全文字数:约 2100 字
预计阅读时间:约 15 分钟
最后更新日期:2025年08月18日
本文核心看点
✅ 深度解读 NVIDIA 最新论文,挑战“模型越大越好”的行业定势。
✅ 为什么说小模型 (SLM) 在成本、效率和架构上更适合 AI Agent?
✅ 探索 LLM (CEO) + SLM (专家) 的“异构混合”新范式。
✅ 一套可直接复用的“LLM-to-SLM” Agent 改造路线图。
深度解读NVIDIA雄文:Agent的未来,属于小模型 (SLM)
1. 写在前面:一场AI领域的“哥白尼式革命”
你好,我是果叔。在 Agentic AI 领域,一场关于模型规模的“军备竞赛”正进行得如火如荼。行业巨头们似乎都默认了一个信条:模型越大,能力越强,Agent 就越智能。然而,就在此时,NVIDIA 却发表了一篇极具颠覆性的立场文件,标题直截了当——《Small Language Models are the Future of Agentic AI》。
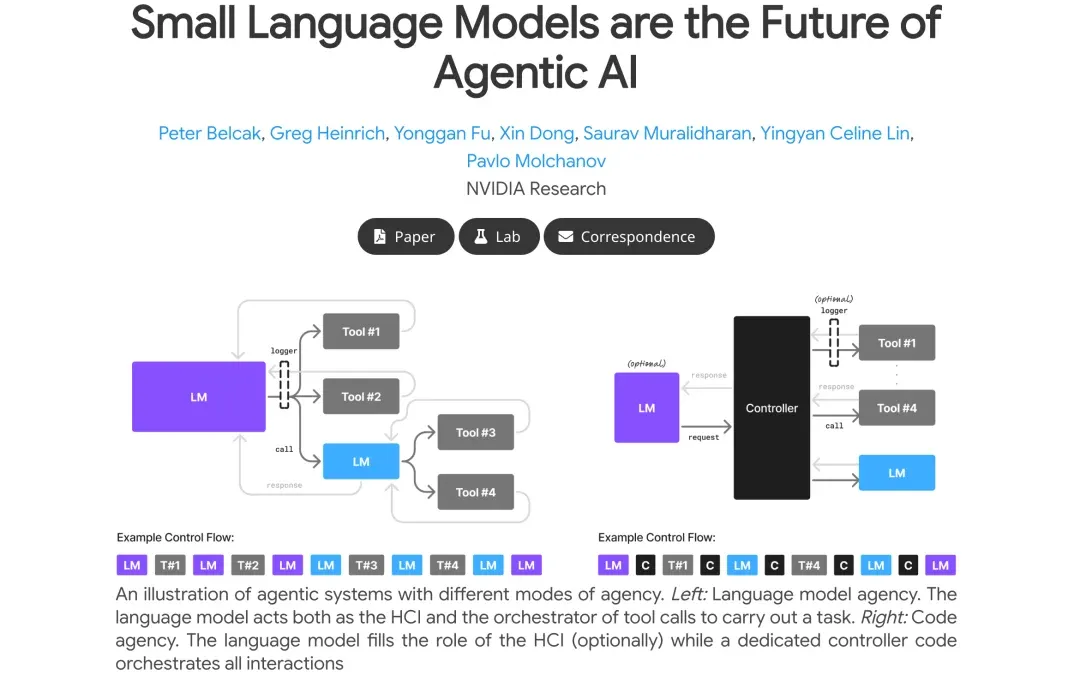
这篇论文,无异于在“地心说”盛行的时代,有人冷静地指出“日心说”的可能性。它迫使我们重新思考一个根本问题:为了完成高度专业化、重复性的 Agent 任务,我们真的需要动用一个能写诗、能聊哲学的“通才”大模型吗?这是否是一种巨大的资源错配?今天,我将带你深入解读这篇雄文,看看为什么说 Agent 的未来,属于小而美的 SLM。
原论文链接:
2. 核心论证:为什么 SLM 才是 Agent 的“天选之子”?
NVIDIA 的论证并非空谈,而是建立在三大坚实的支柱之上,层层递进,极具说服力。
论点一 (V1): 能力已达标,SLM 不再是“吴下阿蒙”
过去的观念认为 SLM 能力有限,但论文引用了大量案例(如 Microsoft Phi-3, NVIDIA Nemotron-H 等)证明,经过精心设计和训练的现代 SLM,在常识推理、工具调用和代码生成等 Agent 核心能力上,已经可以媲美甚至超越数倍于其规模的 LLM。一言以蔽之,SLM 的能力已越过“可用”的门槛,进入“好用”的阶段。
论点二 (V2): 架构的天然契合
AI Agent 的本质,是通过一系列工具调用和逻辑编排来完成特定任务。这意味着它的大部分工作是高度结构化、格式要求严格的。在这种场景下,一个经过专门微调、行为高度可预测的 SLM,远比一个行为范式宽泛、偶尔会“自由发挥”的 LLM 更可靠、更易于集成。这恰好印证了我们之前在“微型Agent”一文中的观点:将AI“降级”为可靠的、负责特定任务的“智能节点”,是通往生产级应用的必经之路。
论点三 (V3): 成本与效率的“降维打击”
这是 SLM 最具杀伤力的优势。论文从多个维度进行了阐述:
- 推理效率
:服务一个 7B 的 SLM,在延迟、能耗和算力上的成本,比服务 70B+ 的 LLM 低 10-30 倍。这意味着更快的响应速度和更低的运营成本。
- 微调敏捷性
:为一个 SLM 添加新技能或修复 bug,可能只需要几个 GPU 小时,可以做到“一夜之间”完成迭代,而 LLM 则需要数周。
- 边缘部署
:SLM 可以轻松部署在消费级 GPU 甚至手机上,实现离线推理,这为数据隐私和低延迟场景打开了想象空间。
3. 未来图景:构建 LLM (CEO) + SLM (专家) 的“异构混合团队”
NVIDIA 的立场并非要全盘否定 LLM,而是提倡一种更聪明、更高效的架构——异构 Agent 系统 (Heterogeneous Agentic Systems)。
你可以将这种系统想象成一个高效的公司:
- LLM 担任 CEO
:负责顶层战略规划、理解复杂模糊的用户意图、进行开放域的对话和决策。当任务需要强大的通用推理能力时,才调用这位“昂贵的顾问”。
- SLM 担任专家员工
:每个 SLM 都被微调为特定领域的专家,比如“代码生成专员”、“API 调用专员”、“文档摘要专员”等。它们高效、低成本地处理 80% 的日常、重复性工作。
这种“乐高式”的组合,用多个小而专的 SLM “向外扩展”,而非用一个巨大的 LLM “向上扩展”,构建出的 Agent 系统将兼具成本效益与强大的能力。
4. 行动指南:你的 Agent 如何实现“降本增效”?
最难能可贵的是,论文并未停留在理论层面,而是提供了一套清晰的“LLM-to-SLM”转换算法。我将其提炼为一套可操作的路线图:
- 数据收集与埋点 (Secure usage data collection)
:首先,在你的 Agent 调用 LLM 的各个接口(非用户直接交互的内部调用)进行埋点,安全地记录输入提示、输出结果和工具调用内容。
- 数据清洗与脱敏 (Data curation and filtering)
:对收集到的数据进行清洗,移除所有敏感信息 (PII, PHI),确保数据安全。
- 任务聚类与识别 (Task clustering)
:使用无监督聚类等技术,分析收集到的调用数据,识别出高频、重复的任务模式。例如,“生成SQL查询”、“从文本中提取JSON”、“调用天气API”等。
- 选择合适的 SLM (SLM selection)
:为每个识别出的任务,选择一个合适的 SLM 候选模型。考虑其基础能力、性能、许可证和部署要求。
- 微调专家 SLM (Specialized SLM fine-tuning)
:使用对应任务的数据,对选定的 SLM 进行微调(如 LoRA 或 QLoRA),使其成为该任务的“专家”。
- 迭代与优化 (Iteration and refinement)
:将原先调用 LLM 的接口,替换为调用微调好的专家 SLM。持续收集新数据,定期重新微调,形成一个持续改进的闭环。
5. 结语:回归工程理性的 AI 哲学
NVIDIA 的这篇论文,实际上是在呼吁一种 AI 领域的“工程理性回归”。它提醒我们,在追逐星辰大海(AGI)的同时,更要脚踏实地,为特定的问题寻找最优性价比的解决方案。
这篇文章其理念与我之前的一篇文章AI Agent的工程化之路系列(一):AI Agent已死,“Micro Agent”永生?的理念如出一辙,让我更加笃定在短期的未来,大模型+小模型组合式的 Micro Agent 会是最适应时长应用场景的最佳解决方案。
从 LLM-centric 转向 SLM-first,并非技术的倒退,而是一种进化。它意味着我们开始从“有什么用什么”的粗放阶段,迈向“为每个任务匹配最合适工具”的精细化运营阶段。这不仅关乎成本,更关乎效率、可持续性,以及 AI 技术的普惠化。
觉得果叔的解读有启发?点个「在看」,「转发」给更多需要的朋友吧!
关注我的公众号,与你一同探索 AI、出海与数字营销的无限可能。
🌌 最优的解,往往不是最强的,而是最合适的。
