
写在前面
满大街都是推荐独立开发者白嫖Vercel 的文章,直到有一天你账单炸了,知道哭了!
最近我看到一个关于 Vercel 爆账单的分析,核心结论大致分成四条:公开 API 容易被爬虫刷爆、重计算别留在 Serverless、大文件别通过应用转发、Preview 部署要防止被爬。
这个总结的整体方向是对的,所以它会让很多独立开发者觉得“问题已经看明白了”。可当我把 Vercel 官方文档顺手翻了一遍之后,发现这里面至少有两处非常容易误导人:
第一处,很多人脑子里还是老版本的 Serverless 心智,觉得它主要是“按运行时长收费”。今天的 Vercel 已经把 Functions 放进了 Fluid Compute 口径里,官方给出的核心计费维度是 Active CPU、Provisioned Memory 和 Invocations。你当然还是会因为重计算花更多钱,但如果只盯着“运行 5 秒”这个单一维度,很容易漏掉真正该优化的点。
第二处,很多人会把 Preview Deployment 的问题理解成“怕被搜索引擎收录”。更准确的说法是:Vercel 的 Preview Deployments 默认就带 X-Robots-Tag: noindex。真正危险的地方在于,你把一个没有访问保护的预览环境暴露在公网了,别人就能访问,它照样会消耗你的资源。noindex 解决的是搜索收录,不解决访问控制。
所以这篇文章,我不想写成一篇泛泛的“省钱技巧合集”。我更想把这件事讲透一点:很多 SaaS 并不是被 Vercel 的价格打败的,很多时候,是被自己对平台边界的误解打败的。
01
01 先把计费逻辑看懂:Vercel 更像按行为计费的平台
很多独立开发者第一次用 Vercel,心里其实是把它当作“更高级的托管平台”来理解的:项目上线,流量来了,最多比传统 VPS 贵一点。
这个理解会制造很大的错觉。
Vercel 的官方文档和 Pricing 页面已经写得很明确了。今天的 Functions 在 Fluid Compute 下,核心看的是三件事:
01 你的代码到底被调用了多少次,也就是 Invocations
02 你的代码真正消耗了多少 CPU 时间,也就是 Active CPU
03 你的函数在运行过程中占了多少内存,也就是 Provisioned Memory
再往外一层,你还有 Edge Requests、Fast Data Transfer / Fast Origin Transfer、Blob 的请求和数据传输这些成本面。
这意味着什么?
这意味着 Vercel 从来都不只是“托管费”。它更像一套按行为计费的全球应用平台。你的每一次未命中缓存、每一次公开 API 被触发、每一次把大文件绕进应用服务器、每一次让同一份内容反复回源,最后都会变成 usage。
这也是为什么很多人会有一种“我明明还没赚到钱,账单怎么先长起来了”的错觉。因为你以为自己在为用户增长付费,实际你付掉的,很大一部分是设计失误的成本。
更重要的是,Vercel 官方自己也在 Pricing 页面里明确提醒过两件事:
01 如果函数响应被缓存,它就不会运行,也不会产生 Function Invocation 或对应的持续时间成本
02 新团队默认就有一笔可自定义的 on-demand usage budget,达到 100% 之后还可以配置 hard limit 自动暂停项目
这两个提醒合在一起,其实已经把问题说穿了:真正危险的团队,往往不是流量太大,而是缓存策略和 spend guardrail 都没配。
顺手补一句很关键的细节:缓存不会让成本“彻底归零”。按官方口径,命中缓存之后最贵的那段函数计算会被压下去,但 Edge Requests 这类资源仍然可能继续累计,静态资源和文件传输也还是会按自己的口径计费。所以缓存的价值,是把最容易失控的计算成本压下来,而不是让平台突然变成免费午餐。
02
02 坑一:公开 API 裸奔,外加默认不缓存
这是最常见,也最容易把人打懵的一类账单。
很多 SaaS 项目天然会暴露一些路径:
• /api/generate
• /api/convert
• /api/download
• /api/search
• /api/rss
只要这些入口是公开可访问的,它们就不只会被真实用户访问,还会被各种 bot、crawler、脚本和“顺手扫一遍”的自动化工具访问。
Vercel 在 DDoS 相关文档里说得很直接:被 Firewall 拦下的攻击流量不会收费,但在自动缓解之前已经成功服务的请求,以及没有被识别为 DDoS 的 bot / crawler 流量,仍然会计入 usage。
这句话的含义非常重。
它告诉你,平台层的自动防护当然重要,但你不能把预算安全完全寄托在“Vercel 会帮我挡住”。如果你的公开接口本身没有节流、没有鉴权、没有配额、没有缓存,那么它就会成为最容易被反复试探的成本入口。
这里还有一个经常被忽略的放大器:默认不缓存。
Vercel 的官方 Cache-Control 文档写得很清楚,默认值是:
Cache-Control: public, max-age=0, must-revalidate也就是说,浏览器和 CDN 默认都不会替你把这类响应长期缓存下来。
如果你的接口响应对所有访问者都一样,或者至少在几分钟、几小时内都没有必要实时重算,那你继续使用默认值,其实就是把每一次访问都当成一次真实计算。
对于这类接口,我建议至少做三层防线:
第一层:边缘层拦住明显异常流量
当你发现访问模式突然异常时,先把 Attack Challenge Mode 打开,必要时配合 Vercel WAF 的自定义规则做 challenge 或 deny。官方说明里提到,Googlebot 这样的搜索引擎爬虫会被自动放行,所以正常 SEO 不会因为这个开关直接受伤。
第二层:应用层做真正的配额控制
如果接口是高价值能力,例如生成、下载、转码、摘要、搜索,最好给它加上用户级、IP 级或 API key 级的限流。Upstash 的 sliding window 这一类方案就很适合放到这里。它不是为了“优雅”,它是为了防止你的产品还没长大,先被人免费当基础设施用了。
第三层:能缓存的响应,就别重复算
如果结果对大多数人相同,直接上 CDN 缓存。官方推荐给同内容服务端响应的 header 里,s-maxage 是非常关键的:
Cache-Control: max-age=0, s-maxage=86400, stale-while-revalidate=60这一类 header 的意义很朴素:先把重复访问吃在边缘层,再让后台异步刷新。
Vercel 还在 2025 年引入了 Request Collapsing。它能把同一路径同一区域的并发未命中折叠成一次调用,避免出现“同一个热页面一瞬间被打穿 1000 次函数调用”的情况。这个功能很有价值,但前提仍然是这条路由可缓存。你如果让一切都保持默认 no-cache,它再聪明也只能帮你挡住部分并发浪费,挡不住持续性的重复回源。
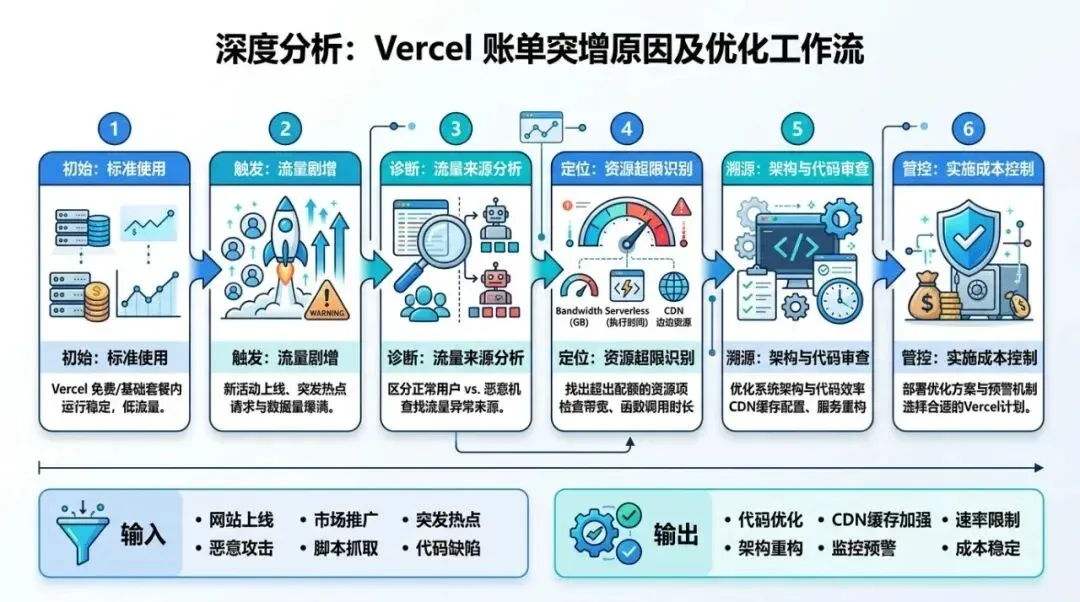
流程图用于解释方法论执行路径。
03
03 坑二:把重计算任务长期留在 Functions 里
第二类账单,通常不是被“坏流量”刷出来的,而是被你自己架构出来的。
很多独立开发者会把下面这些任务直接塞进 app/api/* 或 route handlers:
• AI 长文本生成
• PDF 解析
• 图片处理
• 音视频转码
• 大批量抓取
• 报告生成
开发阶段这么做很自然,因为它快,路径也短,产品能先跑起来。
问题在于,一旦你把这个形态长期保留下来,Functions 就会开始承担它不擅长的那部分算力工作。官方文档已经很明确:Functions 的 usage 会随 Active CPU、内存和调用量增长。换句话说,只要你把重活留在这里,访问一放大,成本就会一起放大。
我自己的判断是:
Vercel 很适合做 Web 入口、渲染层、轻量业务逻辑、边缘路由和协作体验。它也能承接一部分动态逻辑。但如果你已经明确知道某个任务是高 CPU、高内存、长链路、可排队、可异步的,那继续把它留在 Functions 里,多半是在用最贵的方式做最不该做的事。
这类任务更适合的落点通常是:
• Cloud Run / 容器服务
• 队列 + Worker
• 独立后端服务
• 专用转码 / 解析节点
也就是说,Vercel 负责接请求、鉴权、排队、展示状态,真正重的那段计算交给更像“算力层”的地方。
这不是因为 Vercel 不好,而是因为每个平台都有边界。你让它做超出边界的事,最后付出的不是抽象代价,而是具体账单。
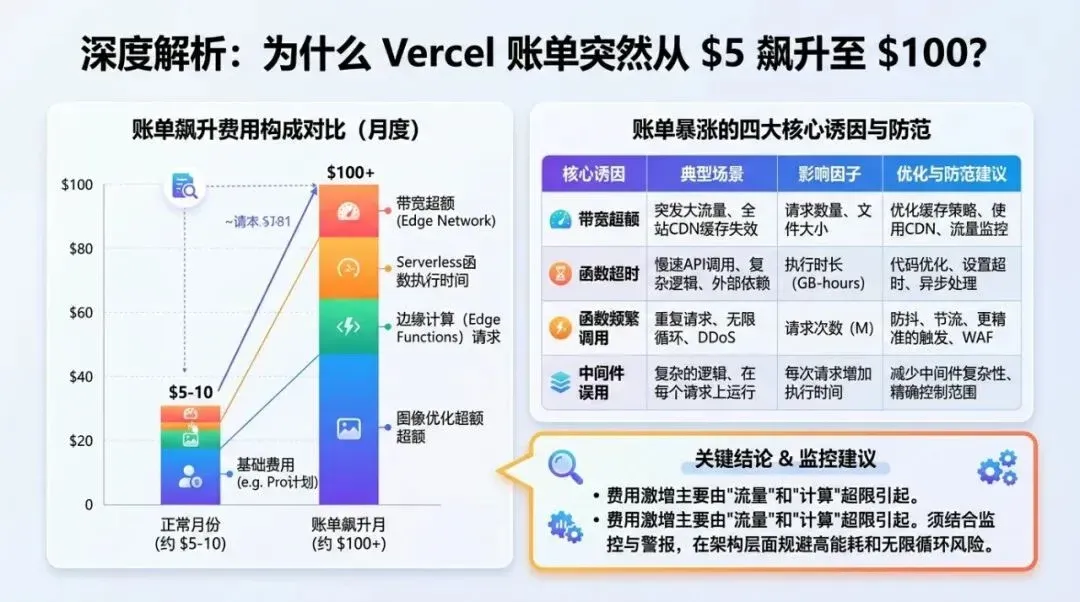
用数据图解释关键对比和结论。
04
04 坑三:上传下载都先经过你的应用
第三类账单,特别常见于“文件型 SaaS”。
你可能提供:
• 图片上传
• 视频上传
• ZIP 下载
• PDF 导出
• 模板文件分发
很多项目一开始会这样设计:
User -> Next.js / API Route -> 存储服务 User <- Next.js / API Route <- 存储服务这样写的优点是路径直观,权限也好控制。缺点也非常直接:所有文件都要先经过你的应用一遍。
Vercel Blob 的官方文档其实已经把更优解给出来了。Client Uploads 的设计就是让文件直接从浏览器上传到 Blob,中间不经过你的服务器;对于大于 4.5 MB 的文件,官方还明确建议使用 client uploads。
更关键的是价格文档里的那句提醒:使用 Client Uploads 时,上传不产生 data transfer charges;如果是 Server Uploads,由你的 Vercel 应用先接收文件,再上传到 Blob,就会产生 Fast Data Transfer 成本。
这背后的工程原则其实很统一:
01 权限在你的应用里签发
02 文件在对象存储里直传直下
03 你的 Web 层只负责生成 token、signed URL、元数据和状态
如果你不用 Vercel Blob,也一样可以走这个思路。AWS S3 官方文档里的 presigned URL,就是经典方案:给用户一个有时限的上传或下载权限,文件本体直接去对象存储,不需要先穿过你的应用。
我更推荐的链路像这样:
User -> Next.js / API Gateway -> Signed URL / Upload Token -> Blob / S3 / R2这样做的结果很现实:
• 你的应用服务器不承担大文件中转
• 大文件流量和应用计算分开
• 成本结构更容易看清
• 出问题时也更容易定位
很多人嘴上说“要把文件放对象存储”,但链路还是老的。真正省钱的关键,从来都不只是存储位置,而是传输路径到底有没有绕进你的应用。
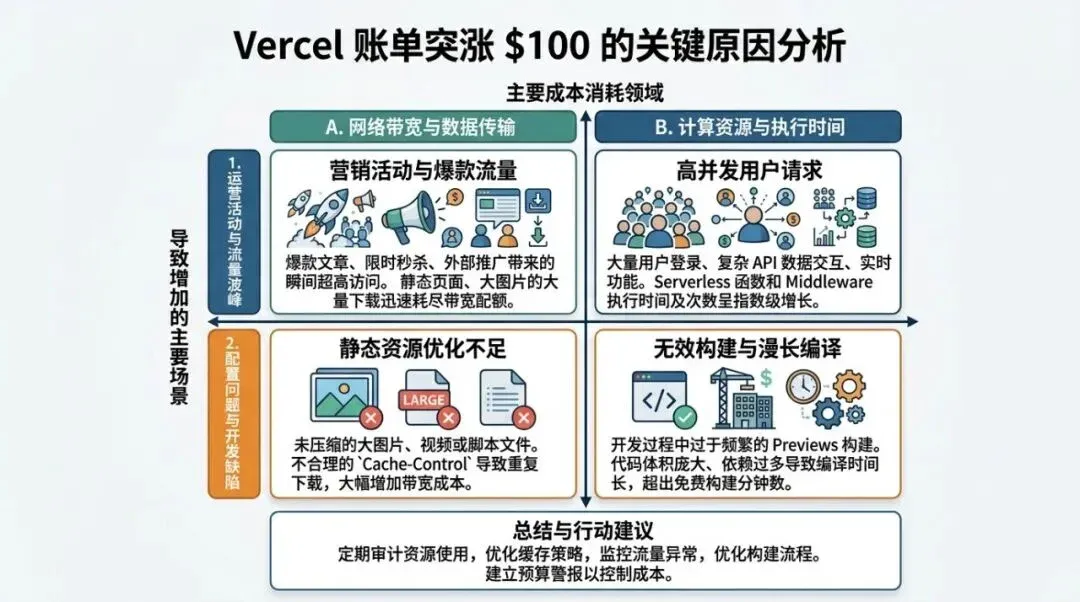
矩阵图用于说明适用边界和策略选择。
05
05 坑四:把 Preview 的 noindex 误当成安全措施
这一条,是我这次翻文档时最想专门拎出来说的一条。
很多建议会告诉你:Preview Deployment 容易被搜索引擎抓到,所以要在 vercel.json 里补 X-Robots-Tag: noindex。
问题在于,Vercel 的官方知识库已经写明了:Preview Deployments 默认就不会被搜索引擎索引,因为它们会自动带上 X-Robots-Tag: noindex。
你如果按“给 preview 补 noindex”这条建议去做,当然也没什么坏处,但你会产生一种错觉:问题已经解决了。
实际上,真正要问的问题是:
这个 preview URL 有没有被访问保护?
如果一个预览环境公开暴露,它就依然可能被人访问、被自动化工具访问、被分享出去、被拿来测试边界。它即便不被搜索引擎收录,也照样可能消耗你的资源。
更细一点的坑是:官方还专门说明了,如果你把自定义域名绑定到非生产分支,X-Robots-Tag: noindex 这层默认保护并不会自动带上。
所以这一块真正该补的,不是“SEO 小技巧”,而是访问控制。
Vercel 在 Deployment Protection 文档里给出的方向非常明确:
• Hobby 计划就可以用 Vercel Authentication + Standard Protection
• 它保护的是 preview deployments 和 deployment URLs
• 再往上,你还可以配 password protection、trusted IP 等手段
也就是说,noindex 处理的是“要不要进搜索结果”,Deployment Protection 处理的是“谁能进来”。这两者根本不是一回事。
如果你最近正好遇到异常访问,顺手再加一层 Attack Challenge Mode,你会更安心一些;但真正长期有用的,仍然是把公开暴露面收小。
06
06 我更推荐的一套低风险架构
如果你现在做的是典型 SaaS,我更推荐你把整条链路拆成四层:
用户 / Bot / Crawler ↓ WAF / Rate Limit / Attack Challenge ↓ CDN Cache / Next.js Web Layer ↓ Queue / Worker / 独立后端 ↓ Blob / S3 / R2 等对象存储这个结构的优点非常明确:
第一,Vercel 负责它最擅长的部分
也就是路由、渲染、边缘分发、产品协作和开发体验。
第二,重计算被挪到了更适合的地方
需要长时间跑的任务,进入队列或独立 worker。你不会再把“页面入口”和“算力工地”绑在一起。
第三,文件流量和应用流量被拆开了
上传下载交给对象存储,应用只发 token 或 presigned URL。你的 Web 层终于不用给大文件做搬运工。
第四,成本观察会清楚很多
你一看 usage,就知道这部分成本是页面访问、是函数计算、是对象传输,还是图片优化、Blob、Edge Request。账单不再是一团雾。
很多团队真正缺的不是“更便宜的平台”,而是一条成本结构足够清楚的链路。你只有把钱花在什么地方看明白了,后面才谈得上优化。
07
07 现在就能做的 7 个动作
如果你已经在用 Vercel,我建议你今天就把下面这 7 件事做掉:
01 跑一遍 vercel usage,把当前账期最贵的资源项看清楚
02 把 on-demand usage budget 和 hard limit 配好,别让 runaway spend 靠运气发现
03 盘点所有公开 API,给高价值接口补限流、鉴权和配额
04 检查哪些响应其实可以缓存,别继续吃默认的 max-age=0, must-revalidate
05 把 AI 生成、转码、解析、抓取这类重任务列出来,逐个判断是否应该迁出 Functions
06 把上传下载链路改成 client uploads 或 presigned URL,减少应用中转
07 给 preview deployments 和 deployment URLs 补上 Deployment Protection,别再把 noindex 当成安全措施
如果你问我,独立开发者在 Vercel 上最该有的一个认知是什么?
我的答案是:
Vercel 最危险的成本,从来都不是“突然来了很多用户”,而是“你让一堆本不该计费的重复动作,一直在默默计费”。
真正该省的,也从来不只是每个月那 20 美元的订阅费。真正该省的是那些本可以被缓存、限流、分流、直传和隔离掉的无谓消耗。
当你把这些边界补齐之后,Vercel 依旧会是一套很好用的产品;只不过这一次,你用的是平台,而不是在被平台教育。
