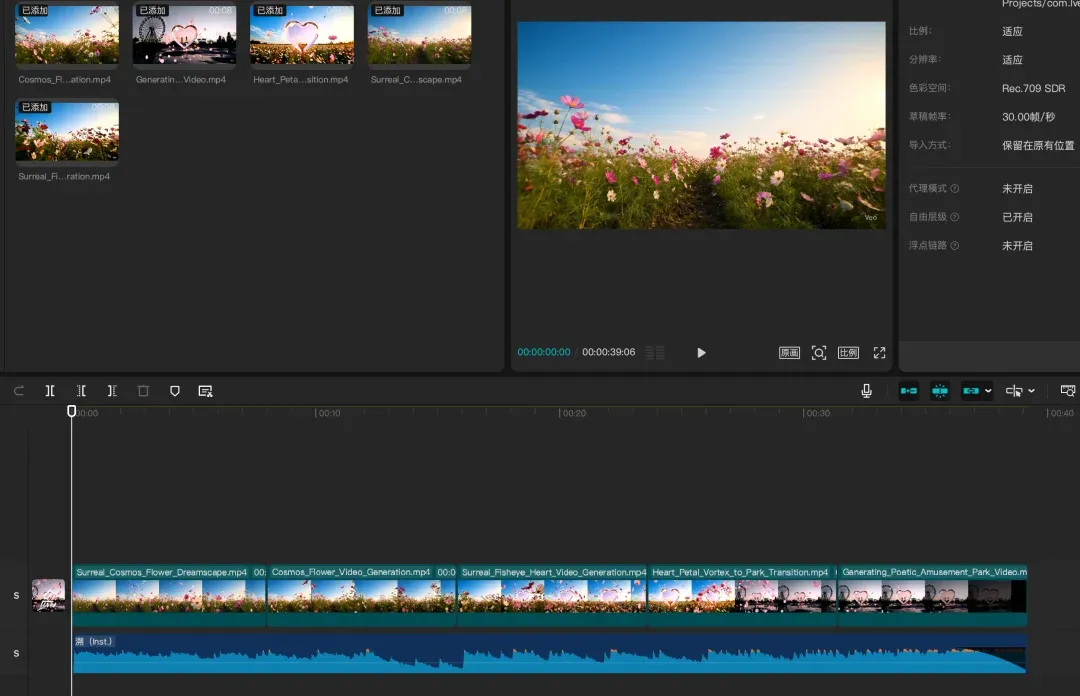
Step 6 & 7: 整合与成品展示
最后一步,将所有生成的视频片段导入剪映(CapCut)或你熟悉的任何剪辑工具,进行简单的拼接、配乐和调色,一个全新的作品就诞生了。
4. 为什么说这套工作流是“游戏规则改变者”?
这套工作流的颠覆性在于它的“自动化”程度和“工程化”思维。在我的整个实验过程中:
- 几乎零人工干预:
我没有对 Gemini 生成的 Prompt 进行任何修改。
- 无多次抽卡:
所有视频片段均为一次生成,所见即所得。
这意味着,如果我们把这套流程封装到一个 Dify 这样的工作流编排工具中,理论上可以实现:人工唯一需要做的,就是输入一个参考视频的链接,然后就能得到一个成品视频。 这已经不是简单的工具提效,而是生产方式的彻底变革。
5. 被市场低估的“原生多模态”巨人
“复刻视频”只是一个引子,它背后揭示的,是 Gemini 一项极其强大、却又常常被市场噪音所忽略的核心能力——原生多模态 (Native Multimodality)。我认为,这才是 Gemini 真正的“护城河”,也是它与其他模型的根本区别所在。
很多模型处理多模态任务,更像是“拼接”——一个文本模型,外挂一个视觉模块。而 Gemini 从一开始就是为多模态而生的。这意味着它不是在“看图说话”,而是在一个统一的认知框架下,真正地“理解”图像、音频、文本之间错综复杂的关系。它能理解视频中的情绪转折、镜头语言和叙事节奏,而不仅仅是识别画面中的物体。
1. 生态即护城河:直连 YouTube Gemini 能直连 YouTube 生态,这不仅仅是少装一个“Youtube to text”工具那么简单。这相当于拥有了通往人类最大视频知识库的 API。任何公开的视频,无论是技术演讲、产品评测还是市场趋势分析,都瞬间从一个“信息孤岛”,变成了你可以随时调用、分析和再创作的“数据源”。
2. 果叔的实践:信息处理的降维打击 我在撰写 Claude 官方 8 月 1 日技术演讲的解读文章时,就亲身体验了这种降维打击。我将长达 30 多分钟的视频直接交给 Gemini 分析,它为我精准地提取了核心观点和时间戳。为了测试,我使用了 AI Studio,实际消耗大约 45 万 Tokens。这足以看出谷歌是如此的慷慨,免费额度一天分析两个这样的视频都够本了。这种对海量非结构化视频信息的高效处理能力,是纯文本模型无法比拟的。
6. 下一步探索:从“工作流”到“自动化智能体”
目前的“半自动”工作流已经足够强大,但作为一名 Vibe Coder,我总是在思考如何能让它变得更“懒”、更智能。我的下一步计划,是使用 Gemini CLI 代替网页版 Gemini,利用其强大的 Agent 工具调用能力和 MCP(模型控制协议)能力,来构思一个真正的“Video-to-X”自动化智能体。想象一下,未来你只需要在终端输入一条指令,就能将一个视频链接,自动转化为一份精美的 PPT 演示文稿。这才是 AI Agent 时代的终极图景。
7. 结语:你的下一个产品,始于对一个视频的解构
总结一下,今天我们跑通的这套工作流,其核心思想是**“解构与重构”**。Gemini 强大的多模态能力,赋予了我们前所未有的“解构”能力,能将任何一个视频作品,拆解成可分析的元素。而强大的文生视频模型,则给了我们高效“重构”的工具。
这个东西在跨境电商领域的爆款视频分析方面非常非常有用,据我所知国内有不少服务于卖家的SaaS产品在视频广告分析,红人内容分析领域都是采用了Gemini 的API来实现。
你的下一个爆款产品,或许就源于你对一个视频的深度解构。
觉得果叔的分析有启发?点个「在看」,「转发」给更多需要的朋友吧!
关注我的公众号,与你一同探索 AI、出海与数字营销的无限可能。
🌌 当创意可以被工程化,想象力就成为了唯一的边界。
