Digital Strategy Review | 2026
OpenAI 发布 GPT-5.4 mini 和 nano,价格战开始改写 AI API 市场 | 果叔AI日报
文 / 果叔 · 阅读时间 / 8 Min
写在前面
如果你最近还在用过去那套方式理解模型竞争,可能会越来越跟不上节奏。
以前我们说大模型市场竞争,主要看三件事:谁最强、谁最会做 demo、谁先把新能力做进产品。到了 2026 年 3 月 19 日这一天,讨论的重心已经明显在往另一边挪了:谁能把“够用的强”压到足够低的价格,谁就更可能真正吃掉开发者工作流。
这也是我今天把头版给到 GPT-5.4 mini 和 nano 的原因。OpenAI 在 2026 年 3 月 17 日正式发布这两个新模型时,给出的信息不只是“更小更快”,而是一个更完整的信号组合:mini 在多个编码与工具使用评测上接近大模型,同时跑得更快;nano 进一步把价格压到每百万输入 token 0.20 美元;更重要的是,OpenAI 还直接把 mini 塞进了 Codex 和 ChatGPT 的实际工作流里。
也就是说,今天这条新闻的关键不是“OpenAI 又发新模型了”,而是:小模型开始从“便宜备胎”变成真正的一线生产模型,而且它们已经被定义成 AI 工作流里的默认执行层。

01
今日头版重点新闻
要点速览
01 OpenAI 于 2026 年 3 月 17 日发布 GPT-5.4 mini 与 nano。官方把它们定义为“目前最强的小模型”,重点强调 coding、tool use、多模态理解与高吞吐量场景。
02 mini 的位置非常明确:它不是单纯低配版,而是接近 GPT-5.4 的工作流模型。OpenAI 官方文中直接写到,mini 在多项编码与工具评测上逼近 GPT-5.4,而且运行速度超过旧版 mini 的 2 倍。
03 nano 的价格更激进:每百万输入 token 0.20 美元、输出 1.25 美元。这个价格已经逼近“你可以开始把很多以前觉得不配上大模型的任务,全量接进去”的水平。
04 工作流层面的变化比模型本身更重要:OpenAI 不是把 mini/nano 只放在 API 价格表里,而是同步写进了 Codex 的 subagents 场景,等于直接告诉开发者:以后复杂任务由大模型规划,简单与并行子任务交给更便宜的小模型跑。
事实层:今天能确认什么
根据 OpenAI 官方发布页,GPT-5.4 mini 与 nano 都在 2026 年 3 月 17 日上线。OpenAI 把它们描述为“fast and efficient models optimized for coding and subagents”。其中,mini 在 API、Codex 和 ChatGPT 中可用;nano 目前只在 API 中提供。
官方给出的定价是:
• GPT-5.4 mini:输入 0.75 美元 / 百万 token,输出 4.50 美元 / 百万 token
• GPT-5.4 nano:输入 0.20 美元 / 百万 token,输出 1.25 美元 / 百万 token
官方同时给出了几组关键 benchmark。以高 reasoning effort 计算时,mini 在 SWE-Bench Pro 上达到 54.4%,nano 达到 52.4%,而旧版 GPT-5 mini 是 45.7%。在 Toolathlon 上,mini 是 42.9%,nano 是 35.5%,旧版 GPT-5 mini 是 26.9%。这些数字的意思很简单:它们不是“便宜但明显弱很多”的模型,而是在不少真实开发工作流里,已经强到可以被认真当成主力。
Simon Willison 的解读补上了另一个维度:价格带变化带来的体感冲击。他把新价格表和 Claude、Gemini 做了并排比较,指出 gpt-5.4-nano 的输入价格甚至低于 Gemini 3.1 Flash-Lite,而且在他自己的图像描述测试里,按这个成本去描述 76,000 张照片,费用大约只要 52.44 美元。
还有一个很重要但容易被忽视的点,是 OpenAI 官方在发布页里直接把 mini 绑定到了 Codex 的 subagents 场景:大模型负责 planning、coordination 和 final judgment,mini subagents 负责搜索代码库、读大文件、处理支撑性材料。这意味着 mini 的价值不只是“便宜”,而是它已经被设计成整个 agent 工作流里默认的大规模执行层。
来源(OpenAI 官方):
https://openai.com/index/introducing-gpt-5-4-mini-and-nano/
补充来源(Simon Willison):
https://simonwillison.net/2026/Mar/17/mini-and-nano/
补充来源(OpenAI Codex 文档):
https://developers.openai.com/codex/subagents
为什么它值得当日头版
因为这条新闻真正改写的不是“模型排行榜”,而是 开发者买模型、选模型、分配模型的默认方式。
过去很多团队选型时会问:我到底要最强模型,还是更便宜模型? 接下来更常见的问题会变成:我这个工作流里,哪些环节必须用最强模型,哪些环节应该默认交给 mini,哪些极低复杂度任务已经可以批量丢给 nano?
一旦决策逻辑变成这样,市场结构就会跟着变:中档模型会先承压,旧工作流会先过时,真正会用“大小模型混编”的团队会明显占便宜。
02
头版解读:为什么这件事更重要
1) 价格战已经从“降价”升级成“重写系统架构”
很多人看到这条新闻,第一反应会停在“OpenAI 又降价了”。但我觉得把它只理解成价格战,会低估它的破坏力。
因为今天的变化不是单一价格数字,而是三件事叠在一起:
01 小模型性能显著抬升
02 小模型价格继续往下打
03 小模型被明确写进产品级 agent 工作流
这三件事叠在一起的结果,是团队在系统架构层面会更倾向于做“分层调度”。
以前大家容易写成“一把梭”:一个强模型从头跑到尾,成本高但省心。 接下来更合理的系统会越来越像:
• 大模型负责规划、歧义判断、最终审校
• mini 负责大部分主干执行任务
• nano 负责分类、提取、批处理、支持性子任务
这意味着模型价格表不再只是采购信息,而是架构决策的一部分。
2) mini 真正威胁的,是“中间档模型”的存在感
如果一个模型便宜很多,但性能差一大截,那它只是补位产品。 如果一个模型便宜很多,但性能已经接近大模型在常见任务里的实用区间,那它开始挤压的就不是高端,而是中档。
GPT-5.4 mini 最危险的地方就在这里。
OpenAI 官方给它的定位很聪明:不是说它全面等于 GPT-5.4,而是强调在 coding、tool use、multimodal understanding 这些高频工作流里,它已经足够强,而且更快。对很多团队来说,这就够了。因为真实生产里,最常见的问题从来不是“能不能解最难题”,而是“能不能便宜、稳定、快速地把 80% 的任务做完”。
一旦 mini 在这个区间站稳,中档模型就会开始难受。它们如果价格不够低,会被 mini 吃掉;如果能力不够突出,又打不过大模型。 我对这部分的判断是:2026 年真正难熬的,不是最贵模型,也不是最便宜模型,而是那些“既不够强、也不够便宜”的中间层。
3) nano 让“以前懒得接 AI 的任务”开始值得接
很多工作流过去没接模型,不是技术上接不进去,而是经济上不划算。
比如:
• 大批量文本分类
• 日志清洗与结构化抽取
• 文档元数据补全
• 图片描述、截图理解
• 工具链中的前置筛选任务
• Agent 工作流里的支撑性子任务
这些任务的问题通常不是难,而是量太大。你用大模型做,账单容易把自己吓一跳;你用太弱的模型做,误差又会拖累全链路。nano 的意义就在于,它把很多“量大、要求不极限、但需要模型理解力”的任务,压到了可以放心接进系统的成本带。
Simon Willison 那个“描述 76,000 张照片只要 52 美元左右”的例子其实很能说明问题:这不是一个玩笑式的 demo,而是一个定价心理阈值的变化。开发者会开始更敢于说:既然已经这么便宜,那这一步为什么不直接让模型做?
4) OpenAI 在借 mini / nano 强化自己的工具生态
如果你只看模型,会觉得这只是一次小型号扩容。 如果你把发布页和 Codex 文档放在一起看,会发现 OpenAI 在做的是另一件事:用更便宜的小模型,去强化自己整套开发者生态的内循环。
官方文案写得很明白:在 Codex 里,大模型负责全局,大量简单子任务可以委托给 mini subagents。这个设计等于把“用便宜模型做细活”产品化了。
这件事为什么重要?因为一旦开发者开始在 Codex、API、ChatGPT 里自然接受这种分层模型调用方式,OpenAI 的优势就不只在模型本身,而会变成:
01 你已经习惯它的工作流
02 你已经接受它的调度逻辑
03 你已经把产品成本结构建在它的价格带上
这会显著提高生态粘性。
5) 对创业者来说,机会不是“用更便宜模型”,而是“重算产品边界”
我觉得今天这条新闻最值得创业者看的,不是单纯省多少钱,而是:产品边界会被重新划线。
以前一个功能如果调用模型太贵,团队会选择不做,或者做得很抠。 现在 mini / nano 把很多调用成本压下来后,你可以重新思考:
• 有没有原本因为成本没做的 AI 辅助功能?
• 有没有可以从单步回答升级成多步 agent 的模块?
• 有没有原本必须人工兜底的流程,现在可以先让模型筛一轮?
• 有没有过去只给高付费用户的能力,现在可以往更大人群开放?
这部分不是“省成本”,而是“重新定义什么叫值得做”。
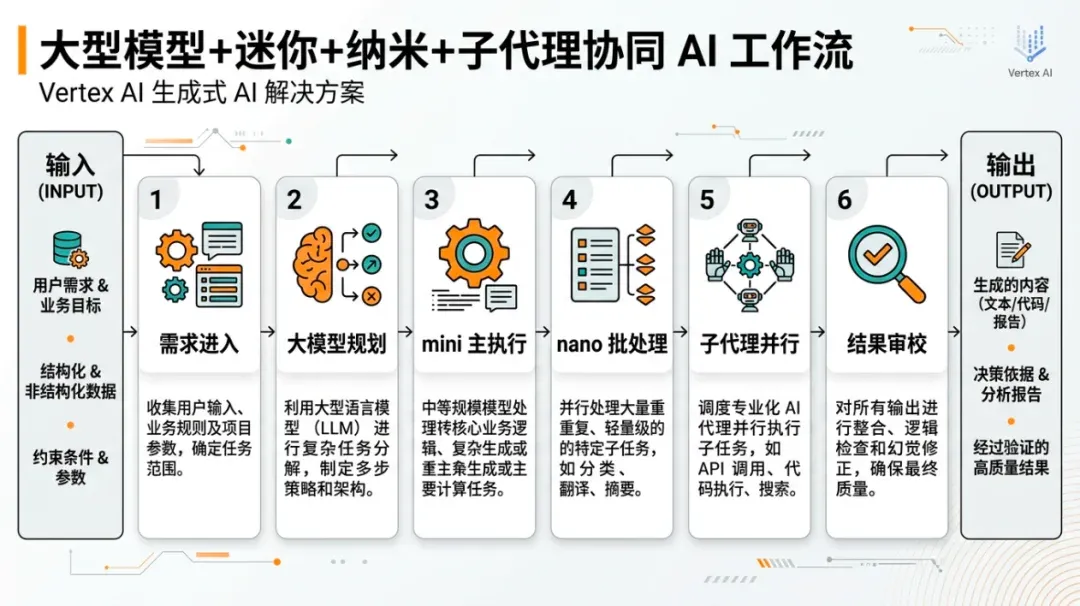
流程图用于解释方法论执行路径。
03
果叔观点
我对这条新闻的核心判断是:OpenAI 这次发的不是两个小模型,而是一套新的默认工作方法。
未来一段时间里,真正有优势的团队,不会是“最早用上 GPT-5.4 mini 的团队”,而是最早学会把模型分层使用、并把产品成本结构一起改掉的团队。
1) 不要再用“单模型思维”设计 AI 产品
以后越来越多成熟系统会是多层模型结构:
• 一个大模型做方向判断
• 一个 mini 模型做主要执行
• 一个 nano 模型做大批量支撑任务
如果你还在按照“一条请求对应一个模型”的方式设计产品,成本、响应速度和扩展性很快都会吃亏。
2) 先把最贵的那 20% 调用找出来
对大多数已经上线 AI 能力的团队来说,我建议第一步不是追新,而是回去看账单。
找出:
• 调用量最大但复杂度其实不高的环节
• 经常被大模型处理、但并不需要最强推理的环节
• 可以拆成主任务 + 子任务的流程
这三个地方,最适合优先试 mini / nano。很多团队的 AI 成本,未必需要靠“压缩调用次数”来解决,靠“把任务分对模型”就能明显降下来。
3) 这波变化会继续利好 agent / coding / automation
mini / nano 最直接受益的三类场景,我觉得是:
• Coding agents
• Automation workflows
• Multimodal batch pipelines
因为这些场景都有一个共同点:任务多、步骤细、并行子任务多、对单位调用成本敏感。 换句话说,越像“工业流程”的 AI 系统,越会吃到这次价格与性能重排的红利。
04
其他重点新闻速览
1) Google DeepMind 发布 AGI 认知测量框架,并同步开 Kaggle Hackathon
Google DeepMind 在 2026 年 3 月 17 日提出了一套衡量 AGI 进展的认知框架,并同步启动 Kaggle hackathon,邀请研究社区围绕 10 类关键认知能力建立评估方法。官方还给出了三阶段 evaluation protocol,并设立 20 万美元奖金池。
这件事的重要性在于:AI 产业开始更认真地争夺“怎么衡量 AGI”这件事,而不只是争夺“谁先声称更接近 AGI”。
来源:
2) Google 扩展 Personal Intelligence,免费用户开始能在 AI Mode / Gemini / Chrome 里用到
Google 在 2026 年 3 月 17 日宣布,Personal Intelligence 正在美国扩展到 AI Mode in Search、Gemini app 和 Gemini in Chrome,并开始向 free-tier users 推进。它允许系统结合 Gmail、Google Photos 等个人上下文提供更定制化的回答。
这意味着 Google 正在把“更懂你”的能力,从实验功能进一步推向更大用户面,AI 助手的竞争也会越来越像“谁更会用你的个人上下文”。
来源:
https://blog.google/products-and-platforms/products/search/personal-intelligence-expansion/
3) Mistral Small 4 试图把推理、多模态和 agentic coding 合在同一个模型里
Mistral 在 2026 年 3 月 16 日推出 Mistral Small 4。根据 Mistral 官方口径,它把 Magistral 的推理、Pixtral 的多模态和 Devstral 的 agentic coding 能力整合进一个模型中。Simon Willison 引述其规格时提到,这是一款 119B 参数、Apache 2 许可的模型。
这条新闻值得注意,因为它代表另一条和 OpenAI 不同的路线:不是继续切更细价格带,而是试图把“多种能力统一到一个开源权重模型里”。
来源:
https://simonwillison.net/2026/Mar/16/mistral-small-4/
4) Python 3.15 JIT 在 macOS AArch64 上实现约 11%-12% 性能提升
Ken Jin 关于 Python 3.15 JIT 的更新显示,在 macOS AArch64 上,CPython JIT 已经实现约 11%-12% 的性能提升,在 x86_64 Linux 上也有 5%-6% 左右的改善。
这条消息对 AI 开发者的价值不只是“Python 更快了”,而是底层运行时的持续进步会慢慢改善推理工具链、数据管道与 agent 执行层的整体效率。
来源:
https://simonwillison.net/2026/Mar/17/ken-jin/
5) Django 社区开始更明确地讨论 LLM 生成贡献的伦理边界
围绕 Tim Schilling 的文章,Simon Willison摘录了一段很有代表性的观点:如果贡献者自己并不理解 ticket、解决方案或 PR feedback,那么这种 LLM 使用正在伤害 Django 社区本身。
这件事的重要性不在于“开源反对 AI”,而在于越来越多社区开始讨论:AI 辅助可以接受,但不能把“人真正理解问题”这件事直接外包掉。
来源:
https://simonwillison.net/2026/Mar/17/tim-schilling/
6) 子代理模式继续升温,开始变成 coding agent 的默认架构部件
Simon Willison 的 subagents 指南把这个模式讲得很直白:主 agent 派出拥有全新上下文窗口的子代理,去做代码探索、并行任务、专业化检查,再把结果汇总回来。与此同时,OpenAI Codex 官方文档也已经把 subagents 写成正式工作流能力。
这说明 2026 年的 agent 竞争,已经不只是比“单个模型回答得多聪明”,而是在比谁能把复杂任务拆开、并行、收敛得更高效。
来源(Simon Willison):
https://simonwillison.net/guides/agentic-engineering-patterns/subagents/
补充来源(OpenAI Codex 文档):
https://developers.openai.com/codex/subagents
05
趋势与机会
1) 未来最值钱的能力,是“模型调度能力”,不是“单模型崇拜”
模型越来越像不同规格的计算资源。谁能把任务拆对、分对、调度对,谁就能在成本、延迟和结果之间拿到更优解。
2) 小模型会继续吃掉“以前必须上大模型”的工作
mini / nano 这次已经把分界线往前推了一步。接下来,很多原本需要中档甚至大模型兜底的工作,会先被更便宜、更快的小模型接管,只把最难的那部分留给大模型。
3) Agent 工作流会从“会不会做”变成“划不划算做”
当子代理、并行任务、批量多模态理解的单位成本继续下降,团队会越来越愿意把 agent 化真正接进产品主流程里。未来讨论 agent,不会只问“它能不能做”,而是会更频繁地问“它做得值不值、规模跑不跑得动”。

