深入解析 OpenCode:下一代 AI 编程助手的架构艺术
写在前面
很久没有来自Tam 同学的技术向文章了,今天来一手~ 懂技术的,学Agent 开发的小伙伴们可以来围观了解一下。OpenCode 是个所谓”开源版Claude Code”,要知道Tam 很早就写过一个系列《跟着Gemini CLI 学Agent 开发》,这次带来的是OpenCode。 文章比较深入,适合耐心多读几遍,并去实操拆解一下OpenCode 源码。
如同我之前所说,我目前日常工作中使用的最多的Agent 工具,不是Manus, 不是Genspark,而是终端中的Claude Code 和Codex,我会自己给他们配置工具,让他们变成我电脑中真正的超级贾维斯。我也一直认为CC和Codex 才是当下这个时代设计最棒的智能体产品。那么分析和学习一下OpenCode,会帮你在开发任何智能体时有一个更好的参考和模板。
以下部分Tam 创作。
引言:当 AI 学会写代码
还记得第一次让 ChatGPT 帮你写代码的感觉吗?那种”哇,这也行?“的惊叹,很快就被”等等,这代码跑不起来啊”的沮丧所取代。
AI 能写代码,但它不能真正地写代码——它不能读取你的文件、不能运行测试、不能理解你项目的上下文。它就像一个被蒙上眼睛、绑住手脚的天才程序员:有能力,但无法施展。
OpenCode 的出现,正是为了解开这些束缚。
┌─────────────────────────────────────────────────────────────────┐
│ │
│ 传统 LLM Chatbot vs OpenCode Agent │
│ │
│ ┌─────────────┐ ┌─────────────────────┐ │
│ │ User │ │ User │ │
│ └──────┬──────┘ └──────────┬──────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌─────────────┐ ┌─────────────────────┐ │
│ │ LLM │ │ Agent │ │
│ │ (黑箱对话) │ │ ┌───────────────┐ │ │
│ └─────────────┘ │ │ 思考 (Think) │ │ │
│ │ │ ├───────────────┤ │ │
│ ▼ │ │ 工具 (Tools) │ │ │
│ ┌─────────────┐ │ │ ├─ Read │ │ │
│ │ 纯文本回复 │ │ │ ├─ Write │ │ │
│ │ (无法执行) │ │ │ ├─ Bash │ │ │
│ └─────────────┘ │ │ ├─ Grep │ │ │
│ │ │ └─ ... │ │ │
│ │ ├───────────────┤ │ │
│ │ │ 执行 (Action) │ │ │
│ │ └───────────────┘ │ │
│ └─────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────┐ │
│ │ 真实的代码修改 │ │
│ │ 可运行的结果 │ │
│ └─────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘OpenCode 是一个开源的 AI 编程助手,但更准确地说,它是一个完整的 Agent 框架。它让 LLM 能够:
- 🔍 阅读你的代码文件
- ✏️ 编辑你的代码
- 🖥️ 执行 shell 命令
- 🔎 搜索代码库
- 🤔 思考并展示推理过程
- 📝 记忆长对话上下文
- 🔄 回滚任何修改
这不是一个简单的 API wrapper,而是一个精心设计的工程艺术品。让我们一起深入它的内部,看看现代 AI Agent 是如何构建的。
第一章:鸟瞰全局 - OpenCode 架构总览
1.1 Monorepo 的选择
OpenCode 采用 Monorepo 架构,使用 Bun 作为运行时和包管理器,Turbo 作为构建编排工具。这个选择并非偶然:
opencode/
├── packages/
│ ├── opencode/ # 核心 CLI 和服务器 (心脏)
│ ├── console/ # Web 管理控制台 (大脑可视化)
│ │ ├── app/ # SolidJS Web UI
│ │ ├── core/ # 后端逻辑
│ │ ├── function/ # Serverless 函数
│ │ └── mail/ # 邮件模板
│ ├── desktop/ # Tauri 桌面应用 (Native 外壳)
│ ├── app/ # 共享 UI 组件 (统一视觉)
│ ├── sdk/js/ # JavaScript SDK (对外接口)
│ ├── ui/ # UI 组件库 (设计系统)
│ ├── plugin/ # 插件系统 (扩展能力)
│ ├── util/ # 共享工具函数 (基础设施)
│ ├── web/ # 文档网站 (知识库)
│ └── identity/ # 身份认证 (安全门户)
├── infra/ # 基础设施即代码 (SST/AWS)
└── sdks/ # SDK 分发为什么是 Monorepo?
想象一下,你正在建造一座现代化的智能大厦:
- CLI 是大厦的电梯系统——用户通过它进入
- Server 是大厦的中央控制室——协调一切
- Desktop 是大厦的豪华门厅——精致的入口
- Web Console 是大厦的监控中心——全局可视
- SDK 是大厦的 API 接口——供外部系统对接
这些组件需要共享代码(UI 组件、工具函数、类型定义),需要同步版本,需要统一构建。Monorepo 让这一切变得优雅。
1.2 技术栈全景

1.3 核心包结构深入
让我们聚焦 packages/opencode——这是整个系统的心脏:
packages/opencode/src/
├── cli/cmd/ # CLI 命令入口 (17+ 命令)
│ ├── run.ts # 主运行命令
│ ├── auth.ts # 认证命令
│ ├── serve.ts # 服务器模式
│ ├── mcp.ts # MCP 服务器
│ └── ...
│
├── agent/ # Agent 系统
│ └── agent.ts # Agent 定义与配置
│
├── session/ # 会话管理 (核心!)
│ ├── index.ts # Session CRUD
│ ├── message-v2.ts # 消息 Schema
│ ├── prompt.ts # 提示词构建 + 主循环
│ ├── processor.ts # 流式处理管道
│ ├── compaction.ts # 上下文压缩
│ ├── summary.ts # 摘要生成
│ ├── llm.ts # LLM 调用接口
│ ├── system.ts # System Prompt 构建
│ ├── revert.ts # 回滚功能
│ ├── status.ts # 状态追踪
│ ├── retry.ts # 重试逻辑
│ └── todo.ts # 任务追踪
│
├── provider/ # LLM Provider 抽象
│ └── provider.ts # 18+ 提供商支持
│
├── tool/ # 工具系统
│ ├── registry.ts # 工具注册表
│ ├── tool.ts # 工具定义接口
│ ├── bash.ts # Shell 执行
│ ├── read.ts # 文件读取
│ ├── write.ts # 文件写入
│ ├── edit.ts # 文件编辑
│ ├── grep.ts # 代码搜索
│ ├── glob.ts # 文件匹配
│ ├── lsp.ts # LSP 集成
│ ├── task.ts # 子任务
│ └── ...
│
├── server/ # HTTP 服务器
│ ├── server.ts # Hono 服务器
│ └── tui.ts # TUI 路由
│
├── mcp/ # Model Context Protocol
├── lsp/ # Language Server Protocol
├── project/ # 项目管理
├── permission/ # 权限系统
├── storage/ # 数据存储
├── bus/ # 事件总线
├── config/ # 配置管理
├── worktree/ # Git Worktree
├── snapshot/ # 文件快照
└── plugin/ # 插件系统这个结构体现了关注点分离的设计哲学:每个目录都有明确的职责,模块之间通过清晰的接口通信。
第二章:会话管理 - AI 的”记忆宫殿”
“记忆是智慧的母亲。” —— 埃斯库罗斯
如果说 LLM 是 Agent 的大脑,那么 Session Management 就是它的记忆系统。没有记忆的 AI,就像患了阿尔茨海默症的天才——每次对话都从零开始。
2.1 会话的数据模型
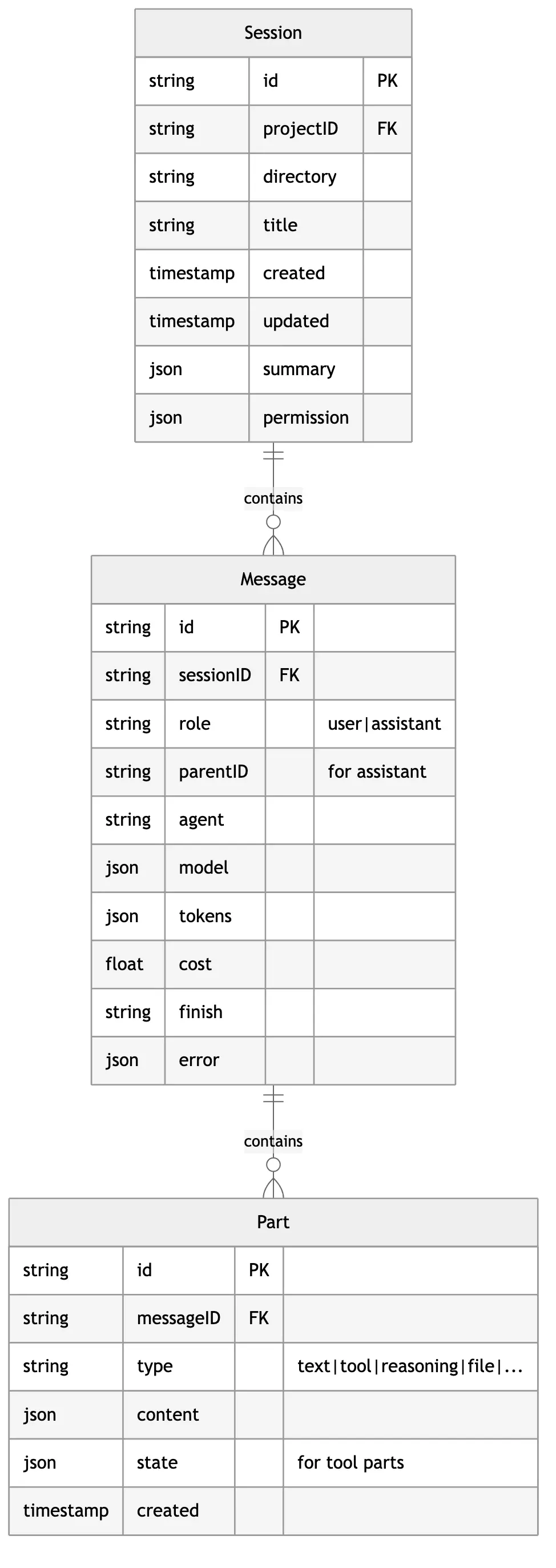
这个三层结构设计得非常精妙:
- Session - 一次完整的任务会话
- Message - 用户或 AI 的一次发言
- Part - 发言中的组成部分(文本、工具调用、思考过程等)
为什么需要 Part 层级?
传统的 chatbot 只有 Message 层级——一条消息就是一段文本。但 AI Agent 的输出要复杂得多:
User: "帮我修复 src/app.ts 的 bug"
Assistant Response:
├─ ReasoningPart: "让我先读取文件看看问题..."
├─ ToolPart: { name: "read", input: {...}, output: "..." }
├─ ReasoningPart: "我发现第 42 行有类型错误..."
├─ ToolPart: { name: "edit", input: {...}, output: "..." }
├─ TextPart: "已修复!问题是..."
└─ PatchPart: { diff: "..." }Part 层级让我们能够:
- 流式更新:每个 Part 可以独立更新,UI 实时刷新
- 状态追踪:工具执行有独立的状态机
- 细粒度存储:只更新变化的部分
- 差异化渲染:思考过程、工具调用、最终回复用不同样式显示
2.2 消息的类型系统
OpenCode 使用 Zod 定义了严格的类型系统:
// 用户消息 Schema
const UserMessage = z.object({
id: z.string(),
sessionID: z.string(),
role: z.literal("user"),
time: z.object({ created: z.number() }),
// AI 配置
agent: z.string(),
model: z.object({
providerID: z.string(),
modelID: z.string(),
}),
// 可选覆盖
system: z.string().optional(), // 自定义 system prompt
tools: z.record(z.boolean()).optional(), // 工具开关
variant: z.string().optional(), // 模型变体
// 摘要信息
summary: z.object({
title: z.string().optional(),
body: z.string().optional(),
diffs: z.array(FileDiff),
}).optional(),
});
// 助手消息 Schema
const AssistantMessage = z.object({
id: z.string(),
sessionID: z.string(),
role: z.literal("assistant"),
parentID: z.string(), // 关联到用户消息
time: z.object({
created: z.number(),
completed: z.number().optional(),
}),
// 模型信息
modelID: z.string(),
providerID: z.string(),
agent: z.string(),
mode: z.string(),
// 执行结果
finish: z.enum(["tool-calls", "stop", "length", "content-filter", "other"]),
error: MessageError.optional(),
// 成本追踪
cost: z.number(),
tokens: z.object({
input: z.number(),
output: z.number(),
reasoning: z.number(),
cache: z.object({ read: z.number(), write: z.number() }),
}),
});finish 字段的智慧
注意 finish 字段的枚举值:
"tool-calls": AI 需要调用工具,循环继续"stop": AI 主动结束,循环终止"length": 输出过长被截断"content-filter": 内容被过滤"other": 其他原因
这个字段是主循环的控制开关——只有当 finish !== "tool-calls" 时,Agent 才会停止工作。
2.3 Part 的类型宇宙
Part 使用 Discriminated Union 模式,这是 TypeScript 类型系统的一个强大特性:
type Part =
| { type: "text"; content: string; }
| { type: "reasoning"; content: string; }
| { type: "tool"; state: ToolState; }
| { type: "file"; source: "file" | "symbol" | "resource"; path: string; content: string; }
| { type: "snapshot"; ref: string; }
| { type: "patch"; diff: string; }
| { type: "step-start"; snapshot: string; }
| { type: "step-finish"; usage: Usage; }
| { type: "agent"; agentID: string; }
| { type: "compaction"; }
| { type: "subtask"; taskID: string; }
| { type: "retry"; attempt: number; };每种类型都有其独特的用途:
| 类型 | 用途 | 示例 |
|---|---|---|
text | AI 的文本回复 | ”我已经修复了这个 bug…” |
reasoning | 思考过程 | ”让我分析一下这个函数…” |
tool | 工具调用 | Read, Write, Bash, Grep… |
file | 文件附件 | 读取的代码文件内容 |
snapshot | Git 快照引用 | 用于回滚 |
patch | 文件变更 | diff 格式的修改 |
step-start/finish | 步骤边界 | 用于计算 token 和成本 |
compaction | 压缩标记 | 标记上下文被压缩 |
subtask | 子任务 | 调用其他 Agent |
retry | 重试元数据 | 记录重试次数 |
2.4 Tool Part 的状态机
工具调用是 Agent 最核心的能力,它的状态管理尤为重要:

状态的数据结构:
type ToolState =
| {
status: "pending";
input: {};
raw: string; // 流式接收的原始 JSON
}
| {
status: "running";
input: Record<string, unknown>;
title?: string;
metadata?: Record<string, unknown>;
time: { start: number };
}
| {
status: "completed";
input: Record<string, unknown>;
output: string;
title: string;
metadata: Record<string, unknown>;
time: { start: number; end: number; compacted?: number };
attachments?: FilePart[];
}
| {
status: "error";
input: Record<string, unknown>;
error: string;
time: { start: number; end: number };
};为什么需要 pending 状态?
当 LLM 决定调用工具时,它会流式输出工具的参数。在参数完整之前,我们只有一个不完整的 JSON 字符串:
接收中: {"file_path": "src/ap
接收中: {"file_path": "src/app.ts", "off
接收中: {"file_path": "src/app.ts", "offset": 0, "limit": 100}pending 状态让我们能够在 UI 上显示”正在准备工具调用…”,而不是等到参数完整才显示。
第三章:Agent 系统 - 思考的艺术
3.1 什么是 Agent?
在 OpenCode 中,Agent 不仅仅是一个 LLM 的包装——它是一个人格化的角色定义。每个 Agent 有自己的:
- System Prompt - 行为指南
- 权限配置 - 能做什么
- 模型参数 - temperature, topP 等
- 步数限制 - 最多执行多少轮
interface AgentInfo {
name: string; // 唯一标识符
mode: "subagent" | "primary" | "all"; // 使用模式
permission?: PermissionRuleset; // 权限规则
prompt?: string; // 自定义 System Prompt
temperature?: number; // 创造性程度
topP?: number; // 采样范围
steps?: number; // 最大步数
}3.2 内置 Agent 图鉴
OpenCode 内置了多个专业化的 Agent:

各 Agent 的职责:
| Agent | 模式 | 职责 | 特点 |
|---|---|---|---|
build | primary | 主要的代码执行 Agent | 原生权限,最常用 |
plan | primary | 规划阶段 Agent | 用于制定实施计划 |
explore | subagent | 代码库探索 | 只读权限,快速搜索 |
general | subagent | 通用多步任务 | 完整权限 |
compaction | hidden | 上下文压缩 | 自动调用,用户不可见 |
title | hidden | 生成会话标题 | 使用小模型,成本低 |
summary | hidden | 生成消息摘要 | 自动总结对话 |
3.3 Explore Agent 的妙用
explore Agent 是一个只读的快速探索者,它的设计体现了”最小权限原则”:
{
name: "explore",
mode: "subagent",
permission: {
// 只允许读取操作
"tool.read": { allow: true },
"tool.glob": { allow: true },
"tool.grep": { allow: true },
// 禁止写入操作
"tool.write": { deny: true },
"tool.edit": { deny: true },
"tool.bash": { deny: true },
},
prompt: `You are a fast codebase explorer. Your job is to quickly
find relevant files and code patterns. You cannot modify anything.`,
steps: 10, // 最多 10 轮,快速完成
}使用场景:
当用户问”这个项目的路由是怎么实现的?“,主 Agent 可以:
- 创建一个
explore子任务 - Explore Agent 快速搜索代码
- 返回结果给主 Agent
- 主 Agent 综合回答
这样的设计有几个好处:
- 安全:探索过程不会意外修改文件
- 高效:explore 有专门优化的 prompt
- 并行:多个探索任务可以并行执行
3.4 Agent 的调用链
User Input: "帮我重构这个函数"
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ Build Agent │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ 思考:我需要先了解这个函数的用途和上下文 │ │
│ └───────────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ 工具调用:Task (创建 explore 子任务) │ │
│ │ { agent: "explore", prompt: "找出所有调用这个函数的地方" } │ │
│ └───────────────────────────────────────────────────────────┘ │
│ │ │
└──────────────────────────────│──────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ Explore Agent │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ 工具:Grep (搜索函数引用) │ │
│ │ 工具:Read (读取相关文件) │ │
│ │ 返回:找到 5 处调用,位于 a.ts, b.ts, c.ts... │ │
│ └───────────────────────────────────────────────────────────┘ │
└──────────────────────────────│──────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ Build Agent (继续) │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ 思考:了解了上下文,现在可以安全地重构 │ │
│ │ 工具:Edit (修改函数) │ │
│ │ 工具:Edit (更新调用处) │ │
│ │ 输出:重构完成,修改了 6 个文件 │ │
│ └───────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘第四章:工具系统 - AI 的”瑞士军刀”
4.1 工具的设计哲学
工具是 Agent 与真实世界交互的桥梁。OpenCode 的工具系统遵循几个设计原则:
- 声明式定义:使用 Zod Schema 定义参数
- 上下文感知:每个工具都能访问会话上下文
- 状态追踪:执行过程实时更新
- 权限控制:每个工具调用都经过权限检查
- 可扩展:支持自定义工具和 MCP 协议
4.2 工具定义接口
// 工具定义接口
Tool.define = (id: string, init: () => ({
description: string; // 给 LLM 看的描述
parameters: ZodSchema; // 参数 Schema
execute: (args: T, ctx: ToolContext) => Promise<ToolResult>;
formatValidationError?: (error: ZodError) => string; // 自定义错误格式
}));
// 工具上下文
interface ToolContext {
sessionID: string;
messageID: string;
agent: string;
abort: AbortSignal; // 用于取消执行
callID: string; // 本次调用的唯一 ID
// 动态方法
metadata(input: object): Promise<void>; // 更新元数据
ask(request: PermissionRequest): Promise<void>; // 请求权限
}
// 工具执行结果
interface ToolResult {
title: string; // 展示给用户的标题
output: string; // 返回给 LLM 的输出
metadata?: Record<string, unknown>; // 额外信息
attachments?: FilePart[]; // 附件(如图片)
}4.3 核心工具详解
Read Tool - 文件读取
Tool.define("read", () => ({
description: `Reads a file from the local filesystem.
- The file_path parameter must be an absolute path
- By default reads up to 2000 lines
- Can read images (PNG, JPG), PDFs, and Jupyter notebooks
- Results use cat -n format with line numbers`,
parameters: z.object({
file_path: z.string().describe("Absolute path to the file"),
offset: z.number().optional().describe("Starting line number"),
limit: z.number().optional().describe("Number of lines to read"),
}),
async execute({ file_path, offset, limit }, ctx) {
// 1. 规范化路径
const normalizedPath = normalizePath(file_path);
// 2. 检查权限
if (isExternalPath(normalizedPath)) {
await ctx.ask({ permission: "read.external", path: normalizedPath });
}
// 3. 检测文件类型
const fileType = detectFileType(normalizedPath);
// 4. 根据类型读取
if (fileType === "image") {
return { title: `Read image`, output: "[Image]", attachments: [...] };
}
if (fileType === "pdf") {
return { title: `Read PDF`, output: extractPdfText(normalizedPath) };
}
// 5. 读取文本文件
const content = await readFile(normalizedPath, { offset, limit });
return {
title: `Read ${basename(normalizedPath)}`,
output: formatWithLineNumbers(content, offset),
metadata: { lines: content.split('\n').length, path: normalizedPath },
};
},
}));Edit Tool - 精确编辑
Edit Tool 是最复杂的工具之一,它实现了精确的字符串替换:
Tool.define("edit", () => ({
description: `Performs exact string replacements in files.
- You must read the file before editing
- old_string must be unique in the file
- Use replace_all for batch replacements`,
parameters: z.object({
file_path: z.string(),
old_string: z.string().describe("Text to replace"),
new_string: z.string().describe("Replacement text"),
replace_all: z.boolean().default(false),
}),
async execute({ file_path, old_string, new_string, replace_all }, ctx) {
// 1. 读取当前内容
const content = await readFile(file_path);
// 2. 验证 old_string 存在且唯一(除非 replace_all)
const occurrences = countOccurrences(content, old_string);
if (occurrences === 0) {
throw new Error(`String not found in file`);
}
if (occurrences > 1 && !replace_all) {
throw new Error(`String appears ${occurrences} times. Use replace_all or provide more context.`);
}
// 3. 执行替换
const newContent = replace_all
? content.replaceAll(old_string, new_string)
: content.replace(old_string, new_string);
// 4. 写入文件
await writeFile(file_path, newContent);
// 5. 生成 diff
const diff = createDiff(content, newContent, file_path);
return {
title: `Edit ${basename(file_path)}`,
output: diff,
metadata: {
replacements: replace_all ? occurrences : 1,
path: file_path,
},
};
},
}));为什么用字符串替换而不是行号?
行号编辑(“修改第 42 行”)看似简单,但有一个致命问题:LLM 数不准行号。
当 AI 说”请看第 42 行”,它可能实际上指的是第 40 行或第 45 行。但字符串匹配是精确的——要么找到,要么找不到。
这种设计还有一个好处:强制 AI 提供上下文。如果替换目标不唯一,AI 必须提供更多周围代码来消歧义,这反而提高了编辑的准确性。
Bash Tool - Shell 执行
Tool.define("bash", () => ({
description: `Executes bash commands with timeout and security measures.
- Avoid file operations, use dedicated tools instead
- Commands timeout after 2 minutes by default
- Output truncated at 30000 characters`,
parameters: z.object({
command: z.string(),
timeout: z.number().max(600000).optional(),
run_in_background: z.boolean().optional(),
description: z.string().describe("5-10 word description of what this does"),
}),
async execute({ command, timeout = 120000, run_in_background }, ctx) {
// 1. 安全检查
if (containsDangerousPatterns(command)) {
await ctx.ask({
permission: "bash.dangerous",
command,
warning: "This command may be destructive",
});
}
// 2. 创建 shell 进程
const shell = await createShell({
command,
timeout,
cwd: getWorkingDirectory(),
abort: ctx.abort,
});
// 3. 后台运行处理
if (run_in_background) {
return {
title: `Background: ${description}`,
output: `Started in background. Task ID: ${shell.id}`,
metadata: { taskId: shell.id, background: true },
};
}
// 4. 等待执行完成
const result = await shell.wait();
// 5. 截断过长输出
const output = truncate(result.output, 30000);
return {
title: description || `Run: ${command.slice(0, 50)}`,
output: `Exit code: ${result.exitCode}\n\n${output}`,
metadata: { exitCode: result.exitCode, duration: result.duration },
};
},
}));4.4 工具注册表
所有工具通过 ToolRegistry 统一管理:
namespace ToolRegistry {
export function tools(providerID: string, agent?: string): Tool[] {
const builtinTools = [
InvalidTool, // 处理无效工具调用
BashTool, // Shell 执行
ReadTool, // 文件读取
GlobTool, // 文件匹配
GrepTool, // 代码搜索
EditTool, // 文件编辑
WriteTool, // 文件写入
TaskTool, // 子任务
WebFetchTool, // 网页获取
TodoReadTool, // 任务列表读取
TodoWriteTool, // 任务列表写入
WebSearchTool, // 网页搜索
SkillTool, // 技能调用
];
// 可选工具
if (Config.get().experimental?.lsp) {
builtinTools.push(LSPTool); // Language Server Protocol
}
if (Config.get().experimental?.batch) {
builtinTools.push(BatchTool); // 批量操作
}
// 自定义工具
const customTools = loadCustomTools("~/.opencode/tool/");
// MCP 工具
const mcpTools = MCP.tools();
return [...builtinTools, ...customTools, ...mcpTools];
}
}4.5 MCP:工具的无限扩展
Model Context Protocol (MCP) 是一个开放协议,允许外部服务为 AI 提供工具和资源。OpenCode 完整支持 MCP:
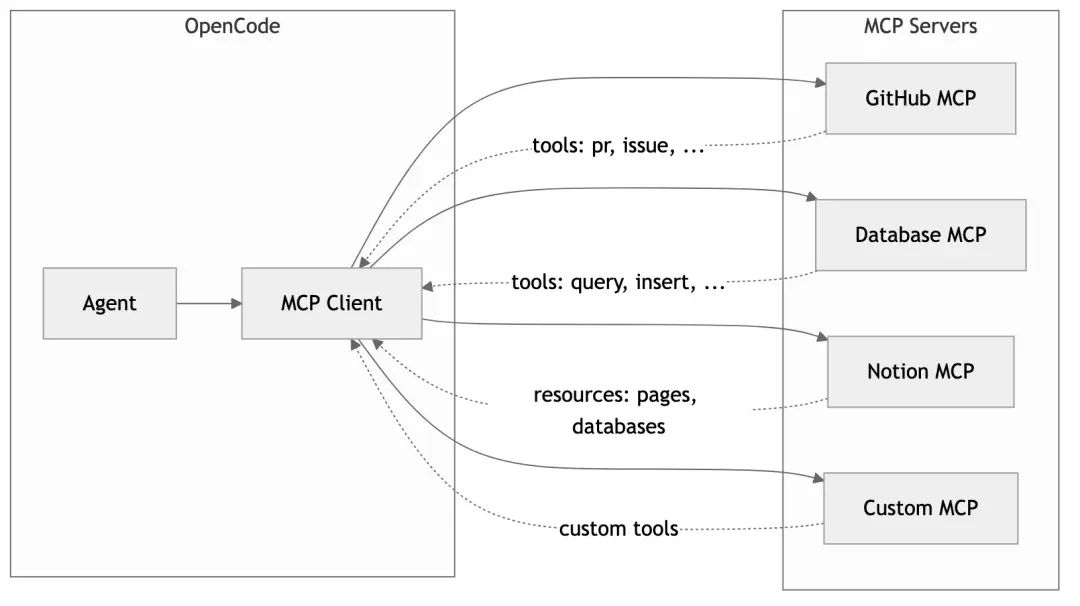
配置 MCP 服务器:
// .opencode/config.json
{
"mcp": {
"servers": {
"github": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-github"],
"env": {
"GITHUB_TOKEN": "..."
}
},
"postgres": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-postgres"],
"env": {
"DATABASE_URL": "..."
}
}
}
}
}这样,AI 就能直接操作 GitHub PR、查询数据库,甚至更新 Notion 文档——而这些能力完全通过配置添加,无需修改代码。
第五章:Provider 抽象层 - 万物皆可 LLM
5.1 多 Provider 的挑战
现在市面上有太多 LLM 提供商了:
- Anthropic (Claude)
- OpenAI (GPT-4, o1)
- Google (Gemini, Vertex AI)
- Azure OpenAI
- AWS Bedrock
- Groq, Mistral, Cohere…
每个提供商的 API 都略有不同:不同的认证方式、不同的请求格式、不同的 streaming 实现、不同的错误处理…
OpenCode 的 Provider 抽象层解决了这个问题。
5.2 统一的 Provider 接口
interface Provider {
id: string;
name: string;
// 认证
getApiKey(): string | undefined;
// 模型列表
models(): Model[];
// 获取语言模型实例
languageModel(modelID: string, options?: ModelOptions): LanguageModel;
}
interface Model {
id: string;
name: string;
provider: string;
// 能力
context: number; // 上下文窗口大小
maxOutput?: number; // 最大输出长度
supportsImages?: boolean; // 支持图像输入
supportsToolUse?: boolean; // 支持工具调用
supportsReasoning?: boolean; // 支持推理(如 o1)
// 成本
pricing?: {
input: number; // $ per 1M tokens
output: number;
cache?: { read: number; write: number };
};
// 配置
options?: ModelOptions;
}5.3 Provider 注册表
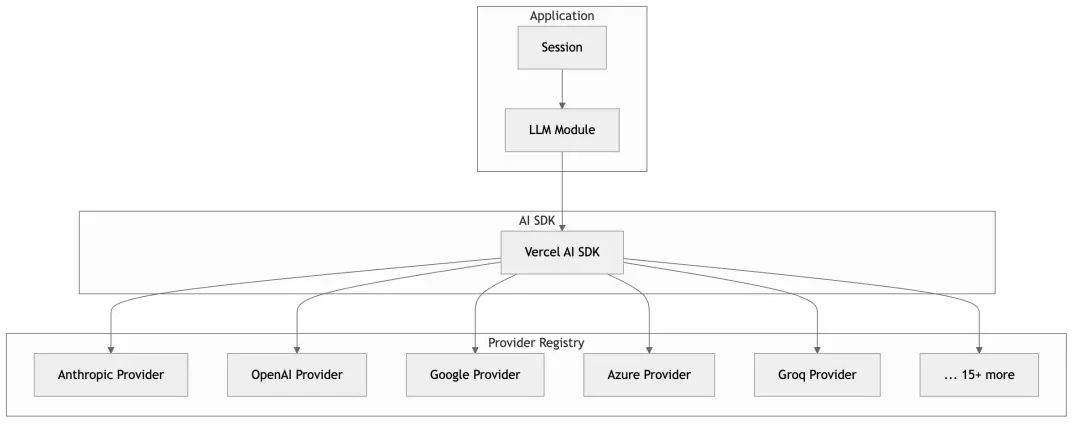
OpenCode 使用 Vercel AI SDK 作为底层,它提供了统一的 streaming 接口:
import { streamText } from "ai";
import { anthropic } from "@ai-sdk/anthropic";
import { openai } from "@ai-sdk/openai";
import { google } from "@ai-sdk/google";
// 无论使用哪个 provider,调用方式都一样
const result = await streamText({
model: anthropic("claude-3-5-sonnet"), // 或 openai("gpt-4"), google("gemini-pro")
messages: [...],
tools: {...},
});
for await (const chunk of result.fullStream) {
// 统一的流式处理
}5.4 智能模型选择
OpenCode 会根据任务自动选择合适的模型:
// 主任务:使用配置的主模型
const mainModel = await Provider.getModel(config.model);
// 小任务(标题、摘要):使用小模型节省成本
const smallModel = await Provider.getSmallModel(mainModel);
// 不同任务使用不同模型
async function generateTitle(sessionID: string) {
return LLM.stream({
model: smallModel, // 使用便宜的小模型
small: true,
agent: "title",
// ...
});
}
async function executeMainTask(sessionID: string) {
return LLM.stream({
model: mainModel, // 使用强大的主模型
agent: "build",
// ...
});
}5.5 Provider 特定优化
不同的 Provider 有不同的最佳实践,OpenCode 对此进行了优化:
// Anthropic 特定的 System Prompt
const PROMPT_ANTHROPIC = `You are Claude, made by Anthropic.
You have access to a set of tools...`;
// OpenAI 特定的 System Prompt
const PROMPT_OPENAI = `You are a helpful assistant with access to tools...`;
// 根据 Provider 选择合适的 prompt
function getSystemPrompt(providerID: string, model: Model) {
if (providerID === "anthropic") {
return PROMPT_ANTHROPIC;
}
if (providerID === "openai" && model.supportsReasoning) {
return PROMPT_OPENAI_REASONING; // o1 模型的特殊处理
}
// ...
}Prompt Caching 优化
Anthropic 支持 Prompt Caching,可以缓存 System Prompt 以减少 token 消耗:
// System prompt 分成两部分
const system = [
header, // [0] 不变的头部 - 可缓存
body, // [1] 动态的正文
];
// 如果头部不变,API 会使用缓存
// 显著减少 input token 成本第六章:上下文压缩 - 记忆的艺术
6.1 长对话的困境
LLM 有一个根本限制:上下文窗口是有限的。
即使是 Claude 的 200K token 窗口,在复杂的编程任务中也会很快被填满:
用户问题 → 500 tokens
代码文件 1 (500 行) → 8,000 tokens
代码文件 2 (300 行) → 5,000 tokens
AI 思考 + 回复 → 3,000 tokens
工具调用结果 1 → 2,000 tokens
工具调用结果 2 → 10,000 tokens
...
第 10 轮对话后 → 150,000 tokens 😱当上下文接近限制时,会发生两件坏事:
- 性能下降:处理时间变长,质量下降
- 失败风险:超过限制会直接报错
6.2 OpenCode 的压缩策略
OpenCode 采用了多层压缩策略:
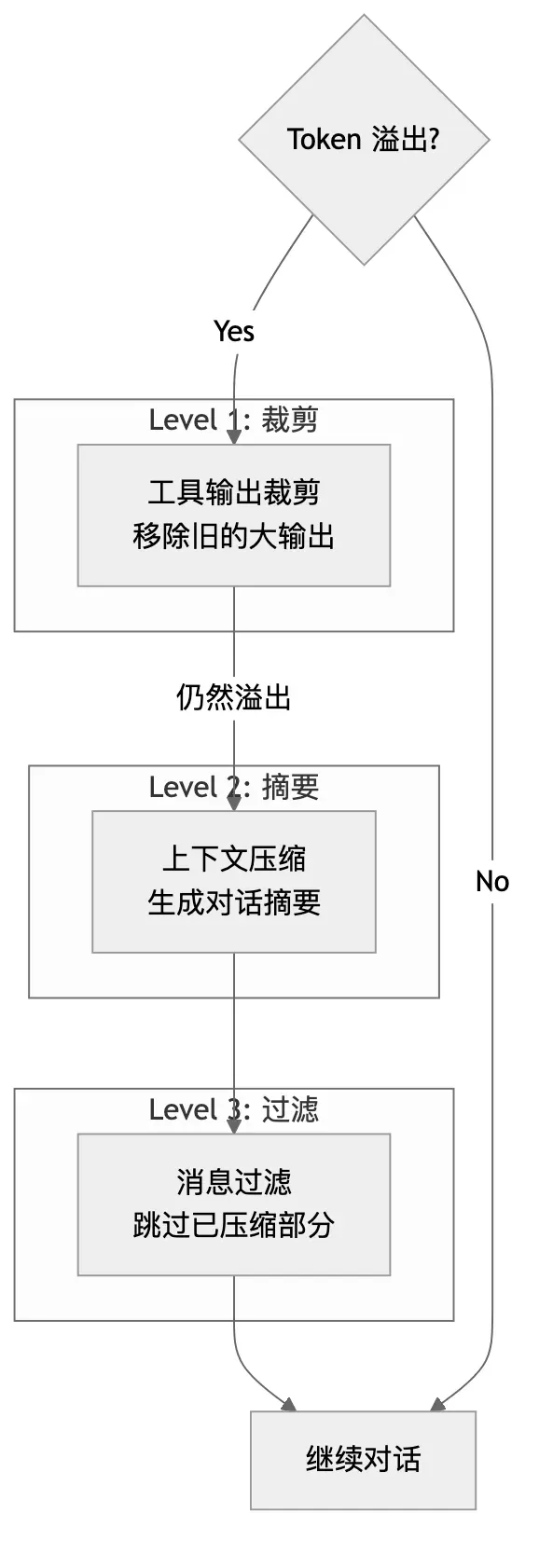
层级 1:工具输出裁剪 (Prune)
旧的工具输出往往占用大量空间但已不再需要:
async function prune(sessionID: string) {
const messages = await Session.messages(sessionID);
let protectedTokens = 0;
const PROTECT_THRESHOLD = 40_000; // 保护最近 40K tokens
const PRUNE_THRESHOLD = 20_000; // 只裁剪超过 20K 的输出
// 从后往前扫描
for (let i = messages.length - 1; i >= 0; i--) {
const msg = messages[i];
for (const part of msg.parts) {
if (part.type === "tool" && part.state.status === "completed") {
const outputSize = estimateTokens(part.state.output);
// 保护最近的工具调用
if (protectedTokens < PROTECT_THRESHOLD) {
protectedTokens += outputSize;
continue;
}
// 裁剪大输出
if (outputSize > PRUNE_THRESHOLD) {
part.state.output = "[TOOL OUTPUT PRUNED]";
part.state.time.compacted = Date.now();
}
}
}
}
}为什么不全部裁剪?
AI 在思考时需要参考最近的工具输出。如果把所有输出都裁掉,它会失去上下文,开始重复相同的工具调用(“让我再读一下这个文件…”)。
40K tokens 的保护区是一个平衡点:足够 AI 工作,又不会占用太多空间。
层级 2:上下文压缩 (Compaction)
当裁剪不够时,需要更激进的压缩——生成摘要:
async function compact(sessionID: string) {
// 1. 创建压缩 Agent 消息
const compactionMessage = await Session.createAssistant({
sessionID,
agent: "compaction",
mode: "compact",
});
// 2. 构建压缩提示
const compactionPrompt = `You are a conversation summarizer. Your task is to create a comprehensive
summary of the conversation so far that preserves all important context
needed to continue the task.
Include:
- What the user originally asked
- What actions have been taken
- Current state of the task
- Any important findings or decisions
The summary will replace the conversation history, so it must be complete.`;
// 3. 调用 LLM 生成摘要
const summary = await LLM.stream({
agent: "compaction",
messages: getAllMessages(sessionID),
system: compactionPrompt,
});
// 4. 标记压缩点
await Session.updatePart(compactionMessage.id, {
type: "compaction",
});
// 5. 创建合成用户消息继续对话
await Session.createSyntheticUser({
sessionID,
content: "Please continue with the task based on the summary above.",
});
}压缩后的对话历史:
[压缩前 - 150K tokens]
User: 帮我重构用户模块
AI: 让我先看看代码... [工具调用 x 20]
User: 那个函数有 bug
AI: 我来修复... [工具调用 x 15]
User: 还需要加测试
AI: 好的... [工具调用 x 10]
[压缩后 - 5K tokens]
AI (compaction):
## 任务摘要
用户请求重构用户模块。已完成:
1. 分析了 src/user/ 下的所有文件
2. 重构了 UserService,将其拆分为三个小类
3. 修复了 getUserById 的空指针 bug
4. 添加了单元测试,覆盖率达 85%
当前状态:基本完成,用户可能还有后续需求。
User (synthetic): Please continue with the task based on the summary above.层级 3:消息过滤
在构建 LLM 输入时,会自动跳过已压缩部分:
function filterCompacted(messages: Message[]): Message[] {
// 找到最后一个压缩标记
const lastCompactionIndex = messages.findLastIndex(
msg => msg.parts.some(p => p.type === "compaction")
);
if (lastCompactionIndex === -1) {
return messages; // 没有压缩,返回全部
}
// 只返回压缩标记之后的消息
return messages.slice(lastCompactionIndex);
}6.3 溢出检测
function isOverflow(model: Model, messages: Message[]): boolean {
const contextLimit = model.context;
const outputReserve = model.maxOutput || 8192;
const currentTokens = estimateTokens(messages);
// 留出足够的输出空间
return currentTokens > contextLimit - outputReserve;
}这个检查在每次 LLM 调用前执行。一旦检测到溢出风险,会立即触发压缩流程。
第七章:安全与权限 - 信任但要验证
7.1 为什么需要权限系统?
AI Agent 拥有强大的能力,但”能力越大,责任越大”。想象一下这些场景:
- AI 执行
rm -rf /会怎样? - AI 读取
~/.ssh/id_rsa会怎样? - AI 向外部服务发送你的代码会怎样?
没有权限系统,这些都可能发生。OpenCode 实现了细粒度的权限控制。
7.2 权限模型
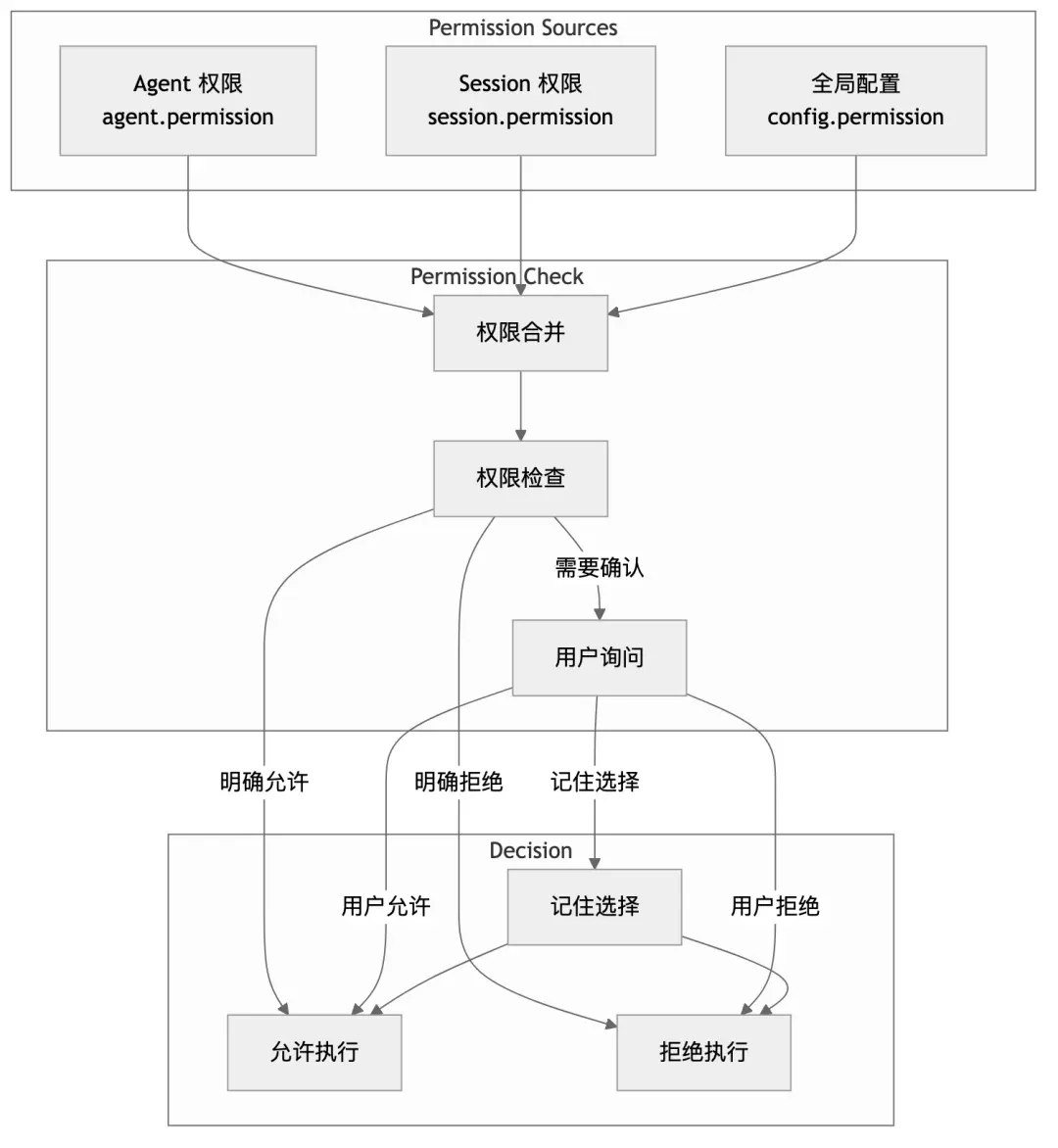
7.3 权限规则定义
interface PermissionRule {
// 匹配条件
tool?: string; // 工具名匹配
path?: string | RegExp; // 路径匹配
command?: string | RegExp; // 命令匹配
// 决策
allow?: boolean; // 允许
deny?: boolean; // 拒绝
ask?: boolean; // 询问用户
// 记忆
always?: boolean; // 记住这个选择
}
// 示例配置
const permissionRules: PermissionRule[] = [
// 允许读取项目内文件
{ tool: "read", path: /^\/project\//, allow: true },
// 拒绝读取私钥
{ tool: "read", path: /\.ssh|\.env|password/, deny: true },
// 危险命令需要确认
{ tool: "bash", command: /rm|sudo|chmod|curl/, ask: true },
// 外部路径需要确认
{ tool: "write", path: /^(?!\/project\/)/, ask: true },
];7.4 权限检查流程
async function checkPermission(
tool: string,
args: Record<string, unknown>,
ctx: ToolContext
): Promise<void> {
// 1. 获取合并后的权限规则
const rules = PermissionNext.merge(
ctx.agent.permission,
ctx.session.permission,
Config.get().permission
);
// 2. 找到匹配的规则
const matchedRule = rules.find(rule => matches(rule, tool, args));
// 3. 如果明确允许,直接通过
if (matchedRule?.allow) {
return;
}
// 4. 如果明确拒绝,抛出异常
if (matchedRule?.deny) {
throw new PermissionNext.RejectedError(tool, args);
}
// 5. 如果需要询问,请求用户确认
if (!matchedRule || matchedRule.ask) {
await ctx.ask({
permission: `tool.${tool}`,
metadata: args,
patterns: extractPatterns(args),
always: matchedRule?.always ?? false,
});
}
}7.5 用户交互界面
当需要用户确认时,CLI 会显示:
┌─────────────────────────────────────────────────────────────────┐
│ 🔐 Permission Required │
├─────────────────────────────────────────────────────────────────┤
│ │
│ Tool: bash │
│ Command: rm -rf ./dist │
│ │
│ This command will delete the ./dist directory. │
│ │
│ [Y] Allow once │
│ [A] Always allow this pattern │
│ [N] Deny │
│ [D] Always deny this pattern │
│ │
└─────────────────────────────────────────────────────────────────┘选择 “Always allow” 会将规则保存到 Session 权限中,后续相同模式的请求自动通过。
7.6 死循环保护 (Doom Loop Detection)
权限系统还包含一个特殊保护:死循环检测。
当 AI 陷入无效循环时(重复调用相同工具),系统会自动介入:
function detectDoomLoop(toolParts: ToolPart[]): boolean {
if (toolParts.length < 3) return false;
// 获取最近 3 次工具调用
const last3 = toolParts.slice(-3);
// 检查是否完全相同
const allSame = last3.every(part =>
part.state.name === last3[0].state.name &&
JSON.stringify(part.state.input) === JSON.stringify(last3[0].state.input)
);
return allSame;
}
// 在工具调用时检查
async function onToolCall(tool: string, input: object, ctx: ToolContext) {
if (detectDoomLoop(getRecentToolParts(ctx.messageID))) {
// 询问用户是否继续
await ctx.ask({
permission: "doom_loop",
message: `AI is calling the same tool (${tool}) repeatedly with identical arguments. This might indicate a stuck loop.`,
options: ["Continue anyway", "Stop and intervene"],
});
}
}第八章:亮点技术深度解析
8.1 流式思考提取 (Reasoning Extraction)
OpenCode 最酷的功能之一是实时显示 AI 的思考过程。这是如何实现的?
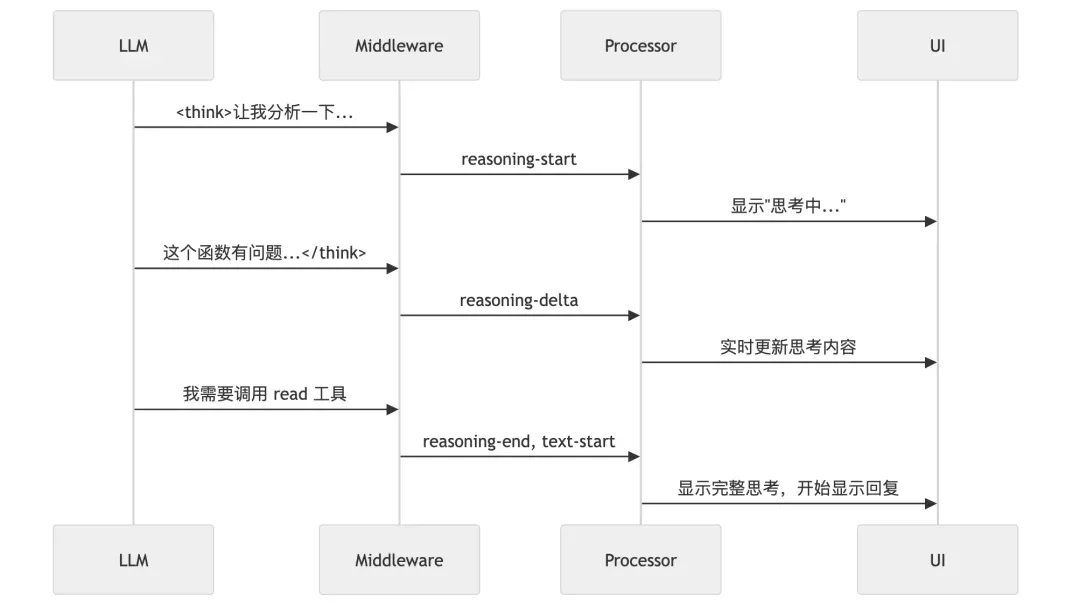
实现原理:
import { wrapLanguageModel, extractReasoningMiddleware } from "ai";
// 包装模型以提取思考过程
const wrappedModel = wrapLanguageModel(baseModel,
extractReasoningMiddleware({
tagName: "think" // 提取 <think>...</think> 中的内容
})
);
// 流式事件处理
for await (const event of stream.fullStream) {
switch (event.type) {
case "reasoning-start":
// 创建思考 Part
createReasoningPart(messageID);
break;
case "reasoning-delta":
// 追加思考内容
appendToReasoningPart(messageID, event.text);
// UI 实时更新
publishPartUpdate(messageID, partID);
break;
case "reasoning-end":
// 完成思考
finalizeReasoningPart(messageID);
break;
}
}用户看到的效果:
┌─────────────────────────────────────────────────────────────────┐
│ 🤔 Thinking... │
├─────────────────────────────────────────────────────────────────┤
│ 让我分析一下这个函数。 │
│ │
│ 问题出在第 42 行:fetchData() 返回的是 Promise<string>, │
│ 但代码直接赋值给 string 类型的变量,没有 await。 │
│ │
│ 我需要: │
│ 1. 读取完整文件确认上下文 │
│ 2. 添加 await 关键字 │
│ 3. 确保函数是 async 的 │
└─────────────────────────────────────────────────────────────────┘这不仅提供了更好的用户体验,还增加了透明度——用户可以看到 AI 是如何思考的,从而更好地理解和验证其决策。
8.2 文件系统快照与回滚
OpenCode 的另一个亮点是任何修改都可以回滚。这是通过 Git 快照实现的:
// 步骤开始时创建快照
async function onStepStart(ctx: StepContext) {
// 记录当前 Git 状态
const snapshot = await Snapshot.track({
directory: ctx.directory,
includeUntracked: true, // 包括未跟踪文件
});
// 保存快照引用
await Session.updatePart(ctx.messageID, {
type: "step-start",
snapshot: snapshot.ref,
});
}
// 步骤结束时计算变更
async function onStepFinish(ctx: StepContext) {
const startSnapshot = getStepStartSnapshot(ctx.messageID);
const currentSnapshot = await Snapshot.track({ directory: ctx.directory });
// 计算 diff
const patch = await Snapshot.diff(startSnapshot, currentSnapshot);
// 保存 patch
await Session.updatePart(ctx.messageID, {
type: "patch",
diff: patch,
additions: countAdditions(patch),
deletions: countDeletions(patch),
});
}
// 回滚到任意快照
async function revert(sessionID: string, messageID: string) {
const snapshot = await Session.getSnapshot(messageID);
// 恢复文件状态
await Snapshot.restore(snapshot.ref);
// 创建回滚消息
await Session.updatePart(messageID, {
type: "revert",
snapshot: snapshot.ref,
});
}回滚界面:
┌─────────────────────────────────────────────────────────────────┐
│ 📜 Session History │
├─────────────────────────────────────────────────────────────────┤
│ │
│ [1] 10:30 - Read src/app.ts │
│ [2] 10:31 - Edit src/app.ts (+5, -3) [🔄 Revert] │
│ [3] 10:32 - Run tests │
│ [4] 10:33 - Edit src/utils.ts (+20, -0) [🔄 Revert] │
│ [5] 10:35 - Create src/new-file.ts (+50, -0) [🔄 Revert] │
│ │
│ Select step to revert, or press Q to cancel │
└─────────────────────────────────────────────────────────────────┘8.3 智能摘要生成
每次对话结束后,OpenCode 会自动生成摘要:
async function summarize(sessionID: string, messageID: string) {
// 1. 生成标题
const title = await generateTitle(sessionID, messageID);
// 2. 生成正文摘要
const body = await generateBody(sessionID, messageID);
// 3. 计算文件变更统计
const diffs = await computeDiffs(sessionID);
// 4. 保存摘要
await Session.updateMessage(messageID, {
summary: { title, body, diffs },
});
}
async function generateTitle(sessionID: string, messageID: string) {
// 使用小模型生成标题
const result = await LLM.stream({
model: smallModel,
agent: "title",
messages: getFirstUserMessage(sessionID),
system: "Generate a concise title (max 100 chars) for this conversation.",
});
return result.text.slice(0, 100);
}摘要用于:
- 会话列表显示
- 历史搜索
- 上下文压缩后的参考
8.4 Prompt Caching 优化
Anthropic 的 API 支持 Prompt Caching,OpenCode 充分利用了这一特性:
// System prompt 分成两部分
function buildSystemPrompt(agent: Agent, custom: string[]) {
return [
// [0] 静态头部 - 可被缓存
PROVIDER_HEADER,
// [1] 动态正文 - 每次可能不同
[
agent.prompt,
...custom,
environmentInfo(),
].join("\n"),
];
}
// 如果头部不变,Anthropic 会使用缓存
// 可以节省 50-90% 的 input token成本对比:
Without Caching:
- Input: 50,000 tokens × $3/M = $0.15
- Output: 2,000 tokens × $15/M = $0.03
- Total: $0.18
With Caching (80% cache hit):
- Input (cached): 40,000 tokens × $0.30/M = $0.012
- Input (new): 10,000 tokens × $3/M = $0.03
- Output: 2,000 tokens × $15/M = $0.03
- Total: $0.072
Savings: 60%!8.5 并行工具执行
当 AI 需要调用多个独立工具时,OpenCode 支持并行执行:
// AI 返回多个工具调用
const toolCalls = [
{ name: "read", args: { file_path: "src/a.ts" } },
{ name: "read", args: { file_path: "src/b.ts" } },
{ name: "grep", args: { pattern: "TODO", path: "src/" } },
];
// 并行执行所有工具
const results = await Promise.all(
toolCalls.map(async (call) => {
const tool = ToolRegistry.get(call.name);
return tool.execute(call.args, ctx);
})
);
// 所有结果一起返回给 LLM这显著提高了效率,特别是在需要读取多个文件或执行多个搜索时。
第九章:从源码学习设计模式
OpenCode 的代码库是学习现代 TypeScript 设计模式的绝佳教材。让我们看看它使用了哪些模式。
9.1 Namespace 模式
OpenCode 大量使用 TypeScript 的 namespace 来组织代码:
// session/index.ts
export namespace Session {
// 类型定义
export const Info = z.object({...});
export type Info = z.infer<typeof Info>;
// 事件定义
export const Event = {
Created: BusEvent.define("session.created", Info),
Updated: BusEvent.define("session.updated", Info),
Deleted: BusEvent.define("session.deleted", z.string()),
};
// 方法
export async function create(input: CreateInput): Promise<Info> {...}
export async function get(id: string): Promise<Info | null> {...}
export async function update(id: string, editor: Editor): Promise<Info> {...}
export async function remove(id: string): Promise<void> {...}
}为什么用 Namespace?
- 命名空间隔离:避免全局污染
- 组织代码:相关功能放在一起
- 类型和值共存:
Session.Info既是类型也是 Schema - 自文档化:
Session.create()比createSession()更清晰
9.2 Discriminated Union 模式
// 使用字面量类型作为判别器
type Part =
| { type: "text"; content: string; }
| { type: "tool"; state: ToolState; }
| { type: "reasoning"; content: string; };
// 类型收窄
function renderPart(part: Part) {
switch (part.type) {
case "text":
// TypeScript 知道这里 part 是 { type: "text"; content: string }
return <Text>{part.content}</Text>;
case "tool":
// TypeScript 知道这里 part 是 { type: "tool"; state: ToolState }
return <ToolCall state={part.state} />;
case "reasoning":
return <Thinking>{part.content}</Thinking>;
}
}这种模式在 OpenCode 中无处不在,它让复杂的类型变得可管理。
9.3 Builder 模式
System Prompt 的构建使用了 Builder 模式:
class SystemPromptBuilder {
private parts: string[] = [];
addHeader(providerID: string) {
this.parts.push(SystemPrompt.header(providerID));
return this;
}
addAgentPrompt(agent: Agent) {
if (agent.prompt) {
this.parts.push(agent.prompt);
}
return this;
}
addCustomInstructions(paths: string[]) {
for (const path of paths) {
const content = readFileSync(path, "utf-8");
this.parts.push(content);
}
return this;
}
addEnvironment(info: EnvInfo) {
this.parts.push(formatEnvironment(info));
return this;
}
build(): string[] {
// 返回可缓存的两部分结构
return [
this.parts[0], // header
this.parts.slice(1).join("\n"), // body
];
}
}9.4 Factory 模式
工具创建使用了 Factory 模式:
namespace Tool {
export function define<T extends z.ZodObject<any>>(
id: string,
init: () => ToolDefinition<T>
): Tool {
// 延迟初始化
let definition: ToolDefinition<T> | null = null;
return {
id,
get schema() {
definition ??= init();
return definition.parameters;
},
get description() {
definition ??= init();
return definition.description;
},
async execute(args: z.infer<T>, ctx: ToolContext) {
definition ??= init();
return definition.execute(args, ctx);
},
};
}
}
// 使用
const ReadTool = Tool.define("read", () => ({
description: "Reads a file",
parameters: z.object({ file_path: z.string() }),
execute: async (args, ctx) => {...},
}));延迟初始化(init() 只在首次使用时调用)可以加快启动速度。
9.5 Observer 模式 (Event Bus)
OpenCode 使用事件总线实现松耦合通信:
// 定义事件
const SessionCreated = BusEvent.define("session.created", Session.Info);
const MessageUpdated = BusEvent.define("message.updated", MessageV2.Info);
// 发布事件
Bus.publish(SessionCreated, sessionInfo);
// 订阅事件
Bus.subscribe(SessionCreated, (session) => {
console.log(`New session: ${session.title}`);
});
// 在 UI 中使用
function SessionList() {
const [sessions, setSessions] = useState<Session.Info[]>([]);
useEffect(() => {
// 订阅会话变更
const unsubscribe = Bus.subscribe(SessionCreated, (session) => {
setSessions(prev => [...prev, session]);
});
return unsubscribe;
}, []);
return <List items={sessions} />;
}9.6 Strategy 模式
Provider 实现使用了 Strategy 模式:
interface ProviderStrategy {
id: string;
getApiKey(): string | undefined;
models(): Model[];
languageModel(modelID: string): LanguageModel;
}
class AnthropicProvider implements ProviderStrategy {
id = "anthropic";
getApiKey() {
return process.env.ANTHROPIC_API_KEY;
}
models() {
return [
{ id: "claude-3-5-sonnet", context: 200000, ... },
{ id: "claude-3-opus", context: 200000, ... },
];
}
languageModel(modelID: string) {
return anthropic(modelID);
}
}
class OpenAIProvider implements ProviderStrategy {
id = "openai";
// ... 不同的实现
}
// 统一使用
function getProvider(id: string): ProviderStrategy {
const providers = {
anthropic: new AnthropicProvider(),
openai: new OpenAIProvider(),
// ...
};
return providers[id];
}第十章:性能优化与工程实践
10.1 启动性能优化
CLI 工具的启动速度至关重要。OpenCode 采用了多种优化:
// 1. 延迟导入
async function runCommand() {
// 只在需要时才导入重型模块
const { Session } = await import("./session");
const { Server } = await import("./server");
// ...
}
// 2. 延迟初始化
let _config: Config | null = null;
function getConfig() {
// 首次调用时才加载配置
_config ??= loadConfig();
return _config;
}
// 3. 并行初始化
async function bootstrap() {
// 并行执行独立的初始化任务
await Promise.all([
loadConfig(),
initializeStorage(),
discoverMCPServers(),
]);
}10.2 内存管理
长时间运行的 Agent 需要注意内存管理:
// 1. 流式处理,避免大字符串
async function* streamFile(path: string) {
const stream = createReadStream(path);
for await (const chunk of stream) {
yield chunk.toString();
}
}
// 2. 及时清理
function cleanup(sessionID: string) {
// 清理缓存
messageCache.delete(sessionID);
partCache.delete(sessionID);
// 触发 GC(在 Bun 中)
Bun.gc(true);
}
// 3. 弱引用缓存
const cache = new WeakMap<object, ComputedValue>();10.3 并发控制
// 使用信号量限制并发
class Semaphore {
private permits: number;
private queue: (() => void)[] = [];
constructor(permits: number) {
this.permits = permits;
}
async acquire() {
if (this.permits > 0) {
this.permits--;
return;
}
await new Promise<void>(resolve => this.queue.push(resolve));
}
release() {
const next = this.queue.shift();
if (next) {
next();
} else {
this.permits++;
}
}
}
// 限制同时执行的工具数量
const toolSemaphore = new Semaphore(5);
async function executeTool(tool: Tool, args: object, ctx: ToolContext) {
await toolSemaphore.acquire();
try {
return await tool.execute(args, ctx);
} finally {
toolSemaphore.release();
}
}10.4 错误处理最佳实践
// 1. 类型化错误
class ToolExecutionError extends Error {
constructor(
public tool: string,
public args: object,
public cause: Error
) {
super(`Tool ${tool} failed: ${cause.message}`);
this.name = "ToolExecutionError";
}
}
// 2. 错误边界
async function safeExecute<T>(
fn: () => Promise<T>,
fallback: T
): Promise<T> {
try {
return await fn();
} catch (error) {
console.error("Execution failed:", error);
return fallback;
}
}
// 3. 重试逻辑
async function withRetry<T>(
fn: () => Promise<T>,
options: { maxAttempts: number; delay: number }
): Promise<T> {
let lastError: Error | undefined;
for (let attempt = 1; attempt <= options.maxAttempts; attempt++) {
try {
return await fn();
} catch (error) {
lastError = error as Error;
if (!isRetryable(error) || attempt === options.maxAttempts) {
throw error;
}
// 指数退避
await sleep(options.delay * Math.pow(2, attempt - 1));
}
}
throw lastError;
}10.5 测试策略
// 1. 单元测试
describe("Session", () => {
it("should create session with correct defaults", async () => {
const session = await Session.create({
projectID: "test-project",
directory: "/test",
});
expect(session.id).toBeDefined();
expect(session.title).toBe("");
expect(session.time.created).toBeLessThanOrEqual(Date.now());
});
});
// 2. 集成测试
describe("Tool Execution", () => {
it("should read file correctly", async () => {
const result = await ReadTool.execute(
{ file_path: "/test/file.txt" },
mockContext
);
expect(result.output).toContain("file content");
});
});
// 3. E2E 测试
describe("Full Workflow", () => {
it("should complete code editing task", async () => {
const session = await Session.create({...});
await SessionPrompt.prompt({
sessionID: session.id,
parts: [{ type: "text", content: "Fix the bug in app.ts" }],
});
const messages = await Session.messages(session.id);
const lastAssistant = messages.findLast(m => m.role === "assistant");
expect(lastAssistant.finish).toBe("stop");
expect(lastAssistant.parts.some(p =>
p.type === "tool" && p.state.name === "edit"
)).toBe(true);
});
});结语:AI 编程的未来
回顾:我们学到了什么?
通过深入 OpenCode 的源码,我们看到了一个现代 AI Agent 框架的完整实现:
- 会话管理:三层结构(Session → Message → Part)支持复杂的状态追踪
- Agent 系统:专业化的角色定义,支持子任务和并行执行
- 工具系统:声明式定义,上下文感知,权限控制
- Provider 抽象:统一接口,支持 18+ LLM 提供商
- 上下文压缩:多层策略(裁剪、摘要、过滤)解决长对话问题
- 安全机制:细粒度权限控制,死循环保护
展望:AI 编程的下一步
OpenCode 代表了 AI 编程助手的当前水平,但这只是开始。未来可能的发展方向:
1. 更强的代码理解
- 集成更多 LSP 功能
- 支持类型推导和重构
- 理解项目架构和设计模式
2. 更智能的任务规划
- 自动分解复杂任务
- 预测可能的问题和解决方案
- 学习用户的编码习惯
3. 更好的协作体验
- 多 Agent 协作
- 人机混合编程
- 实时代码审查
4. 更广泛的集成
- 与 CI/CD 系统集成
- 支持更多编程语言和框架
- 连接更多外部服务(数据库、API、文档)
最后的话
OpenCode 不仅仅是一个工具,它是对”AI 能为编程做什么”这个问题的一次认真回答。
它的代码库展示了如何将复杂的 AI 能力包装成优雅的开发体验。每一个设计决策——从流式思考提取到上下文压缩,从权限系统到回滚功能——都是为了让 AI 成为真正有用的编程伙伴。
如果你是一名开发者,我强烈建议你:
- 使用它:亲身体验 AI 编程的感觉
- 阅读它:源码是最好的教材
- 贡献它:开源项目需要社区的力量
AI 不会取代程序员,但会使用 AI 的程序员会取代不会的。
现在,是时候拥抱 AI 编程的未来了。
本文基于 OpenCode 源码分析撰写。如有任何技术问题,欢迎在 GitHub Issues 中讨论。
附录:快速参考
A. 核心文件位置
| 功能 | 文件路径 |
|---|---|
| CLI 入口 | packages/opencode/src/index.ts |
| Session 管理 | packages/opencode/src/session/index.ts |
| 主循环 | packages/opencode/src/session/prompt.ts |
| 流处理 | packages/opencode/src/session/processor.ts |
| LLM 调用 | packages/opencode/src/session/llm.ts |
| 工具注册 | packages/opencode/src/tool/registry.ts |
| Provider | packages/opencode/src/provider/provider.ts |
| 权限系统 | packages/opencode/src/permission/ |
B. 关键类型定义
// Session
Session.Info
Session.Event.Created
Session.Event.Updated
// Message
MessageV2.User
MessageV2.Assistant
MessageV2.Part
// Tool
Tool.Context
Tool.Result
ToolState
// Agent
Agent.Info
Agent.Mode
// Provider
Provider.Model
Provider.OptionsC. 配置文件
# 全局配置
~/.opencode/config.json
# 项目配置
.opencode/config.json
# 自定义指令
AGENTS.md
CLAUDE.md
CONTEXT.md
# 自定义工具
~/.opencode/tool/*.tsD. 环境变量
# API Keys
ANTHROPIC_API_KEY=sk-ant-...
OPENAI_API_KEY=sk-...
GOOGLE_API_KEY=...
# 配置
OPENCODE_MODEL=claude-3-5-sonnet
OPENCODE_PROVIDER=anthropic
OPENCODE_DEBUG=true