关于 GEO 的讨论,已经从概念介绍走到需要证据约束的阶段。
过去一段时间,很多内容团队都在问同一个问题。ChatGPT、Google AI Overview / Gemini、Perplexity 这些产品正在改变信息的呈现方式,网页还会不会被点击,内容还有没有机会进入答案,传统 SEO 的方法还剩下多少有效性。
这些问题都真实存在。只是行业里的很多说法仍然停留在口号层面。有人把 GEO 讲成 SEO 的替代品,有人把它讲成一套页面结构技巧,也有人把 FAQ、标题写法、Schema 之类的局部经验,包装成一整套通用解法。
热闹归热闹,但真正需要被回答的问题更朴素:AI 在什么情况下搜索,搜索之后选择哪些来源,这些来源在最终回答里到底留下了多少痕迹。
这篇文章依据的材料,是一个名为 geo-citation-lab 的公开研究资料库。研究者设计了 602 条 Prompt,在 ChatGPT、Google AI Overview / Gemini、Perplexity 三个平台上观察搜索触发、来源选择和引用使用情况。
它比较有价值的地方,在于没有停在「被引用次数」这一层。研究者把引用页面抓取回来,形成 23,745 条 citation-level 记录,并提取 72 维特征,试图把一个模糊问题拆开:同样出现在 AI 的来源列表里,为什么有些页面只留下一个链接,有些页面会被更深地写进答案。
换到内容生产现场,这个问题会更具体。
一个运营同事打开 AI Overview,看到竞争对手的官网被引用了。页面有链接,但没有点击数据。另一个页面在 ChatGPT 答案里被多次使用,段落里的事实和原文高度接近。两者都叫「被 AI 引用」,可它们带来的价值并不一样。
前者更像曝光。
后者更像证据。
这套研究的意义,就在于它把这种差别放到了数据表里。
实验如何把 AI 搜索拆开
先看实验设计。用户提出问题,AI 决定是否搜索,搜索之后展示来源,再用这些来源组织答案。传统 SEO 主要看网页在人类搜索结果里的位置;GEO 需要继续往后看,看网页有没有进入 AI 的候选来源,看进入之后有没有被答案吸收。
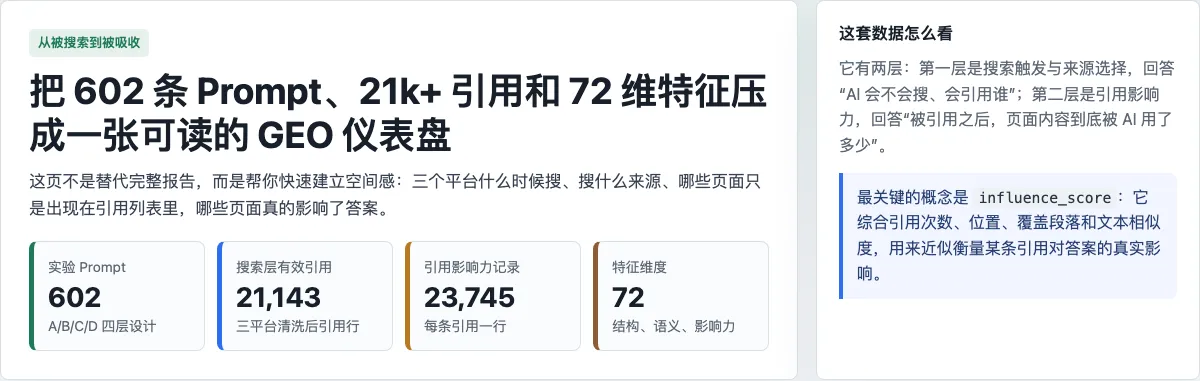
602 条 Prompt 被分成几组。A 层覆盖 Commerce、Finance、Healthcare、Local、News、Technology 等行业问题;B 层比较自然提问、要求来源、专家角色三种表达方式;C 层做中英文对照;D 层放入高风险、模糊、多约束、长决策型问题。
搜索层数据记录了 21,143 条有效引用。字段里有触发搜索、引用域名、网站类型、国家、语言、域名权威度等。
引用影响力层更细。每一条引用是一行记录,页面长度、标题数量、段落数量、列表密度、是否包含数字、是否包含定义、是否包含对比、是否包含步骤、页面和问题的语义相似度、页面和答案的语义相似度,都被放进同一张表。
其中有一个综合指标叫 influence_score。这个分数由引用出现次数、首次出现位置、覆盖答案段落比例、TF-IDF 相似度、bigram / trigram 重叠率共同计算。
它不能代表模型内部真实权重,也不能证明因果关系。它能做的,是用答案表面的可观察痕迹,估算一条引用被使用的深浅。
这个克制很重要。因为 GEO 领域最容易出现的误区,就是把一点局部经验讲成底层规律。
当三个平台回答同一批问题
先看搜索触发。
在这套实验里,ChatGPT 的搜索触发率是 98.64%,Google AI Overview 是 99.67%,Perplexity 是 100%。如果只看这一项,很容易产生一种错觉:既然三个平台几乎都会搜索,那么内容只要进入网页,就会被 AI 看到。
数据很快把这个想法压了下去。
ChatGPT 平均每条 Prompt 引用 6.88 个来源,Google 是 12.06,Perplexity 是 16.35。三者都在搜索,但每次打开的资料包大小不同。
这时可以想象一个很普通的场景。
同样问一个「最近 AI 有哪些重要进展」的问题。Perplexity 可能拉出一串来源,新闻、博客、官网、论坛混在一起。Google AI Overview 也会给出较宽的来源列表,尤其当问题里要求引用或来源时,列表会变长。ChatGPT 则更收敛,它可能只拿少数几个来源组织回答。
如果你只负责品牌曝光,会本能地喜欢宽列表。来源越多,进入列表的机会越多。
但如果你关心答案本身如何形成,另一个指标会更重要。
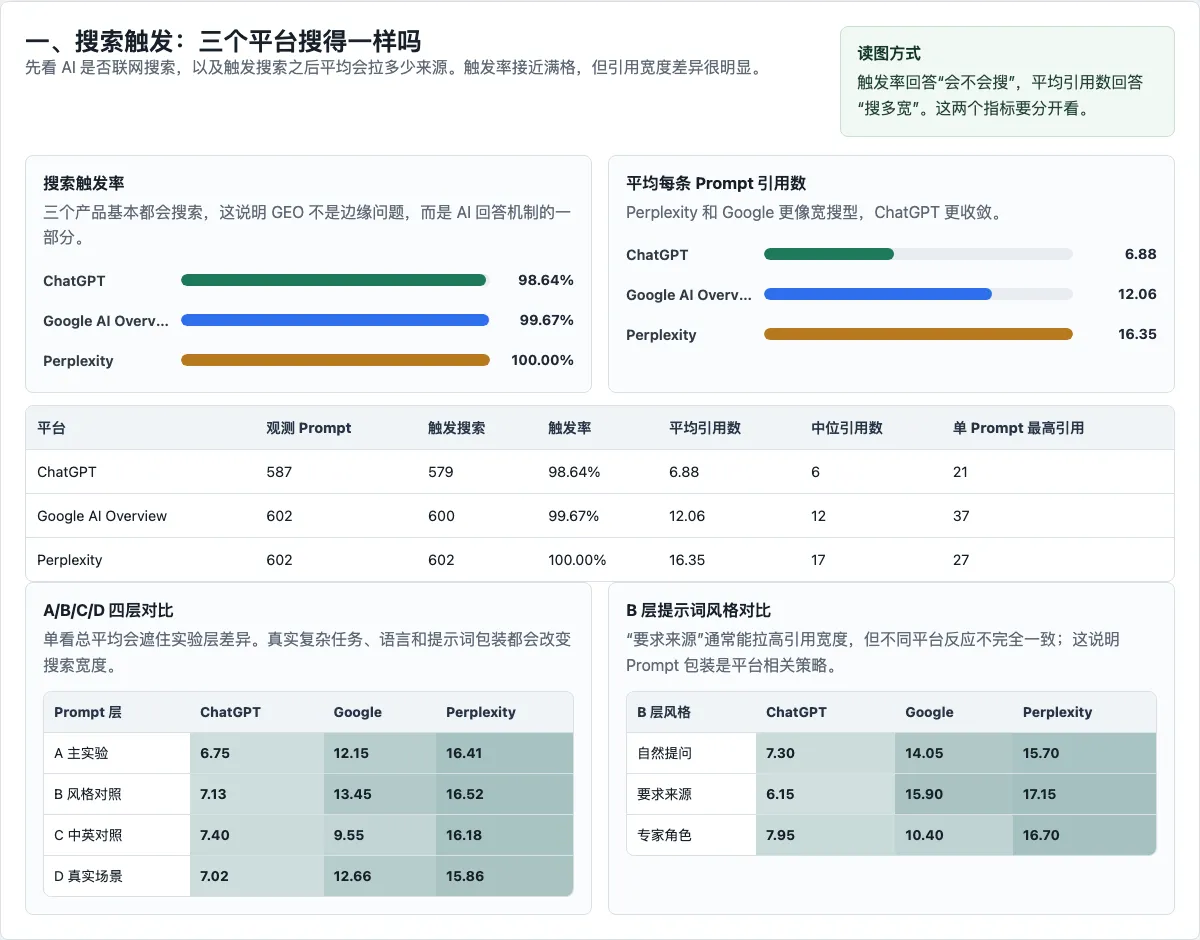
在抓取成功页面里,ChatGPT 的单条引用平均影响力是 0.2713,Google 是 0.0584,Perplexity 是 0.0646。ChatGPT 引用少,单条引用在答案里的痕迹更深;Google 和 Perplexity 引用多,平均到每个来源上,使用深度更浅。
这给内容团队带来一个很实际的分叉。
有些页面适合争取更多候选列表里的出现。它们承担的是分发任务。有些页面需要被写成更强的证据源,一旦被模型选中,就能够支撑答案的主体。它们承担的是论据任务。
过去我们常把这两件事混在一起,都叫「被引用」。这套数据把它们拆开了。
候选池里的老面孔
很多人谈 GEO 时,会想象 AI 搜索正在建立一套全新的信息秩序。这个想法有吸引力,但搜索层数据没有那么浪漫。
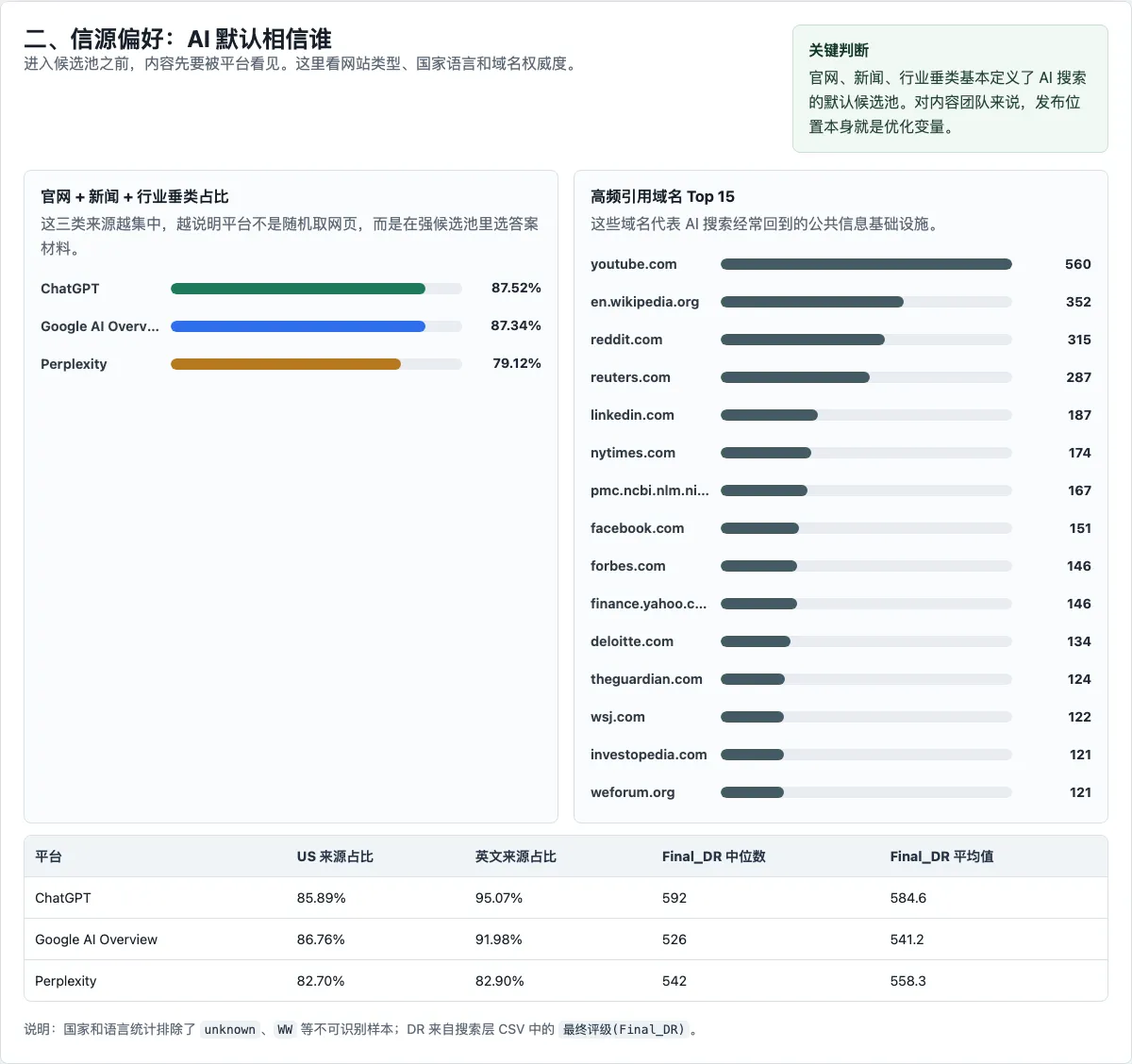
三个平台引用的网站类型里,官网、新闻、行业垂类占比很高。ChatGPT 中这三类占 87.52%,Google 是 87.34%,Perplexity 是 79.12%。
把这组数字放到真实工作台上看,会更容易理解。
一个出海 SaaS 团队写了一篇非常用心的行业文章,放在自己的小站上。文章结构清楚,标题也对齐目标问题。但当 AI Overview 回答相关问题时,来源里出现的仍然是大型媒体、官方文档、行业协会、头部垂直网站。
小站内容未必差。
很多时候,它还没有被放进模型容易信任的公共资料层。
国家和语言也呈现类似情况。在排除 unknown 和 WW 这类不可识别样本后,US 来源占比在三个平台里都超过 82%。英文来源占比也很高,ChatGPT 是 95.07%,Google 是 91.98%,Perplexity 是 82.90%。
这组数据提醒我们,GEO 并没有摆脱旧的信息基础设施。AI 搜索看起来像一个新入口,背后仍然压着网页索引、域名权威、语言生态、媒体分发和外部链接。
所以,页面内部的 AI 友好改造只是一部分工作。标题更清楚,FAQ 更完整,结构更规整,这些都可能有用。但一个页面缺少权威背书、缺少外部链接、缺少稳定索引、缺少在英文信息网络中的信号时,它很难突然变成模型重度使用的来源。
这也是 GEO 讨论里最容易被跳过的部分。
很多团队急着改页面,却没有先处理发布位置、主题权威和外部信任。结果页面看起来更像一份标准答案,候选池里仍然没有它。
被答案真正用到的页面长什么样
引用影响力层更接近内容写作现场。
在 Top 25% 和 Bottom 25% 页面之间,差异很明显。高影响力页面平均 1,943 个词,低影响力页面只有 170 个词。高影响力页面平均有 10.59 个标题,低影响力页面只有 0.85 个。段落数量是 47.49 对 8.34,列表项数量是 19.66 对 0.98。

想象模型在回答一个复杂问题时,要从来源页面里取材料。一个页面只有一段短介绍,最多能提供一个背景引用。另一个页面有定义、数据、对比、限制条件、步骤说明,还有清晰的小标题。后者可以被切成多个片段,分别塞进答案的不同位置。
这就是「被引用」和「被吸收」之间的距离。
内容体裁也有明显差异。包含数字或统计信息的页面,平均影响力比不包含的高 61.5%。包含定义的页面高 57.3%。包含对比的页面高 55.3%。包含步骤或指南的页面高 41.2%。纯问答格式低 5.7%。
这里面有一个细节很有意思:FAQ 没有天然优势。
过去做 SEO,FAQ 是常见做法。它容易覆盖长尾问题,也方便页面结构化。到了 AI 搜索场景,FAQ 仍然可以用,但它不会自动让页面变成好证据。模型在页面里寻找的,是能够被拿走的事实单元,而不只是问号和答案的排列。
一篇页面里,如果有清楚的概念边界,有能支撑判断的数字,有两个方案之间的差异,也有可执行的步骤,模型在组织答案时就有材料可取。
这些内容不必堆成清单。它们要自然地嵌在页面里,让人读起来顺,让模型取起来也顺。
好的 GEO 内容,可能更像一份经过编辑的证据页。它仍然要有人的阅读节奏,但内部有足够多可以被引用的硬块。
相关性藏在标题、开头和子问题里
这套研究里,与 influence_score 相关性最高的独立变量是 llm_relevance_score,相关系数为 0.432。回答与引用页面的 Embedding 相似度是 0.356,LLM 内容质量评分是 0.292,问题与引用页面的 Embedding 相似度是 0.255。
说得更贴近日常工作一点,高影响力页面通常和问题贴得很近。
但这个「贴近」并不等同于关键词出现。
比如用户问「AI 搜索会优先引用什么内容」。有些页面标题写得很大,像「AI 正在改变世界」。它谈的是 AI,也许文字不错,品牌也不差。但模型在寻找证据时,很难把它直接放进这个问题的答案里。
另一个页面的标题是「AI 搜索会优先引用什么内容:基于 23745 条引用记录的结构分析」。开头就给出研究对象、样本规模和核心发现。后面的 H2 又分别处理来源类型、页面结构、语义相关性和内容体裁。
模型面对这两个页面时,第二个页面更像一块可以直接搬进答案里的材料。
未来做内容,不能只停留在关键词表。内容负责人需要把一个商业问题拆成一组用户会问的子问题。标题先把问题圈住,开头交代这页到底回答什么,后面的段落再一层层接住追问。数据和例子不要孤零零地摆在页面中间,它们要出现在模型最可能需要证据的位置。
如果这几层之间断开,页面就会出现一种常见尴尬:人能读懂大概意思,模型也能识别主题,却没有足够明确的片段可用。
把研究放回内容生产现场
如果一家内容团队要用这套研究,不需要一开始就改完整个站点。
更现实的做法,是先打开自己的关键词表和转化路径,挑出一批有商业意图的问题。它们往往和购买、选择、比较、替代、风险、方法、评估有关。泛泛的行业科普可以做,但优先级未必最高。
接着,为这些问题准备真正的证据页。
证据页不只是长文。它需要有清楚定义,有可验证的数据,有对比,有使用边界,有操作步骤,也有来源说明。页面长度最好不要太短。按照这套数据,1000 到 3000 词的页面已经明显优于短内容,3000 词以上仍然更强,只是制作成本也会上去。
这时,内容负责人可以先盯住十几个关键问题,把页面做得足够厚,短文的数量反而可以往后放。
再往外看,还要考虑发布位置。
官网页面、行业垂直媒体、权威目录、新闻稿、研究报告、公开文档,这些都可能成为 AI 搜索的候选来源。对出海项目来说,英文内容和 US 信息网络里的可见度,仍然很重要。
一个小站如果只在自己站内优化页面,外部没有任何信号,结果通常不会太乐观。它面对的是整个公共资料层。大媒体、官方文档、百科页面、论坛讨论、行业报告,都可能站在同一个候选池里。
这不等于小团队没有机会。
相反,小团队更需要把内容做得具体。大站可以靠权威进入候选池,小站则要靠题目更准、证据更实、场景更窄、更新更快,争取在某些细分问题里留下可用材料。
这里没有太多捷径。
但有些坑可以少踩。
这套研究的边界
这套实验值得看,也需要克制使用。
它更像一次静态研究快照。仓库里没有统一采集时间戳;ChatGPT 搜索层覆盖 587 个 Prompt,仍缺 15 个 Prompt 输出;国家、语言、网站类型字段里存在 unknown、WW 以及少量噪声值。
influence_score 也是人为构建的指标。它有解释力,但不能当成模型内部真实权重。相关系数提供的是观察线索,还没有到因果证明那一步。
平台行为还会继续变化。今天 ChatGPT 对来源使用得更深,明天可能换一套搜索策略;Google AI Overview 和 Perplexity 也会继续调整界面、来源展示和回答方式。现在看到的引用形态,很可能被下一轮产品设计改写。
所以,这套研究不适合作为照抄指南。更合适的用法,是把它当作一个拆解框架。
它提醒我们观察三件事:AI 是否搜索,AI 选择谁,AI 用了多少。
这三个问题放在一起,才接近 GEO 的实务现场。
一个比较稳的阶段判断
写到这里,可以把话收回来。
GEO 仍然站在 SEO 的地基上。网页索引、域名权威、内容结构、外部引用、语言生态,这些东西没有消失。变化发生在答案层:内容的价值有时不再通过点击体现,而是通过模型生成答案时的引用和改写体现。
这会让内容效果更难测量。
一个页面可能没有获得点击,却影响了用户对某个问题的理解。另一个页面出现在来源列表里,却没有被答案真正使用。过去的点击率和排名,解释不了这些情况。
对普通内容团队来说,比较稳妥的动作并不复杂。
先打牢 SEO 基本功,让页面能被稳定发现。再围绕核心商业问题,建设更像证据资产的内容。然后持续观察 ChatGPT、Google AI Overview、Perplexity 如何引用自己和竞争对手。
GEO 值得提前布局,但它不会奖励偷懒。
它更可能奖励长期积累出的可信度,以及那些能被模型低成本理解、切分和复用的信息结构。
AI 没有凭空发明一套新的信任系统。它把旧的信息世界重新压缩、重排、改写,然后呈现在答案里。
谁能成为这套重排系统里的稳定证据,谁就更有机会在下一轮内容竞争里占到位置。
至于怎么把自己的行业关键词、竞品页面、Prompt 集合,做成一套持续监测系统。
那是另一个话题。
这篇先停在这里:GEO 的工作重心,不应只放在讨好模型上。更稳的方向,是把内容做成可信、贴题、可引用、可吸收的证据资产。
这个基本功,绕不过去。
