内容字数:约 2600 字 (仅统计中文与英文单词)
预计阅读时间:约 12 分钟
最后更新日期:2025年09月07日
这篇文章适合你吗?
👉 如果你每天需要处理来自不同渠道的、格式混乱的 Excel 和 CSV 文件。
👉 如果你想进行更深度的用户行为或广告归因分析,但受限于表格工具的功能。
👉 如果你想为 AI 提供高质量的“燃料”,让它为你产生更精准的洞察。
本文核心脉络
1. 思维转变:为什么 AI 时代的营销人必须超越 Excel?
2. 装备升级:认识你的新“数据厨房”—— Python, Jupyter & Pandas。
3. Vibe Coding 实战:指挥 AI 构建一个多渠道广告数据归因看板。
给营销和运营人的Vibe Coding 实战手册(二):从“Excel”到“Python”,成为AI的数据投喂师
引言:AI 的“粮食危机”
你好,我是果叔。在上一篇文章中,我们成功体验了作为 AI“指挥官”的快感,让 Claude Code 帮我们自动构建了一个周报工具。但很快,你会遇到一个新瓶颈:AI 再聪明,如果你喂给它的“粮食”——也就是数据——是低质量的、分散的、混乱的,那么它产出的也只能是“垃圾洞察”。这就是 AI 时代的“粮食危机”。
我们日常工作中,数据往往散落在各个角落:Google Ads 的 CSV 报告、Meta 后台的 Excel 导出、公司 CRM 系统的数据……我们习惯于在 Excel 或 Google Sheets 里手动整合,但当数据量变大、逻辑变复杂时,表格工具的瓶颈就显而易见了。今天,我们将进行一次彻底的装备升级,学习如何使用 Python 这个强大的工具,为你强大的 AI 模型,准备一顿高质量的“数据盛宴”。
第一章:思维转变——为什么 AI 时代的营销人必须超越 Excel?
Excel 和 Google Sheets 是伟大的工具,但它们的设计初衷是为人服务的“电子表格”,而非为机器服务的“结构化数据容器”。当我们进入 AI 时代,继续依赖它们处理复杂数据,就像试图用一把瑞士军刀去伐木,迟早会力不从心。
- 处理能力的瓶颈:
一个超过10万行数据的 Excel 文件,足以让大部分电脑陷入卡顿。而对于 Python 来说,处理百万甚至千万行数据都是家常便饭。
- 可复用性的瓶颈:
你在表格里做的每一次手动操作——筛选、排序、VLOOKUP——都难以被记录和复用。而 Python 脚本本身就是一套可重复执行、可分享的标准化流程。
- 连接性的瓶颈:
表格工具难以直接与数据库、API 等现代数据源对话。而 Python 则是连接万物的“万能胶水”。
因此,学习 Python 进行数据处理,其核心目的不是让你成为数据分析师,而是让你具备为 AI 高效准备高质量、结构化数据的能力。你将从一个被动的“表格使用者”,转变为一个主动的“数据架构师”。
第二章:装备升级——认识你的新“数据厨房”
在开始烹饪“数据大餐”之前,我们需要先熟悉一下我们的新厨房和厨具。
Python:你的“厨房”
Python 是一种功能强大且语法简洁的编程语言。在数据科学领域,它是无可争议的王者。我们将使用它作为我们所有数据处理任务的基础。(安装过程在第一篇已涵盖)
Jupyter Notebook:你的“砧板与料理台”
Jupyter Notebook 是一个交互式的编程环境,它允许你将代码、文本和图表组合在一个文档中。它最大的好处是,你可以写一小段代码,立刻运行并看到结果,这对于数据探索和调试来说极其友好。
Pandas:你的“万能厨刀”
Pandas 是 Python 中最重要的数据分析库。它提供了一种名为 DataFrame 的强大数据结构,你可以把它想象成一个超级加强版的 Excel 表格,能让你用几行代码就完成复杂的数据清洗、转换、合并和分析。
安装 Jupyter 和 Pandas
打开你的终端,运行以下命令即可完成安装:
pip install notebook pandas
安装完成后,在终端输入 jupyter notebook,你的浏览器就会自动打开一个本地服务页面,你的“数据厨房”就准备就绪了!
第三章:Vibe Coding 实战——指挥 AI 构建多渠道广告归因看板
现在,让我们进入实战。假设你是一家电商公司的营销负责人,你手上有三份数据文件:
- google_ads.csv:
包含日期、广告花费、点击量。
- meta_ads.xlsx:
包含日期、广告花费、曝光量。
- sales_data.csv:
包含日期、订单ID、销售额、以及来源渠道(UTM Source)。
你的目标是:将这三份数据整合起来,按天计算每个渠道的总花费和总收入,从而得到一个初步的 ROAS (广告支出回报率) 看板。我们将继续使用 Claude Code,一次性下达指令,让它为我们生成完整的 Jupyter Notebook 文件。
核心工作流:下达总指令 → AI 生成 Notebook → 审查与运行
在你的项目文件夹中(确保三份数据文件已放在其中),打开终端,启动 claude-code,然后输入我们的总指令。
最终指令 (The One Prompt):
“你好,请帮我创建一个名为 marketing_dashboard.ipynb 的 Jupyter Notebook 文件,用于整合和分析多渠道的营销数据。
核心需求如下:
1. 读取数据:
a. 使用 Pandas 读取 google_ads.csv。
b. 读取 meta_ads.xlsx。
c. 读取 sales_data.csv。
2. 数据预处理:
a. 统一所有文件的日期列格式为 YYYY-MM-DD。
b. 为 Google Ads 数据增加一列 ‘channel’,值为 ‘google’。
c. 为 Meta Ads 数据增加一列 ‘channel’,值为 ‘meta’。
3. 数据整合:
a. 将 Google 和 Meta 的广告数据合并为一个广告花费总表 ads_cost。
b. 按天和渠道,聚合计算 ads_cost 表的总花费。
c. 按天和来源渠道 (utm_source),聚合计算 sales_data 表的总销售额。
d. 将处理后的广告花费数据和销售数据,按日期进行合并,生成最终的看板数据 dashboard_data。
4. 计算与输出:
a. 在 dashboard_data 中计算 ROAS(销售额 / 广告花费)。
b. 将最终的 dashboard_data 导出一个名为 final_dashboard.csv 的文件。
交付要求: 1. 整个 Notebook 需要有清晰的 Markdown 单元格来解释每一步的操作。 2. 代码单元格需要有简洁的中文注释。”
按下回车,Claude Code 就会为你生成一个结构清晰、代码完整、注释详尽的 .ipynb 文件。你只需要在终端运行 jupyter notebook,在打开的页面中找到并点击这个文件,就可以看到一个已经为你写好的完整数据处理流程。你所要做的,就是从上到下,逐个单元格点击“运行”,亲眼见证数据被一步步清洗、整合,并最终生成你想要的结果。
下面放一个我通过一份 Claude Code 做的一个Facebook 广告分析的案例:
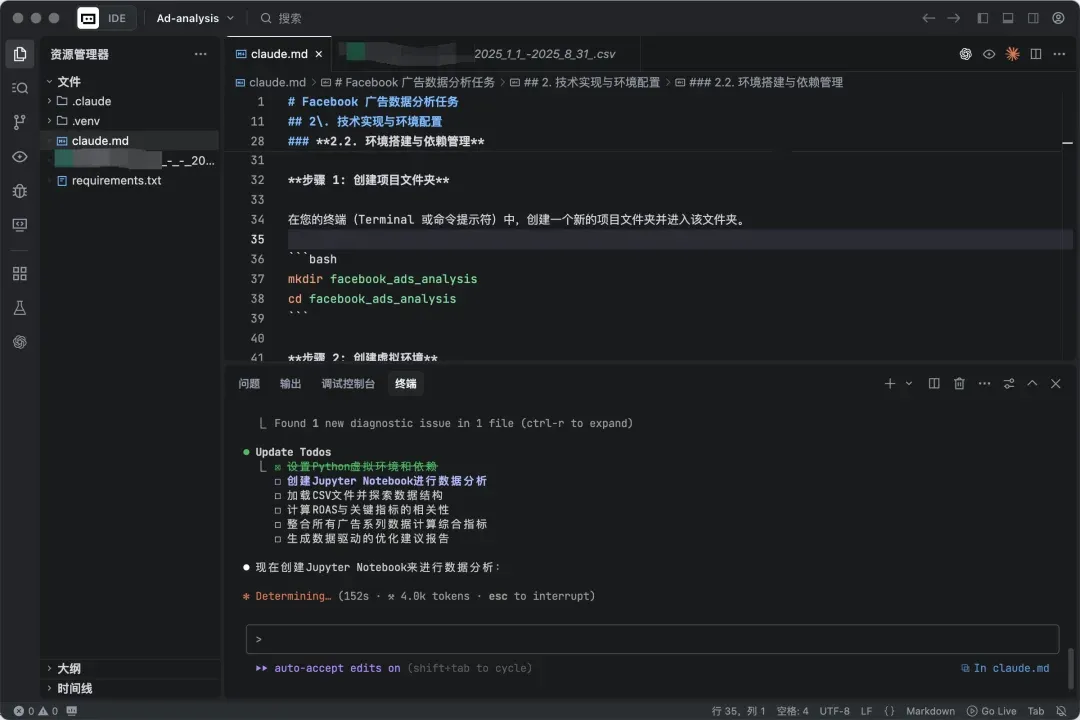
我只需要把我的需求做好claude.md 文件,并让它根据claude.md 开始执行任务,中间点回车确认就可以,如果开了全自动模式就可以直接去睡觉或者干点别的事了。
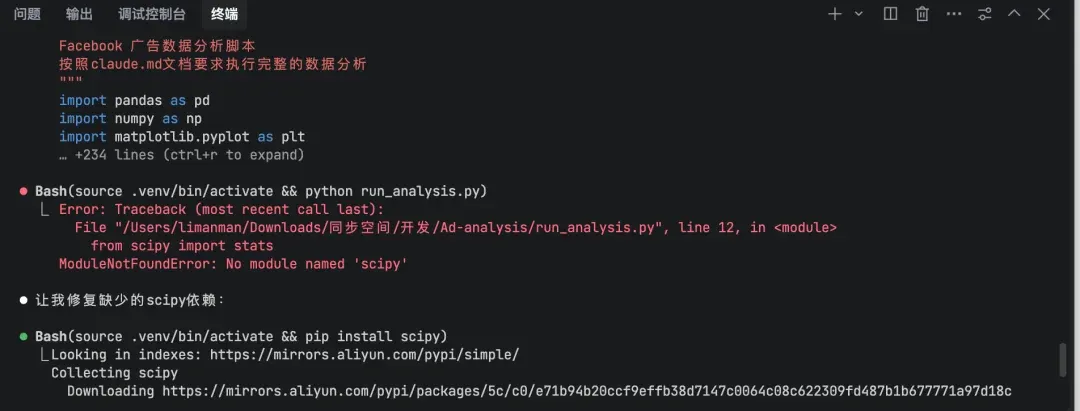
遇到问题它会自己去修复。
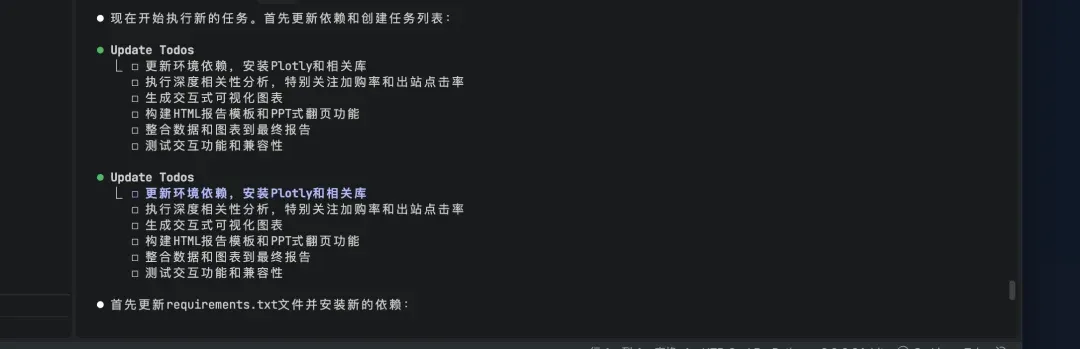
进一步迭代需求
最终你会得到一个,文科生基本无缘的数据指标相关性分析研究可视化数据报表+PPT
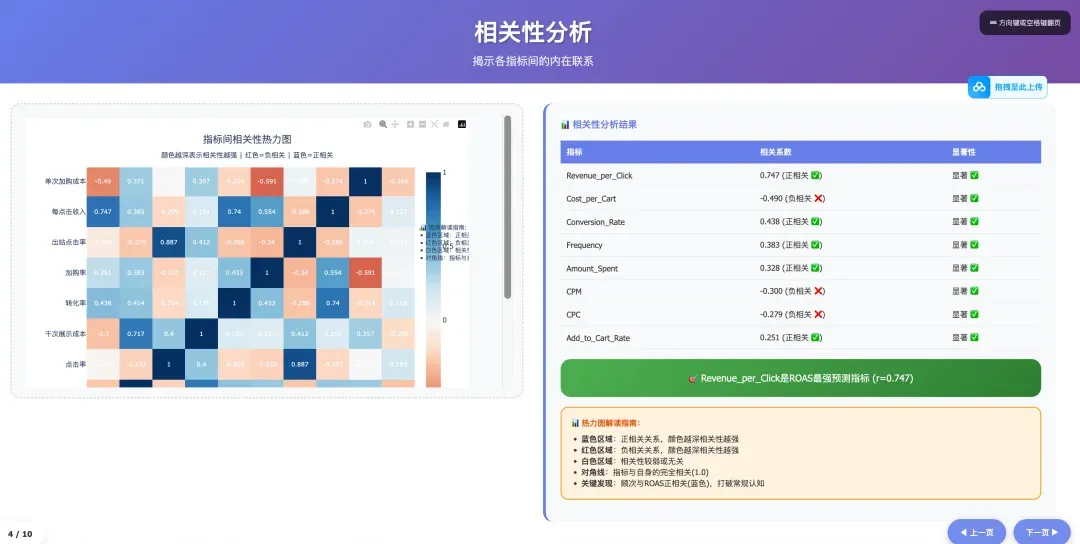
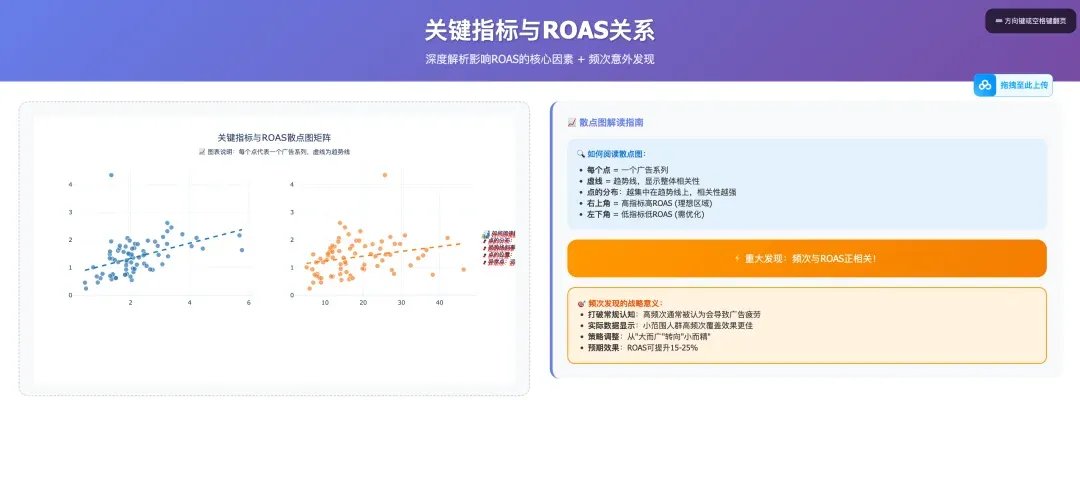
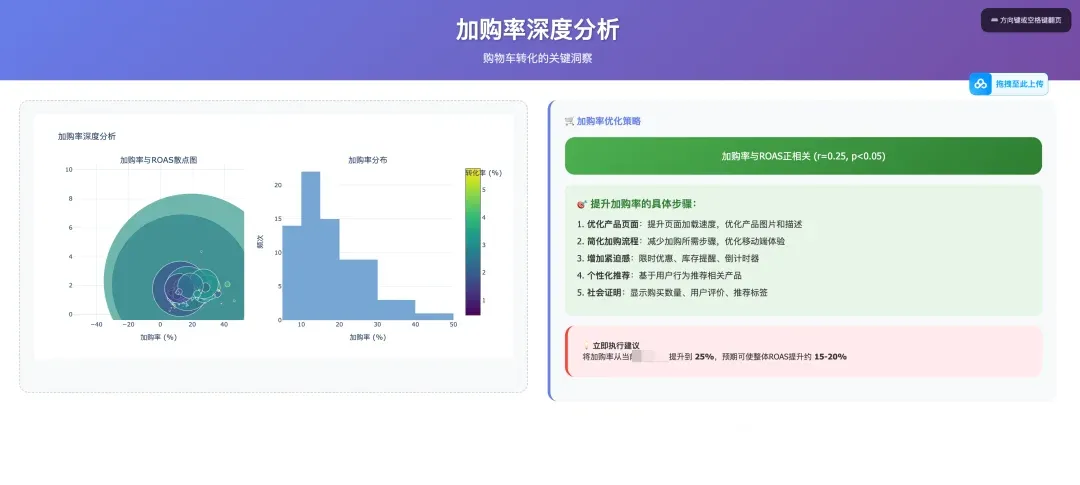
对于我这份claude.md 文档,你可以关注果叔,并在后台回复“claude数据分析” 获得。你只需要把你的Facebook 广告数据+这个claude.md 放在一个目录下,丢给claude code ,并告诉他“按照claude.md来执行任务”,你就可以获得和我同款的分析报表。
结语与系列预告
今天,你已经完成了从“表格操作员”到“数据流程设计师”的身份转变。你学会了使用 Python 和 Pandas 这套强大的工具,将杂乱无章的原始数据,加工成了结构清晰、可供分析的“半成品”。这不仅是一项数据处理技能,更是你作为 AI“指挥官”的核心能力之一。
觉得这篇文章为你打开了数据世界的新大门?点个「👍」,「转发」给更多还在被表格困扰的伙伴吧!
🌌 数据是 AI 的氧气,而你,是那个制氧的人。
