Digital Strategy Review | 2026
SerpApi 反击 Google DMCA 诉讼:公开 SERP 抓取权之争升级 | 果叔SEO日报
文 / 果叔 · 阅读时间 / 10 Min
写在前面
如果你把 SEO 当成“调标题、堆关键词、抢排名”,今天这条新闻会让你瞬间清醒:真正决定行业边界的,往往不是算法细节,而是规则本身——尤其是“谁能合法、稳定地拿到 SERP 数据”。
过去十几年,SERP 抓取、排名监控、竞品分析、舆情追踪,背后都依赖一个默认前提:搜索结果是公开可见的,第三方可以在一定边界内自动化访问并做分析。但现在,Google 与 SerpApi 的 DMCA 诉讼把这个前提推到了法庭上。
这场官司的胜负,可能直接影响:你的监测工具是否还能用、你对排名波动的解释是否还有依据、以及“SEO 工具行业”未来的合规成本会不会陡增。
要知道果叔我自己也是SerpAPI 的用户,我的SEO 智能体非常依赖这个货来获取SERP 进行分析。以及据我所知很多外贸开发类的自动化工具也是依靠这个东西。
01
今日头版重点新闻
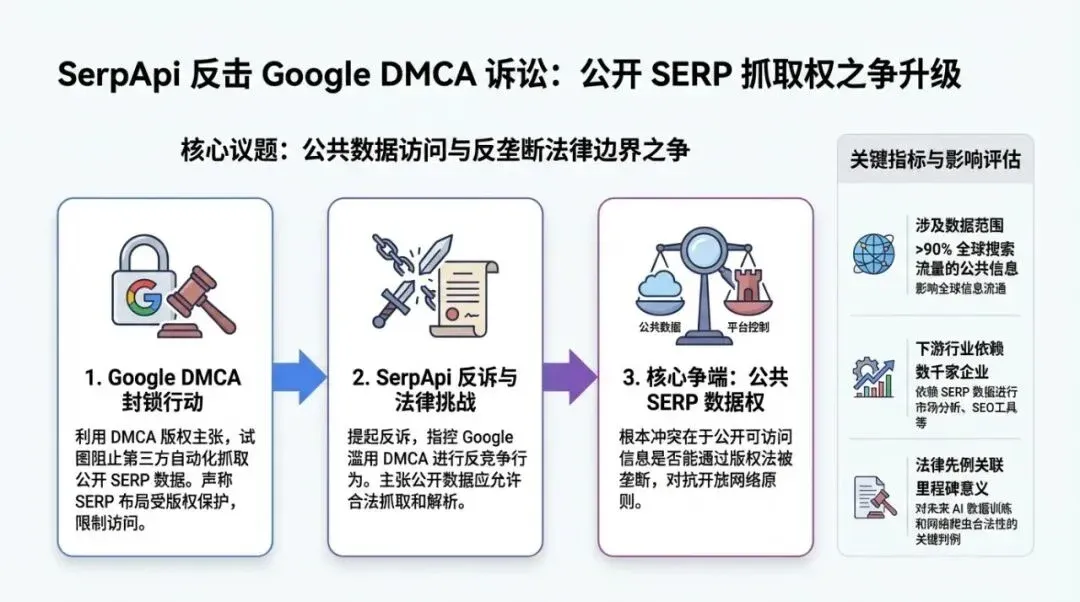
SerpApi 在 2026 年 2 月 20 日向法院提交动议,要求驳回 Google 提起的联邦 DMCA 诉讼。核心主张是:
-
•Google 并不是其 SERP 页面所展示信息的版权持有人
因此缺乏以 DMCA 为基础主张损害的法律地位。
-
•
SerpApi 认为其访问的是“任何普通浏览器都能访问的公开网页”,并未进行 DMCA 意义上的“规避”(circumvention)。
-
•
SerpApi 还引用了 Lexmark v. Static Control(2014)关于诉讼资格/利益范围(zone of interests)的框架,认为 Google 所称的损害(基础设施成本、广告收入损失等)并非 DMCA 要保护的利益。
根据报道,相关听证会日期被提及为 2026 年 5 月 19 日。对 SEO 行业而言,这不只是两家公司之间的纠纷,而是一次“平台能否借版权法控制公开搜索结果访问权”的边界测试。
交叉信源(至少两家独立行业媒体):
-
•
Search Engine Journal:https://www.searchenginejournal.com/serpapi-challenges-googles-right-to-sue-over-serp-scraping/568084/
-
•
Search Engine Land:https://searchengineland.com/serpapi-motion-dismiss-google-scraping-lawsuit-469889
-
•
The Verge(更面向大众的解读视角):https://www.theverge.com/news/602811/serpapi-google-lawsuit-scraping-search-results
02
头版解读:为什么这件事更重要
这起诉讼之所以值得放到头版,不是因为它离“日常优化”很近,而是因为它可能改变我们赖以生存的地基:SERP 数据的可获得性与可持续性。
1) SEO 工具行业的“隐形公共基础设施”,可能被重新定价
排名监控、SERP 特征追踪(精选摘要、AI 概览、视频/本地包等)、竞品对标、品牌占位——这些动作的共同输入是:稳定、可规模化的 SERP 数据。
如果平台能够以 DMCA 的“反规避”逻辑去限制对公开页面的自动化访问,那对第三方而言,风险会从“技术对抗(反爬)”升级为“法律不确定性”。这意味着:
-
•
工具商可能需要更重的合规与法务投入,成本上升会传导到订阅价格。
-
•
数据源可能从“自己抓”转向“买授权/买聚合”,行业集中度提升。
-
•
中小团队会更依赖平台提供的官方数据接口(Search Console、Merchant Center 等),而这些接口的粒度与时效性未必满足所有需求。
一句话:当 SERP 数据不再“默认可得”,SEO 的很多能力会被迫回到更慢、更贵、更不确定的状态。
2) 这也是 AI 时代的平台战略:控制“可观察性”就控制生态位
今天的 Google 不只是一家搜索公司,它还在把搜索变成更强的“回答系统”和“交易系统”。当搜索结果页逐渐承载更多 AI 生成内容、更多闭环交互(不点出站也能完成信息获取/下单),平台更在意的不只是反爬本身,而是生态参与者对外部可观察性的掌控。
对平台来说,SERP 数据一旦被大规模抓取:
-
•
第三方可以更快训练“更懂 SERP 的模型”、更快复刻产品体验;
-
•
广告与自然结果的商业结构更容易被量化与对比;
-
•
竞争情报的门槛被拉低。
所以我们看到的不是单点冲突,而是一条长期趋势:平台将逐步把“数据可见性”从技术问题变成规则问题。
3) 对站长/品牌方,最现实的变化是:别把“单一监测口径”当真相
无论官司结果如何,行业已经被迫面对一个事实:依赖单一渠道、单一工具、单一抓取口径的监测体系,在未来会越来越脆弱。
你需要的是“多维口径”的可观察性:
-
•
来自 Search Console 的真实点击与展示(哪怕有延迟)。
-
•
来自站内日志与分析的用户行为(停留、转化、路径)。
-
•
来自多搜索引擎/多市场的对比(Google/Bing/地区性搜索)。
-
•
来自 AI 结果的“被引用/被推荐”监测(AIO、ChatGPT、Perplexity 等)。
当 SERP 变得更难抓,你越需要把“第一方数据”与“多源对照”做强。
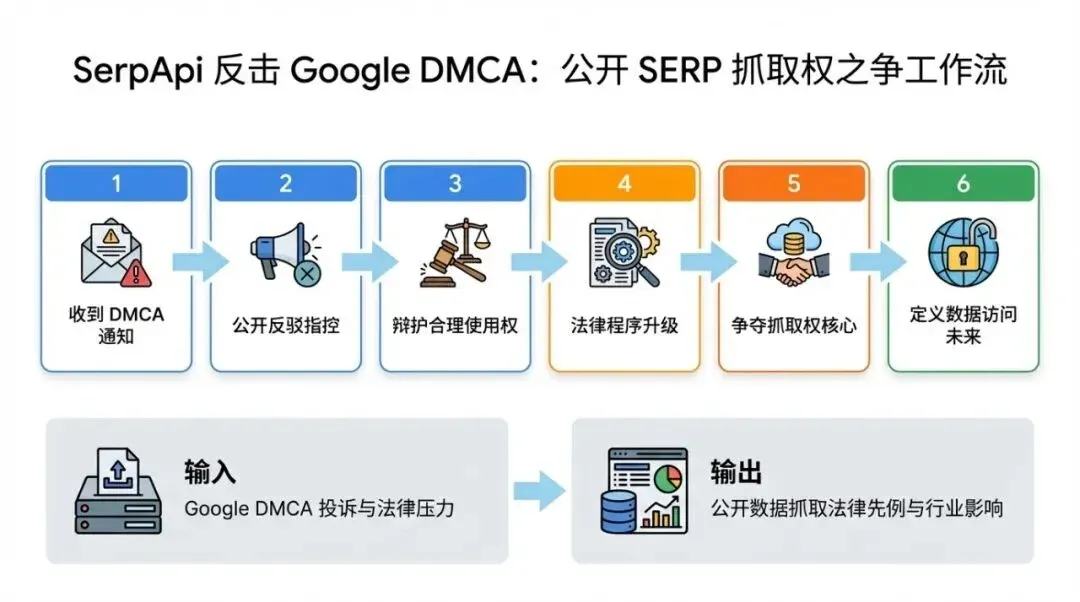
流程图用于解释方法论执行路径。
03
果叔观点
我建议把这场官司当成一次“压力测试”,用来检验你团队的 SEO 体系是不是过度依赖外部可抓取数据。
给到三个可执行的应对动作(不等判决,今天就能做):
动作一:把关键指标从“排名”迁移到“业务可解释”
-
•
给每个核心页面定义 2-3 个能解释业务的指标:搜索点击、有效到达、转化、线索质量等。
-
•
排名可以看,但不要当作唯一因果解释;尤其在 AI 概览与 Discover 流量波动下,排名与点击的关系更不稳定。
动作二:工具与数据源做“去单点”设计
-
•
同类监测至少保留两家数据源(或两套口径):避免一家工具/一种抓取方式失效就全黑。
-
•
与工具商明确 SLA:数据异常时的告警、补偿机制、历史数据回填策略。
动作三:提前做“AI 可见性”与“内容可引用性”的工程化
SEO 正在从“让页面被检索到”转向“让内容被回答系统引用与选择”。建议你把 GEO/AEO 当成工程问题来做:
-
•
为核心主题建立结构化实体与属性(Schema、FAQ、产品/服务清单)。
-
•
让内容更容易被机器拆解与复用:定义、对比、步骤、表格、可验证数据点。
-
•
建立“引用监测”:记录 AI 结果里是否出现品牌/页面,以及出现在哪些 query 上。
你越早把这些做成体系,未来越不怕外部规则变化。

用数据图解释关键对比和结论。
04
其他重点新闻速览
Google Discover 2026 年 2 月更新:可见性更集中,本地与 X 内容上升
早期第三方跟踪数据显示,美国 Discover 结果中的独立域名数量减少,但覆盖话题在扩展;同时本地内容与 X.com 帖子在部分视图中占比上升。这类变化会直接影响依赖 Discover 的媒体与内容站。
-
•
GEO(生成式引擎优化)从概念走向方法:优化目标从“排名”变成“被引用”
多家行业内容把 GEO 作为独立学科系统化整理,强调对 AI 爬虫可读性、结构化数据、品牌可信度与“可被回答”的内容形态。
-
•
https://www.searchenginejournal.com/geo-generative-engine-optimization/568078/
Google Search Console 页面索引报告出现历史数据缺失
多方报道指出,GSC 的页面索引报告缺少 12 月 15 日之前的数据,这更像是 Google 的报告/展示故障而非站点本身问题。遇到这类情况,建议以趋势判断为主,避免单点截图误判。
-
•
-
•
https://www.seroundtable.com/google-search-console-page-indexing-report-missing-data-40976.html
Google 本地商家资料出现 AI 生成的服务列表与更强的虚假评论治理
本地面板正在被 AI “半自动化”填充:服务列表、描述与治理动作更频繁。对本地商家而言,信息一致性与评论合规的重要性继续上升。
-
•
https://www.seroundtable.com/google-business-profiles-ai-generated-services-40970
-
•
Semrush 推出面向 ChatGPT / AI Overviews 的内容改写工具
SEO 工具商开始把“可被 AI 引用”作为可销售能力,内容生产将更强调结构、可验证性与覆盖面,而不只是关键词密度。
-
•
https://www.semrush.com/blog/optimize-content-for-llms-with-semrush/
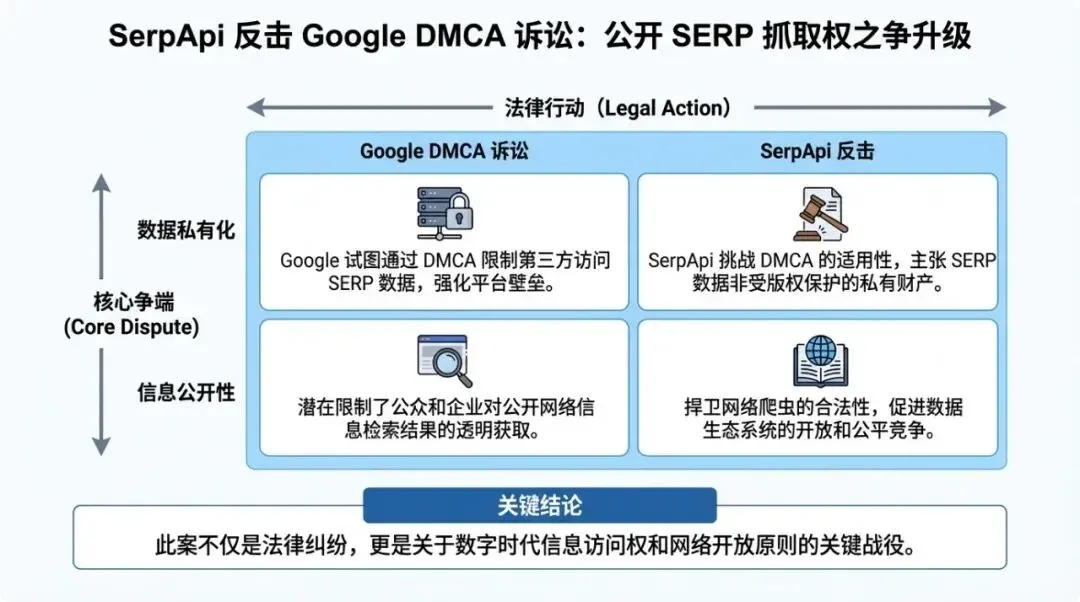
矩阵图用于说明适用边界和策略选择。
05
趋势与机会
1) SEO 的重心从“排名工程”迁移到“可见性工程”:你需要监测的不只是 10 条蓝链,而是 AI 概览、Discover、视频/本地、以及回答系统的引用。
2) 数据合规与可观察性成为护城河:当抓取越来越难、规则越来越多,拥有稳定数据口径与第一方数据的团队会跑得更稳。
3) 内容策略会更像产品设计:为了被 AI 选择,你需要更清晰的定义、对比、步骤、证据链与实体结构;这会倒逼内容团队与产品/研发更紧密协作。
4) 电商与交易会被“AI 入口”重写:当平台推动更闭环的购物体验(信息获取到交易),品牌方的机会在于:把商品/服务信息结构化、把口碑与可信度做成“机器可读”。

