Tech Strategy Review | Vol. 2025
Google 掀翻了 RAG 的桌子:
Gemini File Search 深度拆解与经济学算计
文 / 果叔 · 阅读时间 / 16 Min · 最后更新 / 2025-11-25
写在前面 🧭
过去两年,RAG 系统的工程与认知开销持续走高。Gemini File Search 以“托管式非参数记忆”的方式,将 ETL、索引与检索逻辑下沉到服务端,试图一次性减少熵增与维护复杂度。
本文围绕架构范式、技术细节、成本模型与竞品对标四个维度,给出产品与工程视角的可执行理解框架与取舍建议。
本文核心看点 / Highlights
- 01
范式转移:从“搭积木的 RAG”到托管式 Managed RAG。
- 02
技术壁垒:原生多模态摄取与可控分块、溯源元数据。
- 03
经济学:索引按量计费、存储与查询嵌入免费、Context Caching。
- 04
竞品对标:延迟模型与吞吐性价比,OpenAI vs. Google。
01
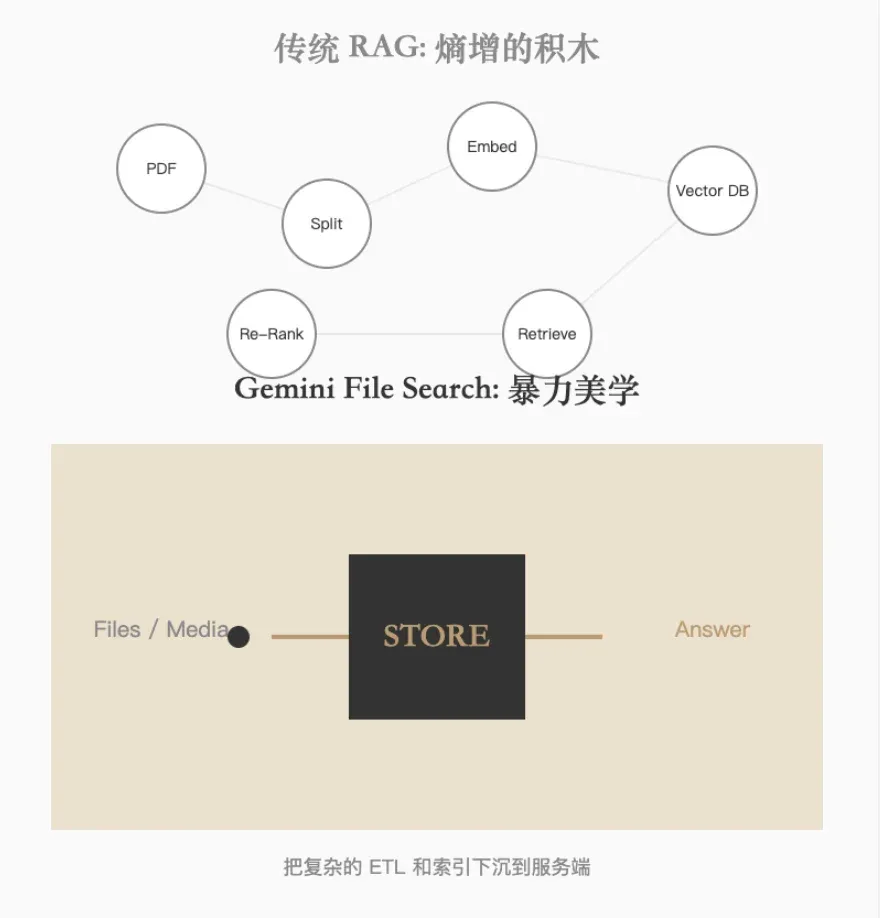
写在前面:熵增的 RAG 架构
你好,我是果叔。我们像是陷入了一种西西弗斯式的循环:为了让 AI 读懂私有数据,需要 PDF 拆分、窗口选择、嵌入向量、维护向量库与相似度检索,最终再把结果塞回 Prompt。这不仅是工程开销,更是认知熵增。Gemini File Search 试图用“暴力美学”把这张桌子掀了。
就如我之前写过的文章:RAG 已死?Claude 核心开发者提出智能体式检索 的核心观点,我个人在实际应用中非常不喜欢使用RAG,包括各种流行的所谓本地知识库。
这不仅是工程上的额外开销,更是认知熵增,这种麻烦的要死还要调整切片的逻辑真的一点也不简洁优雅。
现在Gemini File Search 试图用“暴力美学”把这张桌子掀了。
02
范式转移:Google 的“核选项”
传统 RAG 开发是在搭积木,而 Gemini File Search 更像一个黑盒:你往里扔文件,它吐出答案。这标志着从纯参数记忆到托管式非参数记忆(Managed RAG)的跃迁。
Google 定义了新的实体对象 File Search Store——一个持久化、自带算力的知识容器。它让向量索引与检索逻辑下沉为模型 Tool,简化状态管理并提升查询的自适应性。
-
状态管理简化:Store 成为单一事实来源,避免本地索引不同步。
-
检索下沉:模型自行决定检索与重写查询,减少客户端复杂度。
03
管道深潜:多模态原生的技术壁垒
Gemini File Search 的护城河在于原生多模态摄取能力与极客级分块控制。它支持直接索引视频与音频,并在多模态向量空间中检索,不再依赖纯文本管线。
-
视频/音频原生索引:多模态空间检索,支持对表情、语气等非文本特征的问题。
-
分块控制:
chunking\_config支持max\_tokens\_per\_chunk与max\_overlap\_tokens精细化设置。 -
溯源元数据:响应包含
grounding\_metadata,精确标注来源页与段落,满足合规审计。
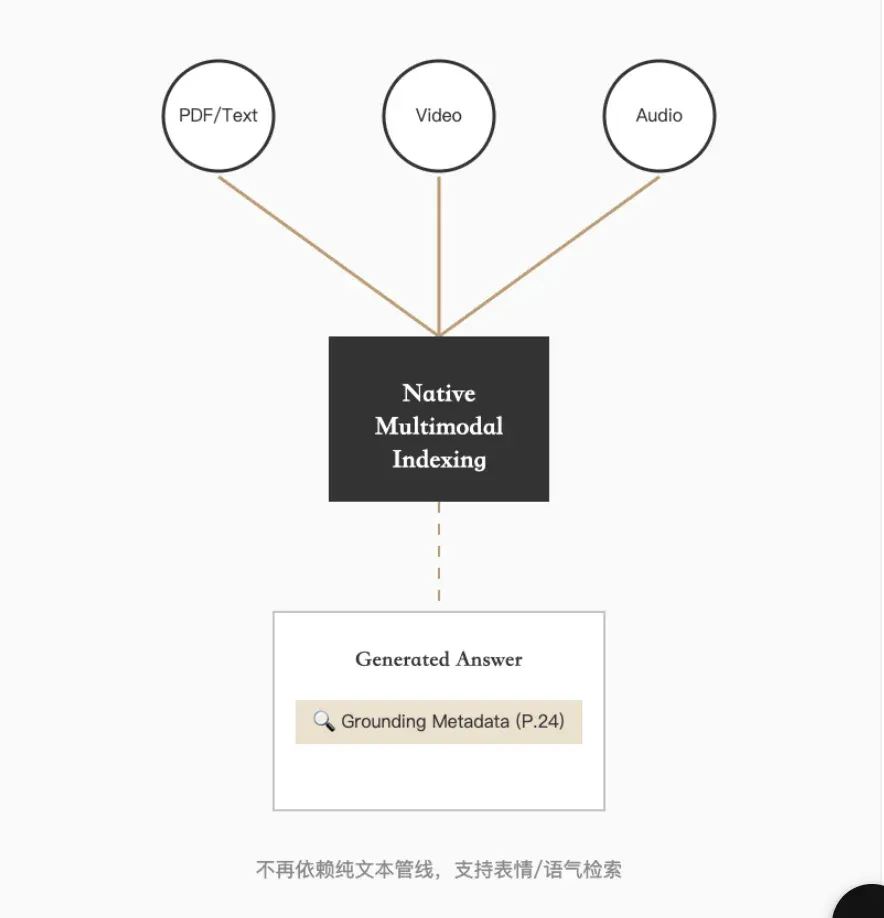
“这是企业级应用最看重的功能:没有溯源,RAG 就是玩具。”
04
经济学推演:免费存储背后的阳谋
成本对比
传统 RAG 成本包含嵌入、向量存储与推理输入;Gemini 将存储与查询时嵌入成本归零,仅对索引与推理输入计费。
传统 RAG
嵌入 API 按 Token 计费;向量数据库存储费(按月/Pod)昂贵;查询推理输入费。
Gemini File Search
索引费:$0.15 / 100万 Tokens(一次性);存储免费;查询嵌入免费;仅推理输入费。
Context Caching
高频场景可付费缓存长上下文,后续输入费用显著下降(最高降幅约 90%),适合客服机器人与 Agent 场景。

05
竞品对标:Gemini vs. OpenAI
-
延迟与交互:OpenAI Assistants 使用异步轮询;Gemini 同步生成,结合 Flash 模型首字延迟更优。
-
文件处理:OpenAI 单文件上限约 512MB;Gemini Files API 单文件可达 5GB,适合视频与大型数据集。
-
推理与吞吐:复杂推理上 OpenAI 略优;大数据吞吐与性价比方面 Google 更符合企业需求。

结语:向量层的商品化
Gemini File Search 的出现宣告了“向量层”的商品化。底层索引细节逐步封装进基础设施,应用开发的壁垒回归到数据质量与场景理解。当记忆极其廉价且唾手可得时,Reasoning 的价值才真正显现。
觉得本文有价值?点个「👍」,转发给正在为 RAG 架构头秃的 CTO 朋友吧。
