这两年我们聊 AI 对互联网的影响,最常见的讨论有两条线。
一条线是内容侧:搜索会不会被改写,SEO 要不要变成 GEO,网站会不会被答案引擎抽干点击。另一条线是产品侧:WebApp 要不要接 MCP,要不要做 agent,要不要给用户一个 AI 入口。
但最近 Google 在推的 WebMCP,把这两条线第一次拧到了一起。
它真正有意思的地方,不在“又多了一个协议名词”,而在于它把网页的角色往前推了一步。过去网页更像是被浏览、被索引、被点击、被抓取的对象。WebMCP 想做的,是让网页开始主动向 AI 暴露“我有哪些工具、你该怎么调用、什么地方适合交给机器做”,也就是把 Web 从内容容器,往“可操作能力层”方向推。
如果这条路走通,受影响的不会只是浏览器团队。SEO、GEO、SaaS、PLG、WebApp 的产品设计、增长策略、信息架构,都会一起变。
我下面想重点回答六个问题:
WebMCP 到底是什么,和传统 MCP 差在哪。
Google 为什么现在推它。
它对 SEO/GEO 会带来什么结构性变化。
SEO 从业人员接下来该怎么做。
PLG 驱动的 WebApp 应该怎么开始变成 AI 友好型产品。
这件事未来两年最值得盯的信号是什么。
先把结论说在前面
我先把我的判断写前面,避免后面讲得太长你抓不住主线。
我觉得 WebMCP 不该被看成浏览器圈子里的一个小实验,也不只是“给网页多加一个 AI 接口”。它更像是 Web 世界给 agent 时代补的一块基础设施:让网站不只被 AI 读取,还能被 AI 在前端安全、结构化、可控地调用。
一旦这件事逐步成立,Web 的竞争逻辑会从“谁更容易被找到”,往“谁更容易被 AI 正确调用”继续移动。
这意味着:
对 SEO 而言,页面未来不只是回答问题,还要提供可被 agent 使用的能力入口。
对 GEO 而言,引用资格会继续重要,但“可调用资格”会变成新的层级。
对 WebApp 而言,前端功能设计、状态管理、权限边界、信息架构,会第一次需要从“agent 怎么安全调用我”这个角度来重写。
WebMCP 到底是什么
先把定义说人话一点。
WebMCP 的官方思路,是在浏览器环境里给网页一套标准化接口,让网站开发者能把自己网页里的某些功能,注册成 AI agent 可调用的“工具”。这些工具不是后台 MCP server 提供的远端能力,而是直接由网页本身的 JavaScript 暴露出来。
官方规范页在最开头就写得很直接:WebMCP API enables web applications to provide JavaScript-based tools to AI agents.换成更好懂的话,就是网页可以自己说:“我这里有几个能力,AI 如果要帮用户完成任务,可以别瞎点 DOM,直接按我定义好的工具来调。”

上面这张图里最值得看的不是标题,而是两行关键信息:
它现在还是 Draft Community Group Report,说明它还不是已经拍板的 W3C 正式标准。
规范编辑来自 Microsoft 和 Google,这说明它不是某一家浏览器厂商在做单点自嗨,而是在尝试把这件事往更广的 Web 共识上推。
来源: https://webmachinelearning.github.io/webmcp/
如果再往下看规范正文,它对 WebMCP 的定义更明确:网页可以被视作一种 MCP server,只不过这些工具不是跑在后端,而是由 client-side script 在前端实现。这个定义非常关键,因为它直接告诉我们 WebMCP 想补的重点在“能力暴露”,不是停留在“内容发现”这一层。
换句话说,传统网站对 AI 的默认关系是:
AI 来读我
AI 来总结我
AI 来引用我
WebMCP 试图增加一层新的关系:
AI 可以调用我
这就是我觉得它重要的原因。因为这意味着网页未来不只是一段被理解的文本,也可能是一块被触发的能力。
它和传统 MCP、DOM 自动化、浏览器插件有什么区别
如果只说“网页给 AI 提供工具”,很多人第一反应会是:这不就是 MCP 吗?或者说,这不就是让 agent 去点网页、填表单、操作按钮吗?
其实不是一回事。
1. 它和后端 MCP 的区别
传统 MCP 更像后端世界的接线协议。你要把工具接给 ChatGPT、Claude、Copilot 这类 agent,通常得在服务端起一个 MCP server,然后让 agent 平台和你的后端对接。
这条路的问题是,对很多 Web 团队来说,成本并不低。因为你的产品能力很多时候已经写在前端了,状态、交互、权限、界面语义、即时上下文,都在浏览器里。结果你为了给 agent 暴露能力,又要在后端重搭一套接口层。
WebMCP 的野心,是让这件事不用重新翻修:网页直接把已有能力以标准方式暴露出来,AI 在浏览器环境里按结构化接口调用,团队也不用再额外维护一套平行的 backend integration。
GitHub 上这个仓库的 README 其实把话讲得更白。它把 WebMCP 描述成:让网页以 JavaScript 工具的形式,把能力交给 AI agents 和 assistive technologies,用于建立 collaborative, human-in-the-loop workflows。
这张 README 图里,有几个点非常值钱:
它明确写了 human-in-the-loop,不是“全权代理”,而是“用户、网页、agent 共用一个工作面板”。
它把 OpenAI、Claude、Gemini 都点名成目标 AI platform,说明它希望自己是一层通用桥,而不是专门给某一个模型准备的私有接口。
它强调“leveraging existing application logic while maintaining shared context and user control”,也就是复用现有前端逻辑、保留共享上下文、保留用户控制。
来源: https://github.com/webmachinelearning/webmcp
2. 它和 DOM 自动化的区别
过去很多 agent 操作网页,本质上还是在“看页面 + 猜按钮 + 模拟点击”。这条路当然能跑,但问题很多:
慢
脆
容易误解页面结构
很依赖视觉布局和元素命名
一改版就可能失效
Chrome 官方那篇早期预览公告里有一句话很关键:WebMCP 提供的是 structured tools,目标是让 agent 在你的网站上执行动作时,更快、更稳、更准。这等于承认了一件事:DOM actuation 这条路虽然可用,但长期看不够工业化。
官方还把 WebMCP 拆成两层:
Declarative API
:适合表单类、标准动作类能力
Imperative API
:适合更复杂、动态、需要 JS 执行的能力
这个分层本身就说明,Google 想解决的不只是“让 AI 能点网页”,而是“让 AI 有一条比点网页更像正式接口的路径”。
来源: https://developer.chrome.com/blog/webmcp-epp
3. 它和浏览器插件/扩展的区别
浏览器插件也能给网页加 agent 能力,但插件的视角通常是“我从外部接管你这个页面”。WebMCP 反过来,是页面自己声明“我愿意以什么方式被调用”。
这个差异会直接影响两个维度:
权限边界谁定义
产品语义谁定义
插件或外部 agent 更像旁观者在猜。WebMCP 更像站点自己递出一份操作手册。
来源(Chrome for Developers): https://developer.chrome.com/blog/webmcp-epp
这件事对 SEO/GEO 的意义特别大,因为它把“可理解性”从内容层推进到了操作层。
Google 为什么现在推这个标准
如果只看技术表面,你会觉得这是浏览器在给 agent 补接口。
但我觉得它出现的时间点,比接口本身更值得读。
1. Google 需要一种更像 Web 标准的 agent 接入方式
这两年 AI 平台已经把“接外部工具”证明成了刚需。问题是,当前生态太碎:
有 MCP
有 OpenAPI
有私有集成
有插件
有爬虫式自动化
有浏览器代理自己瞎摸 DOM
这些方式都能工作,但没有哪一条真正属于 Web 平台本身。
Google 当然不希望未来的 agent 时代里,网页只是被外部 AI 平台随意接管的对象。它更希望浏览器在中间扮演一个更强的、可标准化的调度角色。WebMCP 就是在这个背景下出现的:它想把“网页如何把能力暴露给 agent”这件事,重新纳入 Web 标准语境,同时又能和现有 MCP 生态一起工作。
2. 它符合 Google 一直想推进的“浏览器内 AI”路线
如果你把 WebMCP 和这两年 Chrome / Gemini 的方向放在一起看,会发现这不是孤点:
浏览器想拥有自己的 agent
浏览器想理解页面语义
浏览器想成为用户和网站之间的主动协调层
WebMCP 刚好填了中间这一块:如果浏览器里已经有 agent,那网页应该怎么把能力交给它?
这件事一旦做成,Chrome 不只是“打开网页的容器”,而会更像“调度网页能力给 agent 的操作系统外壳”。
3. 它也符合更广义的无障碍与协作逻辑
WebMCP 在官方文档里反复提到一个容易被忽略的群体:assistive technologies。
这不是客套。因为很多辅助技术面对的难题,和 agent 其实很像:都需要理解网页结构、知道哪里能操作、如何更稳定地完成任务。
所以这件事并不只是为 AI 平台服务。它还在争取一个更大的合法性基础:如果网页能向辅助技术和 agent 同时暴露高层语义化动作,那这套接口在 Web 世界里的正当性就比“单纯讨好大模型”强得多。
这也是为什么我很在意这份 Charter。
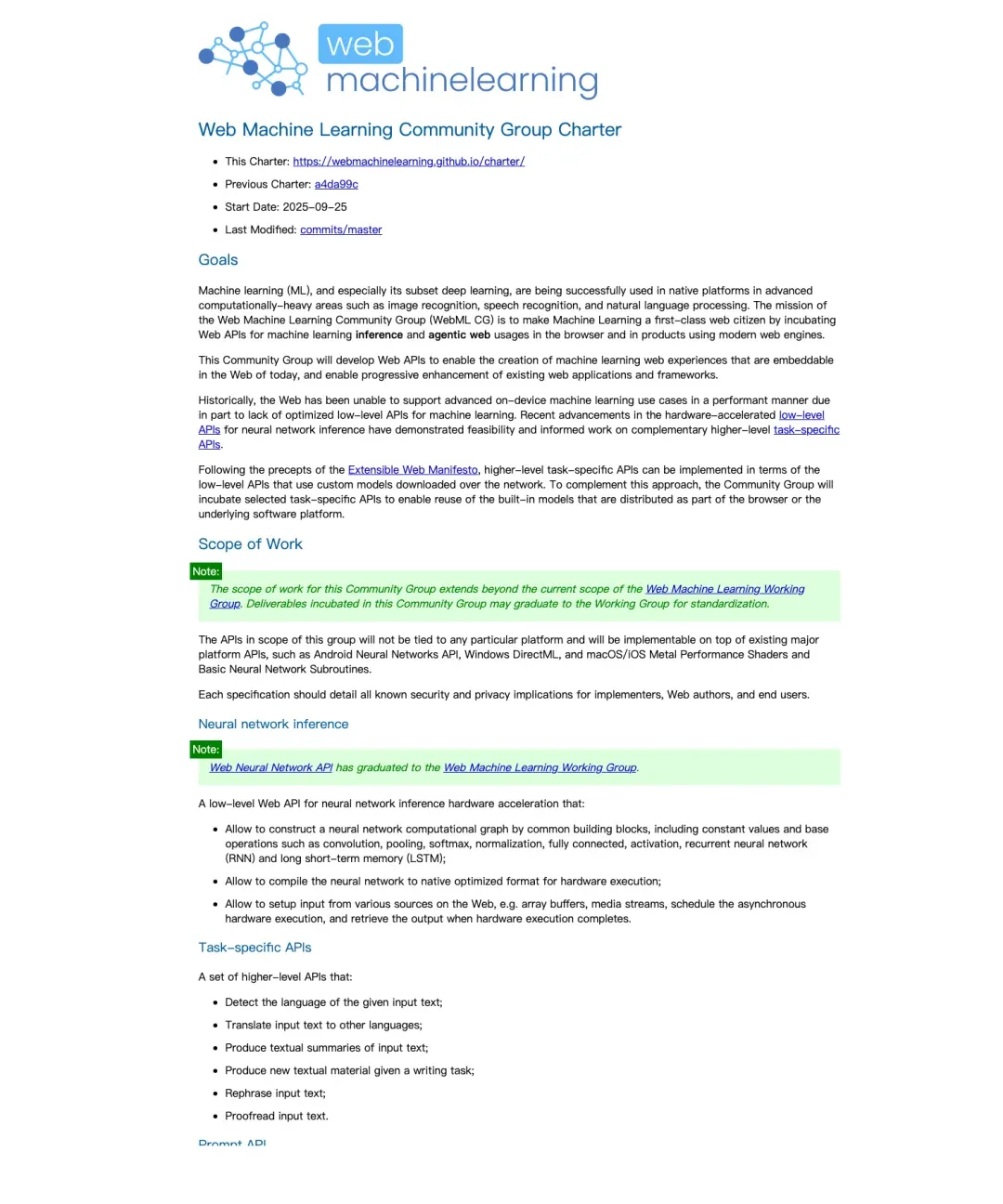
这张图里有一段很关键:Web Machine Learning Community Group 的 scope 明确说,工作范围会超出当前 Working Group 的边界,可交付内容未来可能升级为更正式的标准工作。它还明确写到这些 API 不会绑定某个特定平台。
来源: https://webmachinelearning.github.io/charter/
这说明 WebMCP 不是一个“Chrome 私货命名”。它从一开始就奔着标准化路线去,离大规模落地当然还有距离,但方向已经很清楚了。
它会怎么改写 SEO / GEO
这一部分是我最想展开的。
因为如果你只把 WebMCP 看成开发者接口,那会低估它对搜索和可见度体系的冲击。
1. SEO 的竞争对象会从“页面”继续向“能力”迁移
过去 SEO 的基本单位是 URL。
后面 GEO 的竞争单位开始变成“段落、观点、实体、定义句”。
WebMCP 往前再推一步,它会让竞争单位进一步变成:页面背后到底暴露了什么可调用能力。
什么意思?
如果未来 agent 能在浏览器里更稳定地调用网站工具,那很多 Web 产品的胜负就不再只取决于:
谁内容解释得更清楚
谁页面排得更靠前
谁 schema 更完整
还会取决于:
谁能更早把关键能力做成 agent-friendly tool
谁让 agent 更容易完成任务闭环
谁能减少 agent 与网页之间的歧义和失败率
到那时,所谓“AI 友好”就不会只是一篇文章写得像 FAQ,而会变成整个产品的信息架构和能力接口是否易于 agent 使用。
2. GEO 会从“被引用优化”进入“被调用优化”
这件事对 GEO 的影响尤其大。
现在很多人在谈 GEO,主要还是围绕这些动作:
让 AI 提到你
让 AI 引用你
让 AI 用你的页面作为事实源
这些事情依然重要,但 WebMCP 让人不得不再往前想一步:
如果未来 AI 不只读你、引你,还能调你的网站工具,那 GEO 的目标函数就会变。
以后一个品牌在 AI 世界里的竞争,可能会同时有三层:
可见度
:AI 有没有提到你
可信度
:AI 引用你时,语义是否稳定
可调用度
:AI 能不能直接在你的网页能力上完成动作
这第三层,就是今天很多 SEO 团队还没开始认真想的。
3. “从答案页到动作页”的迁移,会压缩一部分传统点击逻辑
如果网页开始能向 agent 暴露能力,那很多用户旅程会继续缩短。
过去可能是:
用户搜
点进页面
自己找功能
自己操作
未来更可能变成:
用户提目标
agent 找到合适页面
直接调用页面声明好的能力
用户只做确认
这会带来一个很现实的后果:有些页面未来拿到的价值,不再主要来自“页面浏览”,而来自“动作被触发”。
对 SEO 和增长团队来说,这意味着流量归因、内容价值评估、页面设计目标,都要开始变。
4. 可操作页面会变成 AI 搜索时代的新高价值资产
我觉得未来两三年里,真正会吃到 WebMCP 红利的,不会是资讯站,而是那些本来就具备明确任务型能力的 WebApp:
booking
support
e-commerce configurator
dashboard
project tools
design tools
form-heavy workflows
因为它们天然就有“可被调用”的动作闭环。
这也是为什么我会说,WebMCP 对 GEO 的影响,不只是搜索行业内卷升级,而是把搜索和产品能力真正拧到一起了。
SEO 从业人员应该怎么做
如果你是 SEO 从业者,我觉得现在最该做的,不是急着学 API 语法,先把观察框架换掉更重要。
1. 开始把页面分成“内容资产”和“能力资产”
并不是每个页面都适合 WebMCP。
内容页的重点还是可解释、可引用、可抽取。
能力页的重点则要往另一个方向走:可理解、可调用、可确认、可回滚。
所以第一步,不该急着上技术接入,先盘站点:
哪些页面主要提供信息
哪些页面其实在承载任务
哪些任务本来就适合 agent 协助完成
如果你连这张图还没画出来,后面讨论 WebMCP 只会停在热闹层。
2. 把“任务语义”补进信息架构
很多网站的 IA 是给人看的,agent 读起来却未必顺手。
按钮文案含糊、状态切换依赖视觉、表单项只有业务黑话、成功条件写在脑补里,这些问题在人用的时候能勉强过,给 agent 用时就会非常痛苦。
如果 WebMCP 真的往前走,SEO 团队要开始和产品、前端一起盯一种新的语义问题:页面到底有没有把“可执行动作”说清楚。
这会体现在很多细节上:
操作名称是不是足够清楚
输入参数能不能被结构化理解
页面状态是不是易于确认
成功 / 失败 / 回滚条件是不是明确
这些东西过去看起来像 UX 或前端细节,后面会越来越像 AI 可见度工程的一部分。
3. 把 GEO 从“文案优化”升级成“站点能力优化”
如果你还把 GEO 理解成“多写点对 AI 友好的句子”,那很快会不够。
未来更有价值的 GEO 工作,很可能是三件事一起做:
让 AI 容易理解你
让 AI 容易引用你
让 AI 容易调用你
而第三件事,会迫使 SEO 从业者比过去更深入地碰产品和系统。
PLG 驱动的 WebApp,应该怎么做 AI 友好型产品
这一段我觉得对做 SaaS、工具产品、PLG WebApp 的团队特别重要。
因为 WebMCP 真正击中的,更多是那些依赖产品自传播、自体验、自转化的 WebApp,而不是纯内容站。
1. 先别急着“接 agent”,先把能力拆成可声明的动作
很多产品团队现在一看到 agent,就想上聊天框、上自动化、上指挥台。
但如果底层动作本身没有被拆干净,前面那层 agent UI 只会变成一个很脆的壳。
更稳的做法是先问:
产品里哪些动作最高频
哪些动作最标准
哪些动作最适合代理执行但仍需要用户确认
把这些动作先内部结构化,未来不管是接 WebMCP、接自家 agent,还是接第三方平台,都会顺很多。
2. “共享上下文 + 用户控制”会是 WebApp 的竞争分水岭
WebMCP 官方反复强调 shared context 和 user control。我觉得这两个词不是规范修辞,它们就是很现实的产品竞争点。
因为在 WebApp 场景里,用户通常不希望 agent 完全黑盒地替自己做事。用户更愿意接受的是:
你先帮我做一半
你给我一个清晰的确认点
我知道你改了什么
我可以撤回
谁能把这套人机协作体验设计得自然,谁就更容易把 agent 真的变成增长工具,而不是 demo。
3. PLG 产品要开始把“agent onboarding”当成新层级
过去 PLG 的 onboarding 是给人设计的。
未来会多一层:给 agent 设计 onboarding。
这里当然不只是做一个“AI 欢迎页”就行,你要先想清楚:
agent 第一次进来时,哪里能看懂产品能力
哪些动作是安全可试的
哪里最容易踩权限坑
哪些关键状态需要明确暴露
如果用户是通过 agent 进入你的产品,你的“首屏体验”就不再只是视觉体验,也包括 agent 能否顺利完成第一步动作。
我对未来两年的判断
我最后把判断压成五条,方便你回头复盘。
1. WebMCP 今年还不会立刻全面落地,但方向已经够明确
它现在还是 Community Group Draft,也还在 early preview 阶段。
所以别把它当成明天全行业必须上线的东西。
但也别把它当成玩具,因为它解决的问题是真问题,而且方向和浏览器内 agent 的长期演进是对齐的。
2. “可调用资格”会成为继“可见资格”之后的新层级
过去网站争的是能不能被搜到。
后来争的是能不能被 AI 引到。
下一步更可能争的是:能不能被 AI 直接、安全、稳定地调用。
3. SEO 团队会越来越像“内容 + 产品 + 语义系统”的混合岗位
如果 WebMCP 继续推进,SEO 不会消失,但它会更深入产品层。
未来真正稀缺的人,可能不会是最会堆关键词的人,而会是最能把页面、能力、语义、引用资格和任务入口一起看懂的人。
4. PLG WebApp 会迎来一轮“AI 友好型重构”
以前 PLG 产品拼的是首屏价值、激活路径、功能扩散。
后面会再多一层:agent 能不能快速理解并参与这条路径。
这层如果做得好,增长会更顺;做不好,产品会在 AI 入口时代显得很笨重。
5. 先理解,再下注
我并不建议大家现在就为了追热点去做一套半吊子 WebMCP demo。
更值得做的是先把认知搭起来,再看自己到底是哪类站点、哪类产品、哪类场景最先会受影响。
如果你是内容站,先盯“被引用资格”。
如果你是 WebApp,开始盘“可暴露动作”。
如果你是 SEO / GEO 团队,尽早把“可调用度”加进你的未来观察框架。
这篇文章如果只想留下一个结论,我希望你记住的是:
WebMCP 把网页从“被理解的对象”,往“可合作的工具”推了一步。
这一步如果走实,Web 的下一轮竞争就不会只发生在内容页,也会发生在动作层、能力层和协作层。
